.png)

I like to play chess, but I am not particularly good at it. When I play, to the extent that I am thinking at all, I mostly think about tactics. Where should I move this given piece? How can I put my opponent’s king in check? Is there an easy pin or fork that I can spot and take advantage of? Rarely I will think a move or two ahead — maybe I will think through a complex chain of I-take-he-takes to decide if a particular trade is worthwhile. But I almost never plan many moves ahead, exhaustively planning every possible move and countermove until I come up with the winning play on the first turn.
I know several people who are reasonably highly ranked chess players. They…do not think about the game like I do. These players talk about ‘calculations’ and ‘move trees’. They talk about ‘pruning’ and ‘routes’. They visualize the game like a sprawling set of possible game states, branching out from where they are now. And as they look through each of the states, they search for a particular path that leads them to victory.
How might a computer play chess? A naive algorithm to ‘solve’ chess would play out every possible move, score each one, and then pick the one that leads to the best set of outcomes. Most of the time, this is too expensive to do in full. But you can approximate it. Maybe instead of playing out every possible move, you simulate only 20 moves in advance. And then as computers get better, you can simulate 40 moves. And then 80. Or maybe instead of evaluating every branch of every set of moves, you aggressively remove some branches that you think are not going to lead anywhere, especially when you see a more promising set of moves.

Good chess players do not think about chess like I do, one move at a time. They think about the game like a computer might think about the game. The best players I know can look at a board state and intuit which moves will likely lead to a good position (and therefore which moves to explore in more depth) and which moves will likely go nowhere (and therefore which moves to simply ignore). And then they will sit and plan out the next 5, 10, 20 moves to see where the game will go. Magnus Carlson is the world’s best chess player because he can ‘find’ the move that, 20 turns later, will lead to victory. And he can find that move faster than the other guy.
Abstractly, chess is a search problem. There is a finite state of documents (moves on the board), a scoring/ranking mechanism (’similarity’), and a retrieval algorithm. And our best chess engines reflect that reality. The AlphaZero wikipedia page is part of a larger Wikipedia section on ‘graph and tree search algorithms’. How does AlphaZero work?
Comparing Monte Carlo tree search searches, AlphaZero searches just 80,000 positions per second in chess and 40,000 in shogi, compared to 70 million for Stockfish and 35 million for Elmo. AlphaZero compensates for the lower number of evaluations by using its deep neural network to focus much more selectively on the most promising variation.
I increasingly think all problems are search problems, or at least can be framed as a search problem. For example, writing software. You know what separates great software engineers from mediocre ones? Scar tissue and intuition. The best software engineers can, with one look at a codebase, get a sense of where and how to invest resources. Build a message queue here. Use this database, it will help with managing your read load later. Let me quickly setup bazel, I can pull out the relevant bits from a previous repository. Evaluate the search tree extremely quickly, have a knack for figuring out (and avoiding) choices that can cause big problems later. In a world where engineering takes a long time and is a rare skill, quick search is what defines a 1000x SWE.
But we no longer live in a world where engineering takes a long time and is a rare skill.
I mean, sure, really great engineers are worth their weight in gold. But the process of actually writing code and trying different things has become cheap. Dirt cheap. If you’re like me and you are not a 1000x SWE but you have enough training under your belt to know what you’re doing, you can use agents to give yourself superpowers.
I’ve been building with coding agents basically exclusively for the last year. My current workflow is something like: come in the office in the morning, spin up five Claude Code tasks, have them submit PRs to me in Github, review them around lunch, spin up a few more, review those around the end of the day, and then go home. I am regularly shipping 10+ PRs per day. On September 25th I apparently shipped 54 commits. Admittedly it was code in a shiny new repository, but I’m still somewhat shocked by that number. Most of my daily interaction with code is now through the Github code review tool. I wish that was a better experience, but I’ll make due.
I started using agents effectively when I began to see code as a search problem. Agents are like our chess players above. At each turn in a conversation or agentic loop, they make a decision. That decision takes them to a new state in the search tree, and the process repeats. Agents can go any which way down the search tree. Sometimes they will start on the right path and then veer off track. Other times, they will be wrong from the start. If you are using a coding agent, your job is to help it narrow down the search tree.
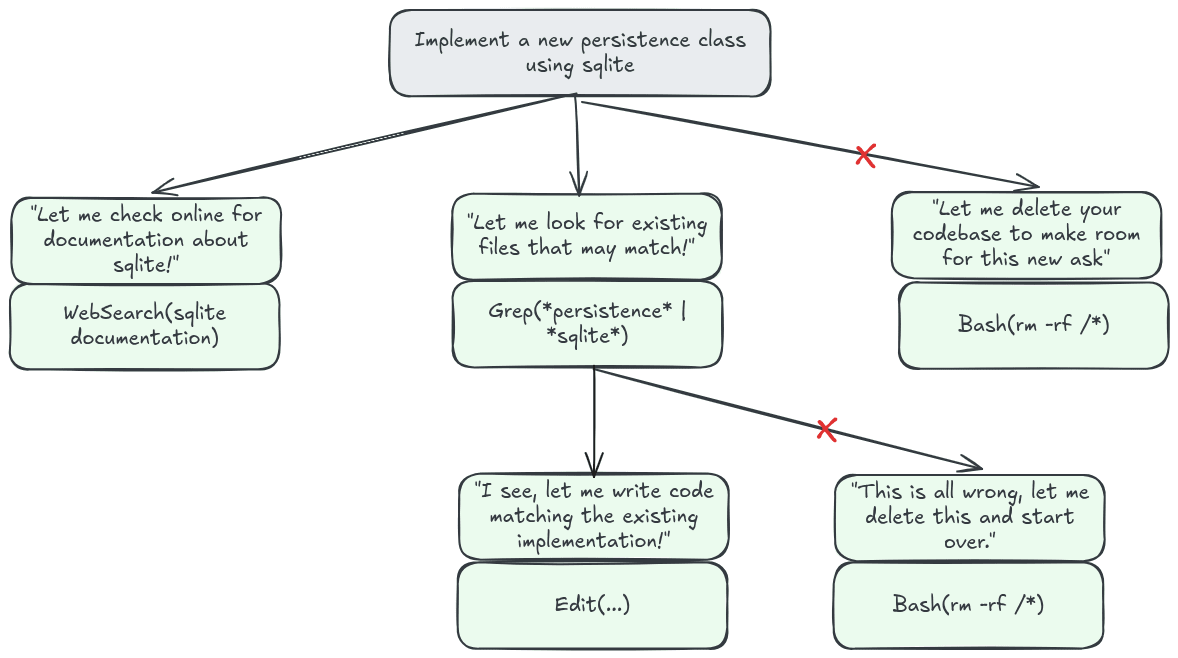
You have a few levers that you can pull:
First, you can help the agent start in a better part of the search tree, where it is easier to find the right answer. Normally, you can do this by providing a really good prompt and managing your context effectively. If you say something like “Make me a reservation,” the model won’t know that you hate spicy food or that you’re a vegetarian. It may not even know that you want to reserve a restaurant! The model will explore (and likely land on) parts of the search tree that it should have just filtered out from the start. Instead, if you say something like “Make me a reservation for two at a vegan restaurant at 7pm on Friday”, the model has to do way less guesswork. In a coding context, do some or all of the work of the actual feature development, minus the code itself. Give the agent exact file paths and the exact things you want to change. And provide previous git commits that may be useful to copy.
Second, you can improve the agent’s ability to more effectively evaluate which next step is the best one to take. This takes two forms. One form is providing the model with tools that it can use to query additional information. Web searches, sql integrations, file system bash tools — these are all ways for a model to answer questions when it is confused. The second form is deterministic or rules based feedback. Think: linters and type checkers. Modern coding agents are really good at doing a set of tasks one by one. If you can encode formal correctness into your system, your models will be significantly better off.
Third, you can modify the search tree itself, making it smaller with more obvious differences between bad and good choices. Roughly, this is equivalent to “making the codebase idiot proof” or “making the right thing the easy thing.” You should be designing your codebase like a senior engineer. What do you want to make it easy to do? What kinds of features should it be easy to add more of? Spend time thinking about what the “happy path” is and how to minimize it. And then go a step further and write out that happy path as an explicit guidance to your agent.
Fourth, you can insert yourself into the process in multiple places. It’s easier to review a plan than it is to review code. Force your agent to separate their process into three distinct steps: gathering context, writing and iterating on a plan, and finally creating code. Review each step to make sure it is on track.
These levers make it more likely that a single agent will write code and solve problems effectively. Depending on the problem at hand, you can choose how much effort to put into your agent; the more effort you put in the better the outcome will likely be. Which brings me to the most important rule to get the most of your coding agents: it’s ok to only put in a little effort as long as you parallelize.
As a software engineer using a coding agent, your goal is not to get the best single shot code output. Your goal is to simply get the best code, period. If coding is a search problem, a very easy way to improve your code is by running many searches at once. So do that! Because coding is now cheap, you can spin up several agents for the same coding task. Evaluate which one did the best job, merge that PR, and simply close the rest. If none of them did the right thing, go back and spend more time on your prompt and tooling and then try again. As you iterate you’re simulating the 1000x coder, seeing and discarding all of the different routes through the search tree that don’t really work. But instead of doing that with intuition and gut feel, you’re doing it by actually looking at a bunch of variants of the code in front of you and figuring out if you like the result.
Most of the job is writing specification and code review. Design docs and markdown files, things like that. Detailed specification, sometimes even with code examples, but still specification.
If you’re already a senior engineer, this should all sound very familiar. Senior engineers write design docs that junior engineers implement. Senior engineers think about trade-offs in the codebase, about what is easy to do and what is hard to do. Senior engineers check in with their junior teammates to make sure they are on track. Senior engineers review a lot of code.
For the last two decades, knowing syntax was an important and rare skill. You could build a career as a software engineer without ever having to think about maintaining a complicated code base, by simply following a more senior engineer’s guidance. I think that world is rapidly fading. The job of a programmer has changed; we’re all senior engineers now.


