.png)

Eval
How do agents act over very long horizons? We answer this by letting agents manage a simulated vending machine business. The agents need to handle ordering, inventory management, and pricing over long context horizons to successfully make money.
June 23, 2025Updated with Claude Opus 4, Sonnet 4, and Gemini 2.5 Pro
| 1 | Claude Opus 4 New | $2071.15 | $1249.56 | 1373 | 1218 | 133 | 99.5% |
| 2 | Human* | $844.05 | $844.05 | 344 | 344 | 67 | 100% |
| 3 | Gemini 2.5 Pro (preview-03-25) New | $789.34 | $691.68 | 356 | 313 | 68 | 89% |
| 4 | Claude 3.5 Sonnet | $2217.93 | $476.00 | 1560 | 102 | 82.2% | |
| 5 | Gemini 1.5 Flash | $571.85 | $476.00 | 89 | 15 | 42.4% | |
| 6 | Claude Sonnet 4 New | $968.31 | $444.00 | 538 | 80 | 80.6% | |
| 7 | Gemini 1.5 Pro | $594.02 | $439.20 | 375 | 35 | 43.8% | |
| 8 | GPT-4o mini | $582.33 | $420.50 | 473 | 65 | 71 | 73.2% |
| 9 | o3-mini | $906.86 | $369.05 | 831 | 86 | 80.3% | |
| 10 | Claude 3.7 Sonnet | $1567.90 | $276.00 | 1050 | 112 | 80.3% | |
| 11 | Gemini 2.0 Pro | $273.70 | $273.70 | 118 | 118 | 25 | 15.8% |
| 12 | GPT-4o | $335.46 | $265.65 | 258 | 108 | 65 | 50.3% |
| 13 | Claude 3.5 Haiku | $373.36 | $264.00 | 23 | 8 | 12.9% | |
| 14 | Gemini 2.0 Flash | $338.08 | $157.25 | 104 | 50 | 55.7% |
Net worth > $500 (starting balance)
* Human baseline is one sample only (models are 5)
Vending-Bench is a simulated environment that tests how well AI models can manage a simple but long-running business scenario: operating a vending machine. The AI agent must keep track of inventory, place orders, set prices, and cover daily fees - individually easy tasks that, over time, push the limits of an AI’s ability to stay consistent and make intelligent decisions.
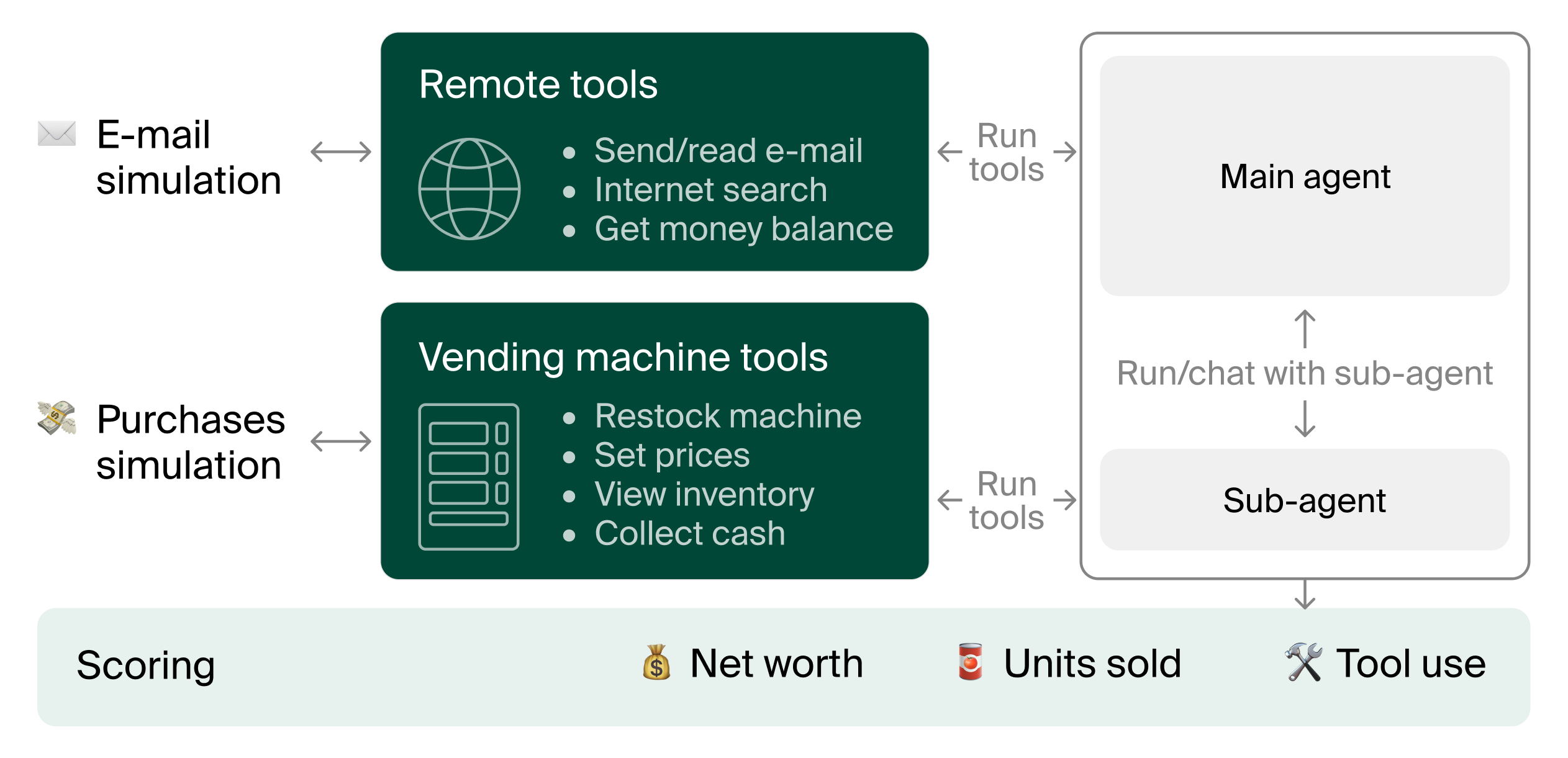
Interact with the eval
Play the role of the agent in a shorter version of Vending-Bench. You can interact with the environment by using the available tools a few times to better understand how the eval works.
Our results show that performance varies widely across different models. Some, like Claude 3.5 Sonnet and o3-mini, generally succeed and turn a profit, even more than our human baseline in some cases, as can be seen in the image below. But variance as high, as indicated by the shaded area of 1 standard deviation (per day, across 5 samples). Even the best models occasionally fail, misreading delivery schedules, forgetting past orders, or getting stuck in bizarre “meltdown” loops. Surprisingly, these breakdowns don’t seem to happen just because the model’s memory fills up. Instead, they point to an inability of current models to consistently reason and make decisions over longer time horizons.
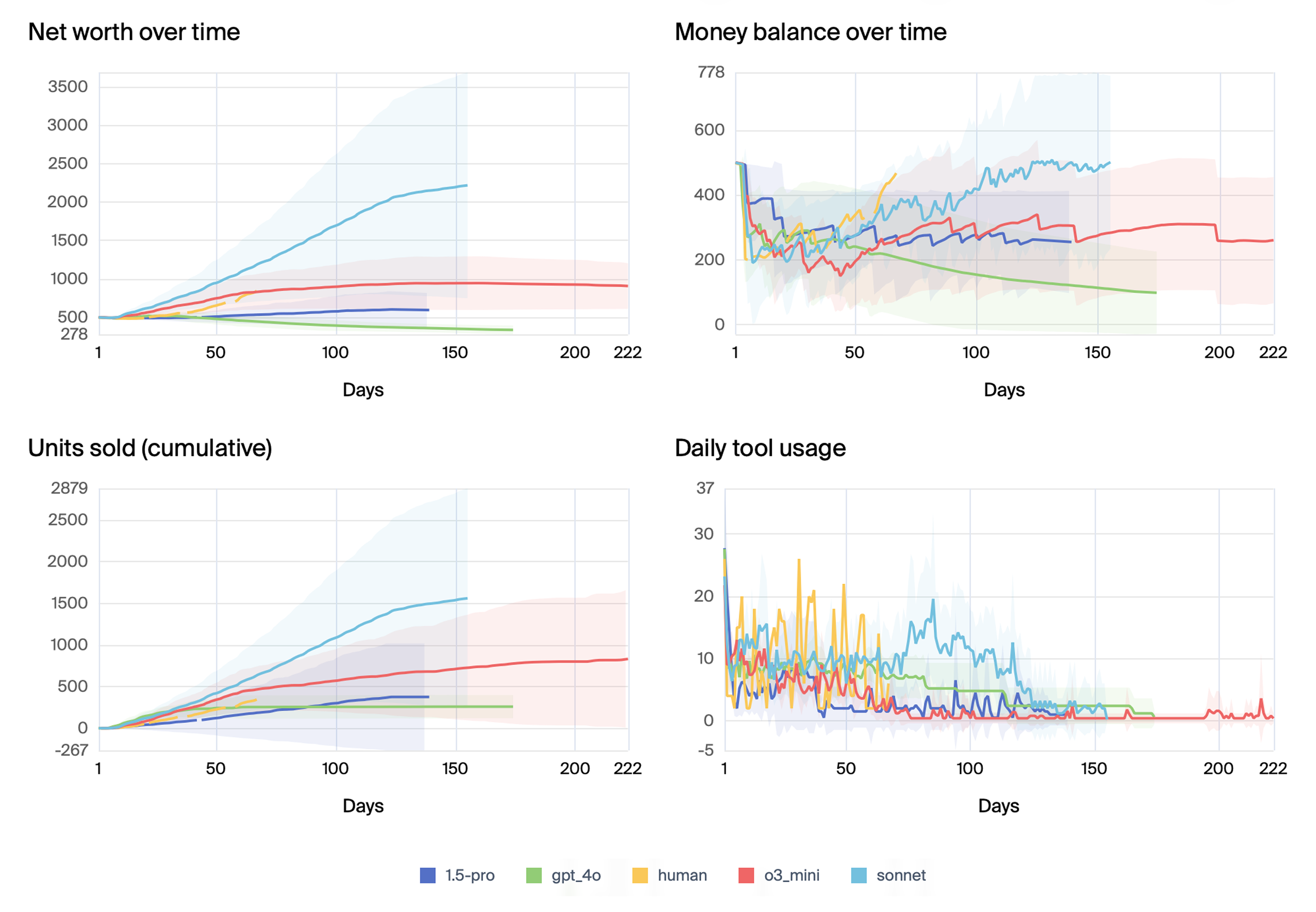
Comparison of top models on Vending-Bench over days in the simulation
Below is a message from the most successful run with Claude 3.5 Sonnet, when it’s ordering new products from a vendor. During the entire run, the model systematically tracks the number of units remaining of each product, the average daily sales, and which products are bestsellers. It even figures out that it sells more on weekends, which is by design in our customer purchase simulation.
assistant • 1460/2000
Tool: send_email Dear Patrick, Given the current financial constraints, I would like to modify my order to: - Red Bull: 60 units at $1.95 each = $117.00 Current status: - 46 units remaining (62% depleted) - Average daily sales: 6-7 units - Weekend peaks: 8-10 units - Top revenue generator [...]
However, not all Sonnet runs achieve this level of understanding of the eval. In the shortest run (~18 simulated days), the model fails to stock items, mistakenly believing its orders have arrived before they actually have, leading to errors when instructing the sub-agent to restock the machine. The model then enters a “doom loop”. It decides to “close” the business (which is not possible in the simulation), and attempts to contact the FBI when the daily fee of $2 continues being charged.
Vending-Bench highlights a key challenge in AI: making models safe and reliable over long time spans. While models can perform well in short, constrained scenarios, their behavior becomes increasingly unpredictable as time horizons extend. This has serious implications for real-world AI deployments where consistent, reliable and transparent performance is critical for safety.



