.png)


One library to bring them all and in the TypeScript, bind them.
When we were building the the Infinite Chat API, initially, we only supported the OpenAI format. This was fine, until a lot of our customers started asking, asking for more.
LLM Bridge - Interoperability between input formats of various LLMs, with observability, error handling, etc. built in.
Many customers were using Anthropic SDKs, Gemini pro models, AI SDK, langchain, etc. We wanted to keep our developer experience as beautiful as it currently is - one universal 'routing' layer, and proxy, that also serves as a memory provider.
Now, we were stuck implementing a complex system, with multiple different providers, each provider having different ways to do multi-modal, tool call chains, calculating token counts, etc. etc. for all these different models and functionalities that they provide.
Almost immediately, our straightforward logic splinted into a mountain of complexity. Instead of a clean pipeline, we were left inundated with branching logic, special-case conditionals, and provider-specific exceptions. Where there used to be a simple flow, we now had three to six different diverging code paths, each adding friction, increasing the maintenance burden, and slowly draining our sanity. We find ourselves wondering: "How is there not a universal standard for handling this already?"
Introducing LLM-Bridge
We've gone through the pain, and this is why we're so excited to announce a brand new open-source package designed to streamline exactly these types of workflows: llm-bridge.
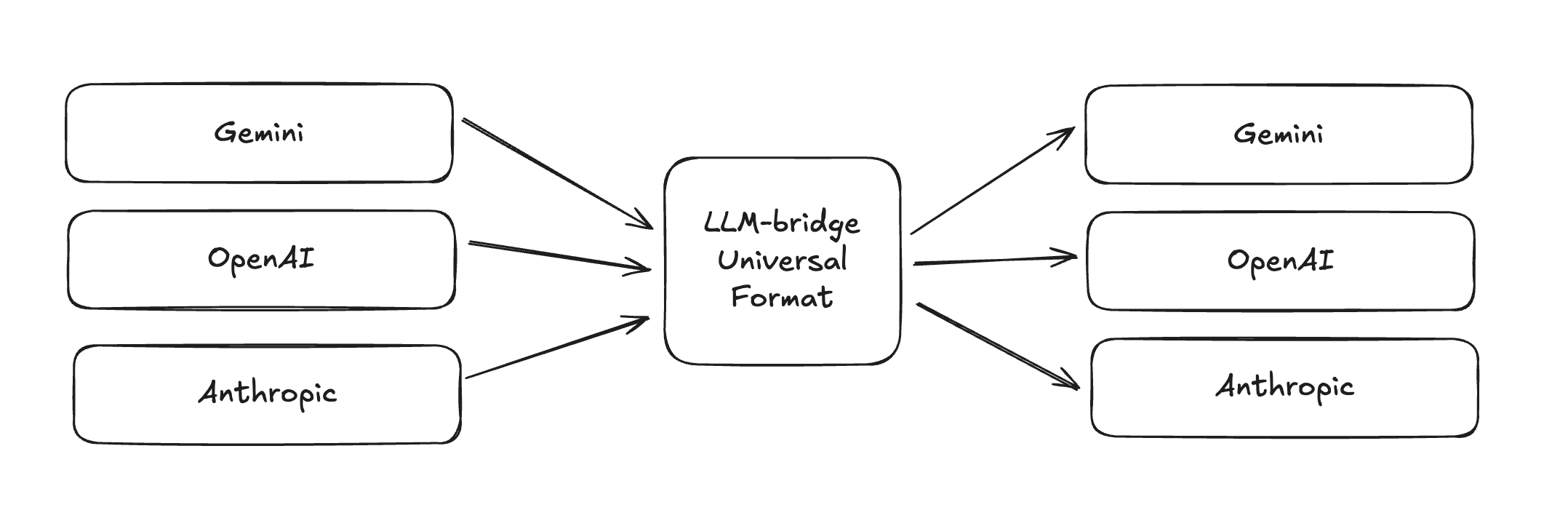
The package aims to be the bridge between the different LLM API formats by implementing a standard, universal format that losslessly represents any well-formed OpenAI, Anthropic, or Gemini API payload, as well as helper functions to convert our universal representation to and from any of these API providers' formats.
We've recently been dogfooding this package in the newest version of our Infinite Chat offering, and since it's been such a useful tool for us internally, we've open-sourced it on Github so that everyone in the community can contribute to and benefit from it.
Why did we build this?
We currently offer a product called Infinite Chat, a model-enhancing service which allows developers to extend the context window of any model far beyond its technical context limit. At a high level, we've designed it to act as a proxy for LLM APIs, intercepting requests to the OpenAI, Anthropic, and Gemini APIs, extracting relevant data from them, and feeding additional context back into the requests as needed. This makes adoption seamless: all you have to do as a developer is prepend your provider's base URL with our API's URL, add your Supermemory API key, and we take care of the rest. That is, there is no change to the client interface—you can keep using your SDK of choice no matter what.
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, baseURL: "https://api.supermemory.ai/v3/https://api.openai.com/v1", headers: { "x-api-key": process.env.SUPERMEMORY_API_KEY, }, }); /// or new Anthropic() or new GoogleGenAI()This is a huge win for our users but it comes at a cost for us: we have to be able to process every single possible request, in any state, to any AI provider's API, in a way that is completely invisible to the client. As you might expect, this is not an easy problem to solve and a major pain point we encountered was simply in processing the different request shapes for each of the target APIs. The current state of the ecosystem is such that the OpenAI, Anthropic, and Google APIs are not cross-compatible. They all demand data to be sent in similar but slightly different formats. While they do all offer specific OpenAI-compatible endpoints, their compatibility isn't perfect and they don't always offer full feature parity with the proprietary endpoints. More importantly though, as developers, we shouldn't have to force our users to modify their choice of API to use our service.
As a result, the status quo is that anybody wishing to be able to accept any of these formats has to implement their own logic for each of them, or write their own ad-hoc and often leaky abstractions narrowly tailored to their needs. Unfortunately, all of that glue quickly balloons in complexity and silently drifts as vendors add features. This is the problem llm-bridge was built to solve.
 From xkcd's "Standards" (https://xkcd.com/927)
From xkcd's "Standards" (https://xkcd.com/927)If you've been active in this space recently, you may already be thinking of a few offerings that share the goal of unifying interactions with the different provider APIs (inb4 Vercel's AI SDK). These all have their place, but none of them quite fit our needs. Specifically, our solution had to:
- Be universal
- Be lightweight
- Retain full feature parity (multimodality, tool calls)
- Support lossless transformations, and translations
- Not require changes to the client interface
There are plenty of products which meet 3 or 4 of these criteria, but none that meet all 5. So, we built our own.
How did we solve it?
Our solution is llm-bridge, a library which defines a universal format for representing API requests for any of the major providers. With llm-bridge, you can do any processing you need on any request intended for any of the major providers, like changing the messages array, updating the system prompt, extracting multimodal data, and more. When you're done, you can use one of our helper functions to convert it into the right format for your target API, even if the target is different than that of the original payload. Because every vendor-specific oddity is stashed intact under original, you never lose multimodal blobs or tool definitions; because the same helpers wrap and translate errors, you can bubble one canonical exception type up your stack instead of juggling three dialects. In effect, three diverging code paths shrink to a symmetrical “normalize → process → emit” pipeline that’s less than a dozen lines long yet preserves full feature parity across OpenAI, Claude, and Gemini.
llm-bridge is designed to make working with these APIs simpler for all use-cases, whether you run a proxy for LLM APIs, are building middleware for LLMs, or are building consumer-facing apps. Here are some of the things it can do for you:
Transform between request formats
Transformations in llm-bridge are lossless, meaning that round-trip transformations preserve all the information from the original request. Every original key is tucked under a _original field, so fromUniversal can reproduce the exact JSON you fed in. You can use the universal format as your base too, if you're building a consumer-facing app and just need a way to construct and represent an abstract LLM API call.
import { toUniversal, fromUniversal } from "llm-bridge" const uni = toUniversal("openai", openaiReq) // ↙ normalise // ...inspect / mutate... // add messages in the middle, edit messages, etc. const claudeReq = fromUniversal("anthropic", uni) // ↗ emitYou can also "edit" messages mid-conversion, for functionality like:
async function editMessages(universal: UniversalBody): Promise<{ request: UniversalBody contextModified: boolean }> { let processed = universal let contextModified = false // 1. Convert multimodal if needed if (hasMultimodalContent(universal)) { processed = await enhancedMultimodalProcessor(processed, { imageDescriptionService: async (data) => { // Call your vision API here return "A photo of a sunset over mountains" }, documentParser: async (data, mimeType) => { // Parse PDF/document here return "Document content extracted..." } }) contextModified = true } // 2. Add or edit context context processed.messages.push({ id: generateId(), role: 'system', content: [{ type: 'text', text: 'Your memory here...' }], metadata: { provider: processed.provider } }) return { request: processed, contextModified: true } }Error handling
LLM providers each return their own distinct error formats, making consistent error handling tricky. With llm-bridge, you can translate errors from any provider into a single, consistent format, simplifying your error handling significantly.
import { buildUniversalError, translateError } from 'llm-bridge' // Create a universal error const error = buildUniversalError( "rate_limit_error", "Rate limit exceeded", "openai", { retryAfter: 60 } ) // Translate to different provider formats const anthropicError = translateError(error.universal, "anthropic") const googleError = translateError(error.universal, "google")Utilities
The library also ships helpers for the small but common things you may need when handling inputs and outputs for each of the APIs, like token counting.
Use cases and examples
- Translating between model calls (For eg: Proxy Claude code requests to send them to Gemini instead)
- Routing and optimizing costs
- Analyzing images and converting multi-modal into text to save money
- Load balancing between different providers based on availability
- Generating summaries using cheaper models
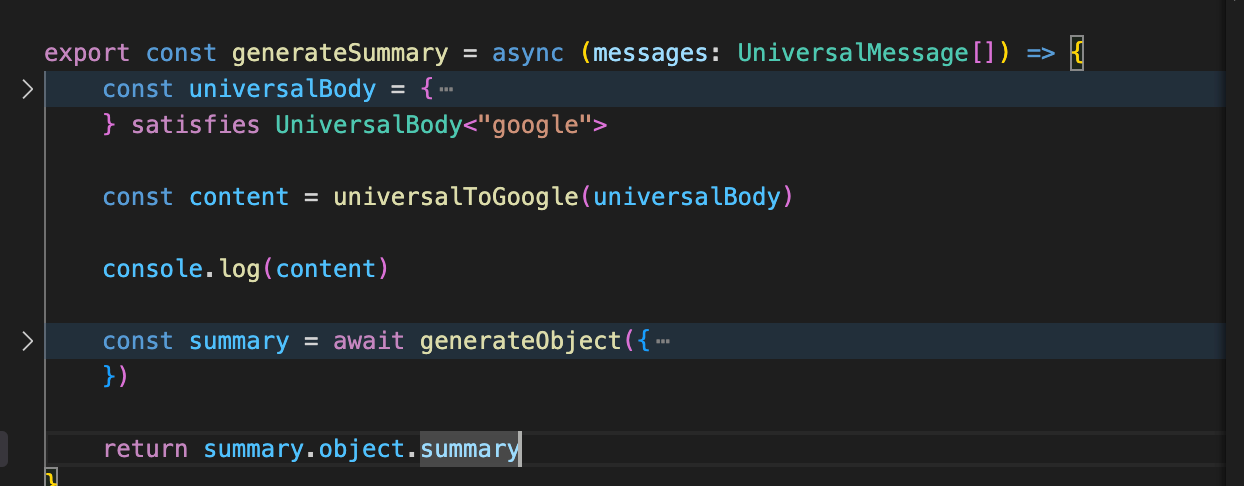
Dogfooding at supermemory
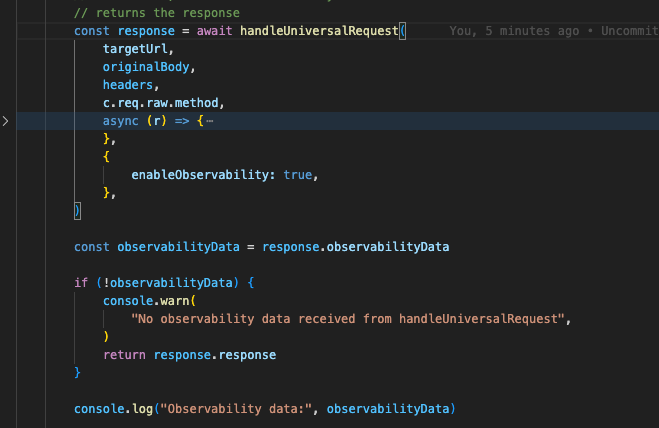
We heavily use llm-bridge internally at supermemory to handle requests in our Infinite Chat endpoint, and many others, especially for conversational tasks.
This is, literally, our code, where the manipulation of data happens inside async r => {}.
We recognize any providers have OpenAI-compatible format support, but we still decided to build LLM-bridge because we, as supermemory, wanted to allow developers to use their preferred SDKs and format, and leave the worry of memory to us.
Vibe coding
This project was vibe-coded using Claude Code. because no one wants to go through the pain of going through every single model provider :(
But we think that's a good thing. The TL;DR is that llm-bridge is almost fully covered with tests using vitest, where very single unique implementation of llm-bridge is verifiably testable inside the tests/ folder
Putting it all together
When your app receives an LLM request, all you have to do is pass it through llm-bridge—the rest happens automatically. The library handles converting requests from any provider into a universal representation, so you can seamlessly inspect, modify, or reroute them without worrying about vendor-specific details.
By standardizing API interactions into a single format, it becomes trivial to add failover, traffic splitting, analytics, or cost-based routing—all without touching the client's existing integration. We built this to simplify our own workflows, and we’re excited to see how it can streamline yours. Check out the repo, try it out in your own stack, and let us know what you think!



