.png)

Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover Big Tech and startups through the lens of senior engineers and engineering leaders. Today, we cover one out of four topics from today’s deepdive into the recent AWS outage. To get articles like this in your inbox, every week, subscribe here.
Monday was an interesting day: Signal stopped working, Slack and Zoom had issues, and most Amazon services were also down, together with thousands of websites and apps, across the globe. The cause was a 14-hour-long AWS outage in the us-east-1 region — which outage even disrupted a Premier League soccer game.
Today, we look into what caused this outage.
To its credit, AWS posted continuous updates throughout the outage. Three days after the incident, they released a detailed postmortem – much faster than the 4 months it took in 2023 after a similarly large event.
The latest outage was caused by DynamoDB’s DNS failure. DynamoDB is a serverless NoSQL database built for durability and high availability, which promises 99.99% uptime as its service level agreement (SLA), when set to multi-availability zone (AZ) replication. Basically, when operated in a single region, DynamoDB promises – and delivers! – very high uptime with low latency. Even better, while the default consistency model for DynamoDB is eventual consistency (reads might not yet reflect the actual status), reads can also be set to use strong consistency (guaranteed to return the actual status).
All these traits make DynamoDB an attractive choice for data storage for pretty much any application, and many of AWS’s own services also depend heavily on DynamoDB. Plus, DynamoDB has a track record of delivering on its SLA promises, so the question is often not why to use DynamoDB, but rather, why not to use this highly reliable data storage. Potential reasons for not using it include complex querying, complex data models, or storing large amounts of data when storage costs are not worth it compared to other bulk storage solutions.
In this outage, DynamoDB went down, and the dynamodb.us-east-1.amazonaws.com address returned an empty DNS record. To every service – external to AWS or AWS internal – it seemed like DynamoDB in this AWS region disappeared off the face of earth! To understand what happened, we need to look into DynamoDB DNS management.
Here’s an overview:
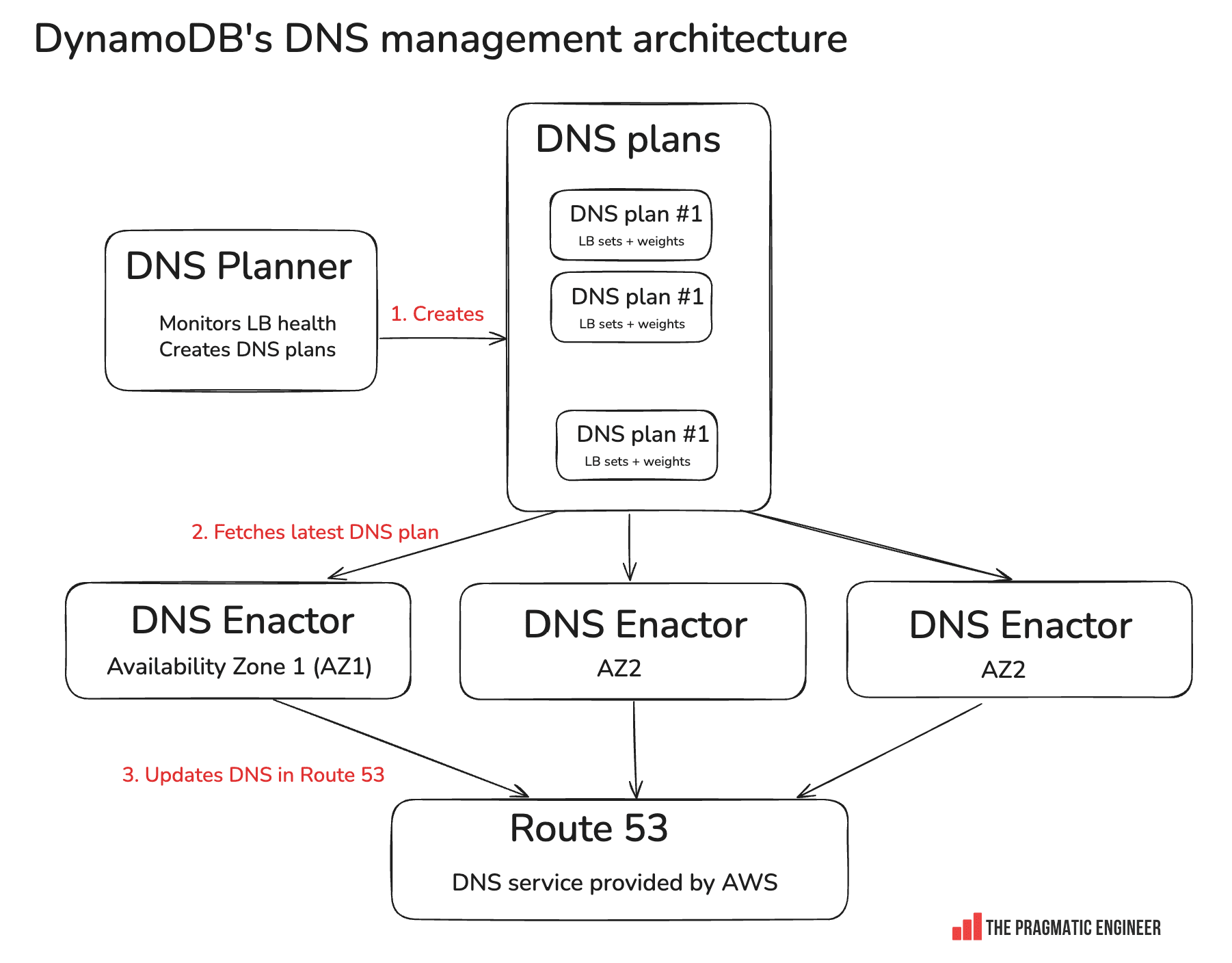
How it works:
DNS planner: this service monitors load balancer (LB) health. As you can imagine, DynamoDB runs at a massive scale, and LBs can easily get overloaded or under-utilized. When overloading happens, new LBs need to be added, and when there’s underutilization, they need to be removed. The DNS planner created DNS plans. Each DNS plan is a set of LB sets, and assigning them weights on how much traffic to give the LB.
DNS enactor: the service responsible for updating the routes in Amazon’s DNS service called Route 53. For resiliency, there is one DNS enactor running in each availability zone (AZ). In us-east-1, there are 3 AZs, and 3x DNS Enactor instances.
Race conditions are expected: with 3x parallel DNS Enactors working simultaneously, race conditions are expected. The system deals with this by assuming eventual consistency: even if a DNS Enactor updates Route 53 with an “old” plan, DNS plans are consistent with one another. Plus, updating happens quickly, and DNS Enactors only use the latest plans from the DNS Planner.
Several independent events combined to knock DynamoDB’s DNS offline:
High delays on a DNS Enactor #1. Updating DNS took unusually long for one DNS Enactor for some reason. Usually, these updates are rapid, but weren’t on 20 October.
DNS Planner turns up the pace in churning out DNS plans. Just as DNS updates turned slow, the DNS planner started to produce new plans at a much higher pace than before.
DNS Enactor #2 rapidly processes DNS plans. While DNS Enactor #1 was applying DNS plans at snail’s pace, DNS Enactor #2 was storming through them. As soon as it finished writing these plans to Route 53, it went back to DNS Planner and deleted the old plans.
These three things pushed the system into an inconsistent state and emptied out DynamoDB DNS:
DNS Enactor #1 unknowingly uses an old DNS plan. When DNS Enactor #2 finished applying the newest DNS plan, it went back to DNS Planner and deleted all older plans. Doing so should have meant that other DNS Enactors did not use old plans; but remember, DNS Enactor #1 was slow and still processing through an old plan! As a result, the check by DNS Enactor #1 was stale.
DNS Enactor #2 detects the old plan being used and clears DNS records. DNS Enactors have another cleanup check: if they detect an old plan being used, they delete the plan itself. Deleting a plan means removing all IP addresses for the regional endpoints in Route 53. So DNS Enactor #2 turned the dynamodb.us-east-1.amazonaws.com DNS empty!
DynamoDB going down also took down all AWS services dependent on the us-east-1 DynamoDB services. From the AWS postmortem:
“All systems needing to connect to the DynamoDB service in the N. Virginia (us-east-1) Region via the public endpoint immediately began experiencing DNS failures and failed to connect to DynamoDB. This included customer traffic as well as traffic from internal AWS services that rely on DynamoDB. Customers with DynamoDB global tables were able to successfully connect to and issue requests against their replica tables in other Regions, but experienced prolonged replication lag to and from the replica tables in the N. Virginia (us-east-1) Region.”
The DynamoDB outage lasted around 3 hours; I can only imagine AWS engineers scratching their heads and wondering how the DNS records were emptied. Eventually, engineers manually intervened, and brought back DynamoDB. It’s worth remembering that bringing up DynamoDB might have included avoiding the thundering herd issue that is typical of restarting large services.
To be honest, I’m sensing key details were omitted from the postmortem. Things unmentioned which are key to understanding what really happened:
Why did DNS Enactor #1 slow down in updating DNS, compared to DNS Enactor #2?
Why did DNS Enactor #2 delete all DNS records as part of cleanup? This really made no sense, and it feels like there’s an underlying reason.
The race condition of one DNS Enactor being well ahead of others seems to be easy enough to forecast. Was this the first time it happened? If not, what happened after previous, similar incidents?
Most pressingly, how will the team fix this vulnerability which could happen anytime in the future?
With DynamoDB restored, the pain was still not over for AWS. In fact, Amazon EC2’s problems just got worse. To understand what happened, we need to understand how EC2 works:
DropletWorkflow Manager (DWFM) is the subsystem that manages physical servers for EC2. Think of it as the “Kubernetes for EC2.” EC2 instances are called “droplets.”
Lease: DropletWorkflow Manager tracks the lease for each droplet (server) so it knows if and when a server is occupied, or can be allocated to an EC2 customer. The DWFM does a status check of the server every few minutes to determine its state.
State check results are stored in DynamoDB, so the DynamoDB outage caused problems:
1. Leases started to time out. With state check results not returning due to the DynamoDB outage, the DropletWorkflow Manager started to mark droplets as not available.
2. Insufficient capacity errors on EC2: with most leases timed out, DWFM started to return “insufficient capacity error” messages to EC2 customers. It thought servers were not available, after all.
3. DynamoDB’s return didn’t help: when DynamoDB came back online, it should have been possible to update the status of droplets. But that didn’t happen. From the postmortem:
“Due to the large number of droplets, efforts to establish new droplet leases took long enough that the work could not be completed before they timed out. Additional work was queued to reattempt establishing the droplet lease. At this point, DWFM had entered a state of congestive collapse and was unable to make forward progress in recovering droplet leases.”
It took engineers 3 more hours to come up with mitigations to get EC2 instance allocation working again.
Network propagation errors took another 5 hours to fix. Even when EC2 was looking healthy on the inside, instances could not communicate with the outside world, and congestion built up inside a system called Network Manager. Also from the postmortem:
“Network Manager started to experience increased latencies in network propagation times as it worked to process the backlog of network state changes. While new EC2 instances could be launched successfully, they would not have the necessary network connectivity due to the delays in network state propagation. Engineers worked to reduce the load on Network Manager to address network configuration propagation times and took action to accelerate recovery. By 10:36 AM PT [11 hours after the start of the outage], network configuration propagation times had returned to normal levels, and new EC2 instance launches were once again operating normally.”
Final cleanup took another 3 hours. After all 3 systems fixed – DynamoDB, EC2’s DropletWorkflow Manager and Network Manager – there was a bit of cleanup left to do:
“The final step towards EC2 recovery was to fully remove the request throttles that had been put in place to reduce the load on the various EC2 subsystems. As API calls and new EC2 instance launch requests stabilized, at 11:23 AM PDT [12 hours after the outage started] our engineers began relaxing request throttles as they worked towards full recovery. At 1:50 PM [14 hours after the outage started], all EC2 APIs and new EC2 instance launches were operating normally.”
Phew – that was a lot of work! Props to the AWS team for working through it all in what must have been a stressful night’s work. You can read the full postmortem here, which details the impact on other services like the Network Load Balancer (NLB), Lambda functions, Amazon Elastic Container Service (ECS), Elastic Kubernetes Service (EKS), Fargate, Amazon Connect, AWS Security Token Service, and AWS Management Console.
This was one out of four topics from today’s The Pulse, analyzing this large AWS outage. The full issue additionally covers:
Worldwide impact. From Ring cameras, Robinhood, Snapchat, and Duolingo, all the way to Substack – sites and services went down in their thousands.
Unexpected AWS dependencies. Status pages using Atlassian’s Statuspage product could not be updated, Eight Sleep mattresses were effectively bricked for users, Postman was unusable, UK taxpayers couldn’t access the HMRC portal, and a Premier League game was interrupted.
Why such dependency on us-east-1? It feels like half of the internet is on us-east-1 for its low pricing and high capacity. Meanwhile, some AWS services are themselves dependent on this region.



