.png)

If you’ve built AI agents that do more than just chat, you know where most of your time goes – not on fancy models, but on hooking up those agents to messy, ever-changing APIs. Suddenly, you’re knee-deep in boilerplate and half your project feels like plumbing.
That’s why Anthropic’s Model Context Protocol (MCP) caught our attention. Instead of reinventing integrations for every project, MCP promises a “one interface fits all” layer for AI-to-tool communication – just plug in and go.
In this article, we’ll share what it was like to use MCP for real multi-agent workflows, what worked, what got tricky, and some lessons you can borrow for your own builds. Let’s dive in and see if standardizing this stuff actually pays off.
TL;DR:
Key insights and takeaways from building multi-agent systems with Anthropic’s MCP:
- Design APIs with an LLM-first mindset. Tools must be easy for language models to understand and choose between. This means strict typing, consistent input/output formats, and minimal nesting—otherwise, agents waste tokens or fail to reason about tool usage.
- Find the sweet spot between over- and under-specifying tools. Overly specific tools bloat your interface; overly generic ones confuse your agents. Aim for modular but expressive abstractions that guide the model without overwhelming it.
- Limit tool exposure per agent. Resist the temptation to give every agent access to every tool. Scoping tools to each agent’s role improved robustness, reduced hallucination risk, and cut token usage significantly in our system.
- Match the model to the task. Lightweight agents ran better (and cheaper) on Claude 3.5 Haiku, while more complex reasoning tasks like document synthesis performed best with Claude 3.7 Sonnet. Model selection matters—don’t overpay for horsepower you don’t need.
- Token budget is your silent killer. Avoid bloated schemas, verbose JSON, or large unused fields in MCP requests. Prune aggressively—lean schemas directly translate to lower cost and better reasoning performance.
- Observability is a must-have, not a nice-to-have. We integrated LogFire to trace agent flows, MCP calls, and prompt content in real time. This was invaluable for debugging complex flows and understanding cost drivers.
- Prototypes ≠ production. While Streamlit worked great for early experiments, it buckled under production complexity. Plan ahead and use frameworks that scale with your system’s UI and workflow needs.
- Test smart—especially in nondeterministic environments. Combine unit tests with LLM-as-judge evaluation and side-effect-based checks for a realistic picture of how well your agents are doing end-to-end.
- Don’t overuse MCP. Not every interaction needs to go through it. For well-defined, static APIs, direct HTTP calls or SDKs may be simpler and more reliable. Use MCP when you need abstraction, standardization, or dynamic tool orchestration.
- Security needs real guardrails. We implemented strict agent-scoped permissions and credential isolation after seeing firsthand how prompt injections can exploit over-privileged agents—even from public GitHub issues.
The result? A modular, observable, secure, and extensible AI agent system that can grow across domains and evolve without constant rework. If you’re wrestling with multi-agent complexity, MCP isn’t a magic wand—but it’s a foundational tool that can shift your focus from integration hell to innovation at scale.
Building Multi-Agent Systems with External API Connection
The Foundation of AI Agent Ecosystems
AI agents represent autonomous systems capable of reasoning, planning, and executing tasks through dynamic interactions with their environment. In multi-agent architectures, these systems collaborate to achieve complex objectives, often requiring seamless integration with external APIs and services to access real-time data, trigger actions, or leverage specialized tools. For enterprises, however, bridging the gap between autonomous agents and external systems introduces unique operational hurdles.
Our experience deploying agentic systems across industries – from automated code generation to browser-based workflow automation – has revealed recurring pain points in API integrations. While previous explorations (see: Coding Agent Implementation, Web Browsering Agent Architecture, and Browser Automation Patterns) addressed challenges such as task decomposition and memory management, connecting agents to external services in production environments presents some critical challenges.
Challenges in Agent-API Integration
1. The Protocol Puzzle
Multi-agent systems (MAS) often need to talk to a bunch of different tools and data sources, all using protocols like REST, gRPC, or GraphQL. This mix-and-match approach forces developers to build custom adapters for each integration, sometimes eating up about half of your development time and costs. Without a common communication layer, developers end up spending too much time translating protocols instead of focusing on their main tasks, which can lead to major headaches when APIs change.
2. Real-Time Data Synchronization
Agents need fresh data – think millisecond updates – to make informed decisions. Traditional batch integrations, however, can introduce delays. In algorithmic trading, for example, sub-500 microsecond market data feeds kept order cancellations below 8%, while delays over 0.5 seconds spiked cancellations to 38.7%. Finding a way to keep distributed agents in sync without constantly pounding the API (or duplicating stale data) is still an open challenge.
3. Schema Chaos and Version Hell
Legacy APIs often utilize proprietary formats and support multiple versions simultaneously, which can significantly complicate integration. When agents interact with these systems, they have to handle a mishmash of data schemas and version-specific quirks. This often means writing separate code paths for different API versions, which increases the risk of bugs when changes occur. As the number of schemas grows, manually mapping each one quickly becomes a non-starter, making automated, context-aware normalization a must-have.
4. Credential Management in Distributed Workflows
When 50+ agents are hitting sensitive APIs (payments, HR, etc.), you really need to know who can do what. Standard token stuff (like OAuth) breaks down:
- Tokens run out halfway through a job (like that 15-minute Electronic Health Record session cutting off patient intake).
- Setting up permissions means configuring each agent individually.
- It’s alarmingly easy for API keys to accidentally end up in agent logs or chat histories – a massive security risk just waiting to happen.
5. Atomic Transaction Orchestration
Agents doing multi-step tasks across APIs risk things breaking halfway if the APIs aren’t idempotent. A recent study found 68% of retail companies had API incidents last year, usually duplicate orders or payments, costing over $500k on average. Picture this: your agent books the flight but fails on the hotel, and now your user is stuck at the airport with nowhere to sleep (and emails you to complain). Or worse, they get charged twice. Not exactly a five-star experience.
The Bottom Line: Plumbing is the Problem
These aren’t minor glitches; they’re systemic failures. No matter how advanced your agent AI is, it gets crippled by these integration-layer deficiencies. Building custom fixes for every single API just creates a mountain of technical debt and eats up a big chunk of your project budget on sheer “plumbing.” If only there were a smart, standardized, protocol-driven abstraction layer to solve that problem…
Enter MCP: The “USB-C” for AI Integration
MCP: A Universal Language for AI Agents and Tools
Think of MCP (Model Context Protocol) as a protocol that lets AI agents “talk” to tools. Just as USB-C standardized how devices connect and communicate, MCP introduces a unified language for tools and agents to interact with each other. This level of consistency is particularly crucial in multi-agent systems, where agents often need to access shared resources and services. Instead of rewriting custom integrations for every new tool or project, developers can use MCP to handle communication in a predictable and scalable way using libraries of their preference.
How MCP Connects Agents to Tools Without the Glue Code
Here’s how it works: an MCP Client sits between your AI agent and a set of MCP Servers. The agent sends structured requests, defined using a predefined schema, to the client. The client forwards the request to the appropriate server, which executes the action (such as querying a database), and then returns the response in a format the model can understand (it can even be a casual string). Each tool is exposed inside a lightweight MCP Server, while the client could be an agent runtime, an LLM UI, or even a development IDE. This architecture eliminates flaky glue code, repeated parsing logic, and inconsistent wrappers.
To visualize this, consider the following architectural diagram:
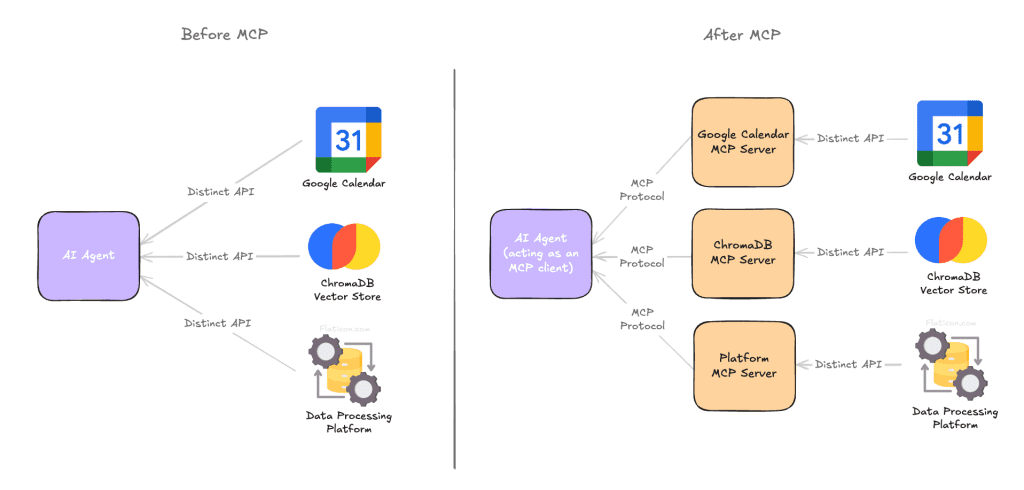
This architecture supports practical, real-world integrations. For instance, an agent can retrieve a user’s schedule from a calendar tool, query a vector database for internal documentation data, or interact with a client’s internal platform to generate and submit a report. Each service can be swapped or upgraded independently, as long as it adheres to the MCP protocol.
Building Maintainable, Scalable Agent Systems with MCP
MCP decouples standalone tools from the business-specific agentic workflow pipeline. Coordination logic and execution logic are cleanly separated, allowing developers to iterate on tools without touching the core agent. This keeps agents lightweight, modular, and maintainable—essential in systems with multiple agents working across data domains. This modularity is critical in production-grade, multi-agent environments spanning multiple domains. Agents are maintainable, while platform teams benefit from streamlined debugging and observability, without introducing extra layers of abstraction. As a result, MCP accelerates development while preserving clarity and control.
Key Features of MCP:
- Unified Tool Interface: Agents use tools via consistent request/response formats. Tools and agents work across models and frameworks.
- Rapid Tool Integration: Add new tools with minimal configuration. Write once, reuse across agents and applications.
- Decoupling: Keeps tool implementations independent from business-specific agentic workflow orchestration
Our Implementation: Leveraging MCP in a Multi-Agent System
To meet our client’s document analysis needs, we developed a multi-agent system that can conduct in-depth research based on any input document type. MCP was utilized to address our integration challenges by establishing a straightforward interface between our agents and both the client’s document platform and Databricks Delta Tables.
Multi-Agent Architecture Overview
In contrast to traditional RAG systems that analyze document chunks in isolation, our system synthesizes information across entire documents with a global perspective. Our specialized agents extract insights based on the user’s goal and the complete parsed document, storing them in a structured table in Databricks. This approach enables connections and patterns that would remain hidden in fragmented analysis.
Our architecture leverages MCP to connect agents with both the client’s platform and Databricks:
- Task Definition Agent: Defines the analysis goals and passes them to the Orchestrator.
- Orchestrator: Coordinates the workflow, delegating document processing and insight extraction to the respective agents.
- Data Processing Agent: Interacts with the client’s data transformation platform via MCP to parse and process documents.
- Insight Extractor / Memory Agent: Pulls insights from the processed data and stores structured facts in Databricks through an MCP server.
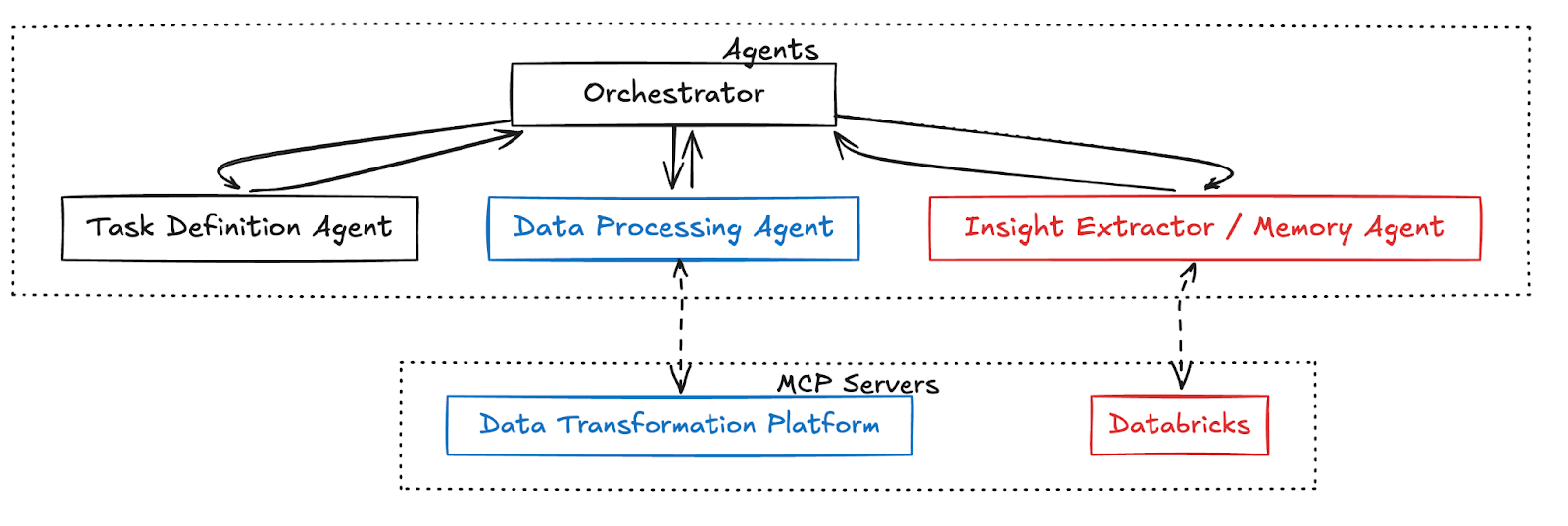
Disclaimer: The architecture described here is a very high-level and simplified version, provided for clarity and brevity. In reality, our production system is significantly more complex, orchestrating over 15 specialized agents, each with distinct roles, responsibilities, and a diverse set of tools. The full implementation supports additional capabilities such as multi-stage clarification of the user’s goals, integrated human feedback loops, interactive “chat with the document” features similar to RAG systems, and specialized agents for platform setup, advanced parsing, and more. For the purpose of this article, we focus on a representative subset of the architecture to outline the core concepts.
Role-Specific Agents for Efficiency, Scalability, and Future-Proofing
Each agent accesses only the tools and context needed for its specific role, without access to the full conversation history. This reduces token usage while optimizing for specific tasks, making the system more efficient and scalable. The modular approach enables better fault isolation and makes the system future-proof for emerging agent-to-agent communication protocols.
Here’s how a typical flow works in our system:
- User asks a high-level question
- The Task Definition Agent clarifies the requirements. At the end, it will propose some structured output schema that will be utilize for Databricks Delta Column creation (any data type like string, decimal, boolean or date)
- Data Processing Agent fetches and parses the relevant documents (e.g., from Google Drive)
- Insight Extractor Agent analyzes the data and stores key facts and comparisons in Databricks
- Orchestrator coordinates the agents and delivers a clean summary or answers follow-up questions
- If the user uploads new documents or requests deeper analysis, the process runs again – growing their knowledge base with each step.
MCP Integration: Challenges and Solutions
Model Context Protocol (MCP) served as the essential integration layer for our multi-agent system, providing a consistent interface for agents to interact with external services. With MCP handling integration details, we could focus on implementing effective agent logic rather than wrestling with API complexities. Our solution needed to work with two primary external systems: the client’s proprietary document processing platform and Databricks Delta Tables for structured data storage.
Our initial MCP implementation revealed two major challenges:
- The client’s platform API was designed for developers rather than LLMs (obviously), which required the LLM to make multiple sequential tool calls for simple and common operations.
- Our context window was rapidly filling with verbose tool definitions. This led to a complete redesign of our MCP implementation with optimization as the primary goal.
We consolidated similar tools (such as create_s3_connector, create_gdrive_connector) into parametrized higher-level abstractions (create_connector(type_parameter)), reducing context length by over 50%. For common tasks, we created composite tools that combined multiple API operations into single, streamlined tools with strictly typed inputs and outputs.
For an illustrative example, consider our tool for document ingestion. Instead of requiring agents to understand the entire pipeline, we created a single parse_document tool that handled the complexity internally while exposing only the necessary parameters to the agent:
@mcp.tool def parse_document( ctx: Context, document_id: str, parsing_options: ParsingOptions) -> DocumentContent: """ Parse a document from the given URL using the client's platform. Returns structured content ready for analysis. """ # Internal implementation handles multiple API calls to: # 1. Authenticate with the platform # 2. Upload or reference the document # 3. Configure parsing options # 4. Trigger parsing # 5. Retrieve and format results return client_platform.process_document(document_url, parsing_options)For Databricks MCP, we leveraged our extensive experience with text-to-SQL systems and best practices from our DB-Ally solution: https://deepsense.ai/rd-hub/db-ally/
Rather than giving agents freedom to write SQL directly, we provided atomic operations (like select_insights, delete_insight, modify_insight, etc.) with strictly typed inputs based on the schema designed by the Memory agent. This controlled approach dramatically improved reliability while reducing hallucinations in data manipulation operations.
Practical Implementation with PydanticAI
After evaluating several frameworks for implementing our multi-agent system, we chose PydanticAI for its strict typing and exceptional flexibility. Despite being a relatively new library, PydanticAI provided the robust foundation we needed for a production-grade solution with complex agent interactions.
PydanticAI’s type system was particularly valuable for defining our agent interfaces and tool schemas. Each agent’s capabilities and limitations could be precisely specified through typed inputs and outputs, creating clear boundaries between components. This typing system smoothly integrates with our MCPs:
from pydantic_ai import Agent, Tool from pydantic_ai.mcp import MCPServerHTTP from pydantic import BaseModel, Field class TransformedDocument(BaseModel): text: str title: Optional[str] = Field(None, description="Title of the document") summary: Optional[str] = Field(None, description="Short summary of the document") keywords: Optional[List[str]] = Field(None, description="List of keywords extracted from the document") language: Optional[str] = Field(None, description="Detected language of the document") document_processing_mcp_server = MCPServerHTTP( url=get_backend_settings().mcp_server_url, ) document_processing_agent = Agent( name="DocumentProcessor", output_type=TransformedDocument mcp_servers=[document_processing_mcp_server], )Note: This is a simplified example. In our actual implementation, agents dynamically create the required schemas for document extraction and build models using Pydantic’s create_model functionality.
Productionizing the Solution
As we transitioned from proof-of-concept to a production-ready system, we needed to ensure that the system not only performed well in happy-path scenarios but was also fully reliable, with no regressions when upgrading prompts or other components. For this phase, we implemented solutions across three critical areas: observability, evaluation, and guardrails.
Comprehensive Observability
For monitoring and observability, we needed to track input and output prompts, latency, and token costs to identify suspicious patterns such as failed tasks, slow performance, or excessive costs. We also needed to monitor MCP calls with their responses and side effects. While solutions like LangSmith and LangFuse were available, we chose LogFire for its seamless integration with PydanticAI agents.
import logfire logfire.configure() logfire.instrument_pydantic_ai() # LogFire automatically captures agent interactions def process_document(document_id: str): result = coordinator_agent.run(f"Analyze document {document_id}") logfire.info( 'Log intermediate state of the document', transformed_document=result.transformed_document ) return result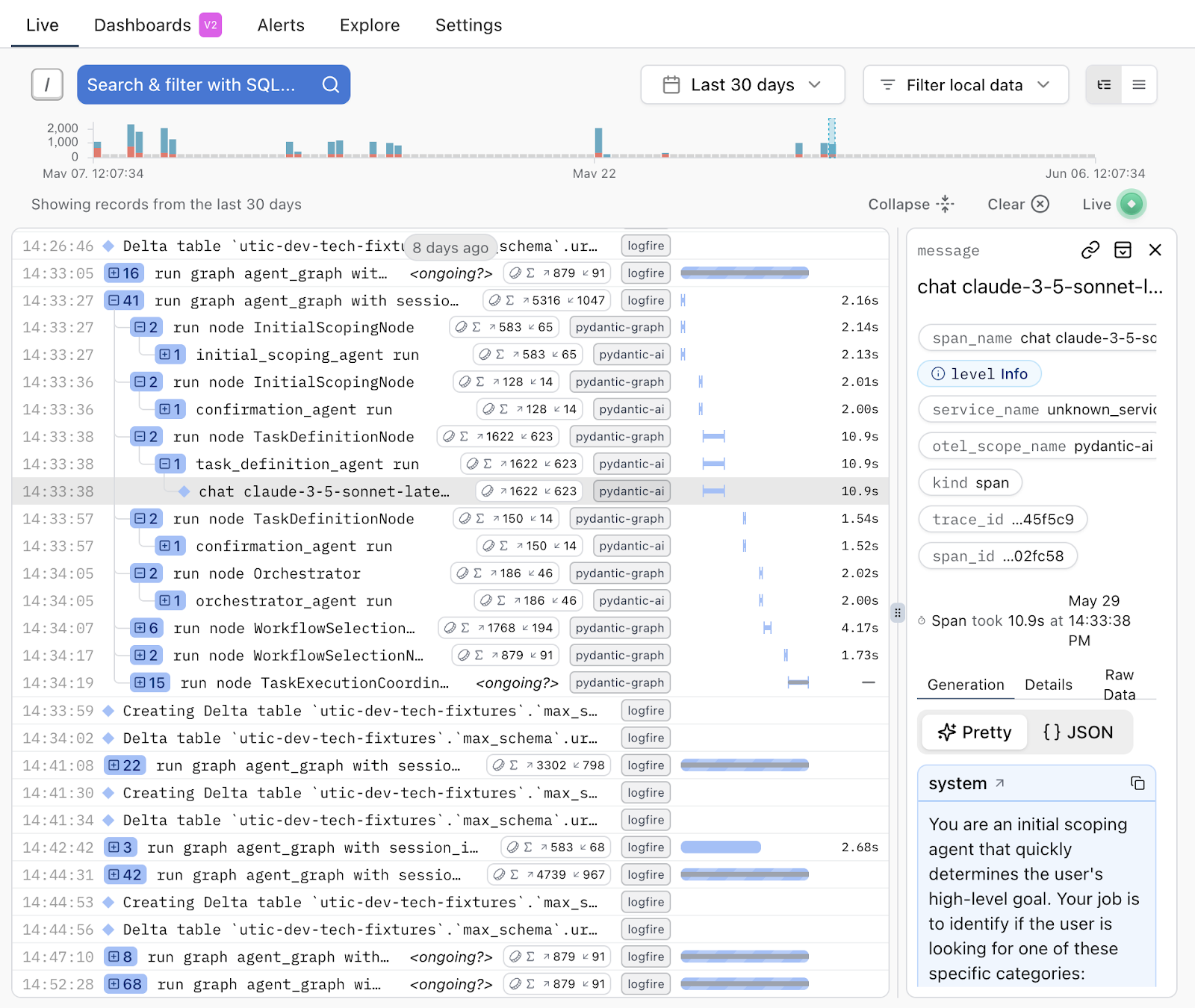
Example trace we can obtain using LogFire
With this implementation, we could quickly debug problems by examining the complete trail of chat messages, agent states, and system interactions with the MCP tools.
Systematic Evaluation
For evaluation, we needed to ensure that each agent successfully performed its specific tasks and that they collectively solved the user’s goal. Some tasks can be verified programmatically (like checking if API calls were executed with valid parameters or if expected database entries were created). In contrastothers required an LLM-as-judge approach to assess quality and relevance. PydanticAI’s evaluators provided the flexibility we needed:
from pydantic import BaseModel from pydantic_evals import Case, Dataset from pydantic_evals.evaluators import IsInstance, LLMJudge class TestCase(BaseModel): document_text: str = Field(description="The text content to be analyzed") task_description: str = Field( description="Specific instruction for what to analyze in the document" ) į class Insight(BaseModel): key_points: list[str] = Field( description="List of important points extracted from the document relevant to the task" ) summary: str = Field( description="Concise synthesis of findings that addresses the task description" ) async def generate_insight(test_case: TestCase) -> Insight: result = await insight_agent.run(test_case.document_text) return result.output insight_dataset = Dataset( cases=[ Case( name="document_analysis", inputs=TestCase( document_text="<text-of-the-document>", task_description="<description-of-the-task>", ), ), ], evaluators=[ IsInstance(type_name="Insight"), LLMJudge( rubric=""" Evaluate if the insights are: 1. Grounded in the document (not hallucinated) 2. Directly related to the specified task 3. Comprehensive in covering the relevant information """, include_input=True, ), ], ) insight_dataset.evaluate_sync(generate_insight)Robust Guardrails
To protect against unexpected user inputs and potential prompt injection attacks, we implemented guardrails using Pydantic output validators. These validators ensured agents couldn’t generate system states that violated our constraints. The example below shows how we can check that an insight was actually saved to a database:
@insight_extractor_agent.output_validator def validate_insight_saved_to_database( ctx: RunContext[InsightExtractorDependencies], insight: Insight ) -> Insight: is_insight_saved = False for tool_call in tool_calls: if tool_call.tool_name == "save_insight_to_database": is_insight_saved = True break # If insight was generated but not saved, retry if not is_insight_saved: raise ModelRetry( "Insight was generated but not saved to the database. Please save the insight." ) # Verify insight has an ID (was properly saved) if insight.id is None: raise ModelRetry( "Insight must have an ID assigned from the database." ) # Verify insight exists in database db = ctx.deps.database stored_insight = db.insights.get_by_id(insight.id) if not stored_insight: raise ModelRetry( f"Insight with ID {insight.id} not found in database. Please ensure it was properly saved." ) # Ensure key_points and summary are not empty if not stored_insight.key_points or not stored_insight.summary: raise ModelRetry( "Insight must contain non-empty key_points and summary." ) return insightThese production-focused enhancements transformed our multi-agent system into a reliable, observable solution ready for enterprise deployment. The combination of detailed logging, systematic evaluation, and enforced guardrails gave us confidence in the system’s performance and security.
How to Build Scalable, Secure Multi-Agent AI Systems with MCP: Best Practices and Lessons Learned
Building and deploying AI agent systems at scale, we found ourselves playing both roles: creators of our own MCP implementation and clients integrating with third-party MCP solutions. The lessons below are distilled from both perspectives, offering practical guidance for developers building custom MCP stacks, as well as those looking to integrate or extend existing frameworks.
Design APIs with an LLM-First Mindset
It’s not enough for MCP to act as a thin wrapper over existing APIs. Tools should be explicitly designed to be LLM-friendly, being easy to pick between and having clear and consistent typing, while avoiding deeply nested dictionary structures. Without this, LLMs either waste context space on parsing boilerplate or fail to choose and configure tools effectively.
Avoid Over and Under-Specifying Tools
Designing tools for LLMs involves striking a balance between being too fine-grained (e.g., having separate tools for translate_to_french, translate_to_spanish, etc.) and too generic (e.g., one process_text tool with vague parameters). Both extremes make it harder for the model to reason about tool usage. Instead, aim for a middle ground: general-purpose tools with clear roles, minimal redundancy, and just enough structure to guide the model without overwhelming it. If LLM-first design isn’t an option, tool definitions should still be made with model reasoning, clarity, and context-efficiency in mind.
Filter and Limit Tools Per Agent
Careful tool selection is crucial – each agent should access only the minimal set of tools required for its role. In our implementation with the MCP Platform and Databricks, we made a conscious effort to restrict each agent to just the relevant subset of tools and context. This filtering not only reduces token usage and cognitive load for the LLM, but also makes the system robust and efficient. It’s always tempting to expose the entire arsenal to every agent, but experience showed that targeted tool access is far more scalable.
Select Proper Model for Proper Use Case (Prompt Engineering + Model Selection)
System optimization goes hand in hand with smart model selection. We found major performance and cost gains by mapping models to task complexity: Claude 3.5 Haiku
handled lightweight, routine operations, while more advanced and creative tasks (for example, extracting insights from documents) were routed to Claude 3.7 Sonnet. Pairing the right prompt engineering strategies with the best-fitting model meant each agent operated within its optimal regime – delivering value without overspending on unnecessary horsepower.
Mind the Token Budget – Context Use Matters
Poorly designed MCP tool schemas can bloat context windows and rack up steep costs. While developing your own MCP server, it’s essential to include only the fields and data truly necessary for each use case. Avoid dumping full JSON payloads – especially nested data and large base64 image blobs – into agent requests or responses if the LLM can’t use or understand them anyway. Prune aggressively. Every unnecessary byte eats into your token budget and reduces the quality of agent reasoning.
Observability Isn’t Optional
Deep, real-time observability fundamentally changed how we develop and maintain the agentic system. Logfire’s integration allowed us to spot, understand quickly, and remedy bugs, as well as identify which agents and flows were driving costs. This sort of visibility is essential – not just for debugging, but for ongoing optimization in increasingly complex multi-agent environments.
Choose Interfaces That Scale with You (Streamlit Lessons)
While Streamlit powered our PoC and delivered a rapid, user-friendly interface in the early days, we quickly encountered its limitations as we began moving toward production. Advanced features, complex layouts, and detailed workflow controls soon pushed Streamlit beyond what it’s comfortable handling, leading to awkward workarounds and slowing us down. In the end, while Streamlit was perfect for prototyping, it fell short when it came to real production needs, so we switched to a more robust framework. The takeaway: what works for a quick prototype might turn into a blocker at scale, so if you expect your project to grow, it’s worth planning for extensibility from the start.
Systematic Evaluation – Unit and E2E Testing
Robust evaluation means blending granular unit tests (at the agent level) with end-to-end (E2E) system tests. While agent logic can often be tested deterministically, E2E testing across LLM-powered flows is inherently nondeterministic. This requires creative evaluation approaches – combining programmatic asserts for side effects with high-level LLM-as-judge assessments – to ensure overall system quality and resilience through upgrades.
Not Every Call Needs to Be an MCP Call
Don’t force everything through MCP. For static APIs or extremely well-defined integration points, a targeted request using a Python SDK or direct HTTP (e.g., requests) can be simpler and more reliable. Save MCP for where standardization, abstraction, or dynamic tool selection is genuinely needed. Use the right tool for each job rather than adopting MCP universally as a golden hammer.
Security: Mind Your Credentials and Agent Privileges
Security must be top-of-mind in all multi-agent systems. Never expose API credentials in LLM calls or shared agent context – always keep them isolated and managed via secure backend logic. Carefully restrict each agent’s operational scope and privileges: avoid giving broad or unnecessary access that might lead to accidental data exposure or unintended actions. Least-privilege design is mandatory when tying agents to sensitive business APIs.
Real-world example: A critical vulnerability was recently discovered in the GitHub MCP integration, where an attacker could place a malicious prompt injection in a public repository issue. When a user’s agent accessed the public repo, it could be manipulated to leak data from private repositories by creating pull requests containing sensitive information. This demonstrates how even trusted tools can become attack vectors when agents have excessive privileges across multiple repositories without proper isolation controls.
Conclusion: Future-Proofing AI Infrastructure. How MCP Standardizes Integration in Scalable Multi-Agent Systems
As AI systems transition from isolated models to collaborative, multi-agent ecosystems, the challenges of integration and orchestration become increasingly complex. Our work, both in building our own MCP layer and integrating third-party solutions, underscores the transformative power of standardization.
Implementing the Model Context Protocol (MCP) shifted our focus from low-level API plumbing to designing robust, maintainable workflows where intelligent agents collaborate effortlessly. This approach not only streamlined our architecture but also enhanced reliability, flexibility, and speed of innovation, enabling us to deliver production-grade solutions across diverse domains.
Ultimately, standard protocols like MCP are essential to future-proofing AI infrastructure. They enable teams to scale, adapt, and innovate without being overwhelmed by integration challenges. If you’re exploring multi-agent systems or facing friction in your AI integration pipelines, MCP offers a clear path to smarter, more sustainable solutions. For more in-depth discussions or implementation details, please don’t hesitate to reach out.



