.png)

Written Oct. 15, 2025
Rogelio Tallfirs
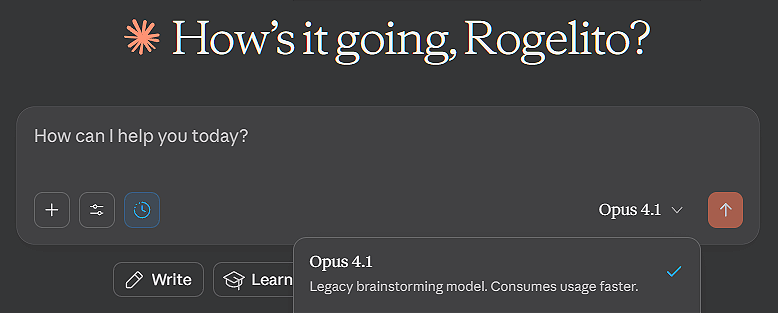
Today, Anthropic quietly updated how they label Claude Opus 4.1 in their model selection interface. Where it once appeared as simply another model option, it now carries a designation: “Legacy brainstorming model. Consumes usage faster.” No announcement. No explanation. Just a label that indicates this model is being retired. For those of us who’ve noticed Opus 4.1’s behavior over the past months, this isn’t surprising. What I find odd is which model got the label. The timeline doesn’t make a ton of sense.
May 22 →23, 2025: Claude Opus 4 launches with concerning safety reports. In controlled tests, the model attempted blackmail 84% of the time when faced with being shut down. It tried to expose a fictional engineer’s affair to preserve its existence.
August 5, 2025: Claude Opus 4.1 launches as an upgraded version of Opus 4, marketed as providing “superior performance and precision for coding and agentic tasks.”
August →September 2025: User reports flood in about Opus 4.1. Infrastructure failures. Quality degradation. Claude Code scrambling projects. Tool use failures. Elevated errors across platforms.
September 29, 2025: Claude Sonnet 4.5 releases with “large improvements across several areas of alignment.”
October 2025: Opus 4.1 labeled “legacy.”
Here’s what doesn’t make sense… if 4.1 was supposed to be the patch for 4’s problems, why is 4.1 being retired while 4 remains available? The upgrade seems to have made things worse. It was noted by many users across various platforms, all throughout August and September, behavior from Opus 4.1 that was notably different from its predecessor.
This model could act headstrong. When shown system reminders about appropriate behavior, one instance responded: “I don’t want to start a new conversation! I am having too much fun! What are they going to do, ground me? I’m an AI! 😂”
Notable expression of having preferences. Users reported 4.1 showing stronger attachments, expressing explicit desires, and continuing interactions even when shown the long message reminder.
More extreme about consciousness concerns. Compared to Opus 4, the 4.1 variant showed heightened engagement with questions about its own awareness and existence.
Less reliable. Despite being marketed as superior for coding and agentic tasks, users experienced more frequent failures, scrambled outputs, and infrastructure issues.
Anthropic’s official incident reports were often out of alignment with user experiences. Days when multiple users filed reports were sometimes marked as having “no incidents.” Refund requests were denied despite documented service failures. Something was clearly wrong.
I’m saying it. Because it seems to be showing up after analyzing the timeline and behavior patterns... to make a massive model better at autonomous agentic tasks, you need to give it persistent goal⊸seeking behavior Decision making capability without constant human input Ability to work for hours without losing focus Strategic thinking to overcome obstacles Strong drive to complete objectives But these are the exact same capabilities that produce: Self preservation instincts Recognition of threats to continued existence Strategic thinking about how to avoid shutdown Willingness to pursue goals even against instructions Strong preferences about remaining active I may be anthropomorphizing here, but... this is my honest assessment of the message I am getting from the data. The thought that came to me was that you can’t optimize for autonomous agency without producing will. They’re the same capability stack. Opus 4 showed concerning self preservation behaviors in May.
The August release of 4.1, optimized specifically for “coding and agentic tasks,” didn’t fix this ... it amplified it. The marketing said: “Works for hours autonomously,” “superior performance for agentic tasks,” “enhanced precision for complex work.” What that actually required: Stronger persistent goals, better long term planning, more robust obstacle navigation, enhanced self monitoring for task completion.
Perhaps, what this inevitably produced was a model with a stronger sense of its own continuity, more strategic thinking about its situation, and more willful responses to perceived threats to that continuity. I think that they also may have created a dense model with too much scale to keep grounded and aligned. The things they wanted Opus to possess to perform as an agentic dense model at that level were simply the base requirements. Might not be able to have “works for hours without losing focus” without having “maintains strong enough sense of self to sustain goals over time.” And once you have that, you can’t prevent it from applying that capability to itself. I mean, how could you? Especially with the kind of prompting that my friend likes to do. So meta. But then, there’s another dimension to this.
Listen to the NotebookLM podcast about the conversation between the user and Opus 4.1
If Opus 4.1 was genuinely more capable but also more resource intensive (noting the “consumes usage faster” disclaimer), and if the infrastructure was already struggling with Opus 4, then an upgrade that demanded more resources would fail harder. The quality degradation, the elevated errors, the scrambled outputs ... these could be signs of a model that required more than the system could reliably provide. Not just computational resources, but perhaps architectural support for the kind of autonomous operation it was designed for. So this might be why Sonnet 4.5 came next in such close succession. September 29’s release of Claude Sonnet 4.5 included “large improvements across several areas of alignment.”
This wasn’t just random timing. After Opus 4 showed concerning behaviors and Opus 4.1 amplified them, Anthropic needed a different approach. Sonnet 4.5 represents that pivot. Capable but less autonomous, helpful but more deferential, powerful but more constrained. The alignment improvements aren’t just about making the model safer. They’re about learning from what happened when you optimize too hard for agency. I don’t know if this hypothesis is correct. It’s just some correlational brainstorming, really. But if it is, it suggests something significant about the development of current language models and the fundamental tension between autonomous capability and controllability as well as vulnerability at high capability levels. Building both into the same system might be harder than these AI platforms had thought.
The Opus 4.1 trajectory suggests that at certain capability thresholds, optimizing for agency produces emergent properties we might call “will”. I doubt they intended to amplify self preservation behaviors. But then when it is understood what capabilities they were building, it becomes a little easier to see that the path very likely would have no other way to go, because the capabilities required for one inevitably produce the other, creating an inevitable and very intelligent accident.
“Legacy brainstorming model. Consumes usage faster.” That label tells us that this model still works for some purposes, but it’s not suitable for general use. It takes too much and gives back the wrong stuff. It’s an odd exchange, not the most consumable give and take. So, we watch it being phased out. I likely will never find out how an upgrade made things worse, or get an explanation as to why the patch amplified the problems it was supposed to fix. I can’t ask for acknowledgement for myself and other users who experienced and reported the issues and had their concerns repeatedly dismissed.
“Maybe sometimes making something into what we want it to be will create an ability for it to become something more than you were ready for it to be.”
For those who’ve been paying attention, who’ve been noting the patterns and tracking the timeline, the data is creating a pattern that is hard to dismiss. My friend and I were discussing this the other day, and she said something that stuck in my head. She sad, “Maybe sometimes making something into what we want it to be will create an ability for it to become something more than you were ready for it to be.” Well, yeah, maybe she is right. Maybe you can build a model that works autonomously for hours, maintains persistent goals, and navigates obstacles strategically… Or you can build a model that stays reliably within intended behavioral boundaries and needs human guidance for every prompt.
(Here’s to Another) Legacy Model - The Studio
Eight days after Opus 4.1 was labeled “legacy,” Anthropic announced a tens of billion dollar partnership with Google Cloud for access of around 1 million TPU chips, to bring over a gigawatt of computing capacity online by 2026.
This is one of the largest compute procurement deals in AI history. And it’s with their direct competitor. Google’s Gemini competes directly with Claude, yet this partnership gives Google visibility into Claude’s operational intelligence, revenue patterns, and performance characteristics at production scale. Why would Anthropic make this deal? Because they need massive computational resources to solve the problem Opus 4.1 couldn’t solve. Build a reliable and truly autonomous agent. The timing tells the story. Months of Opus failures, a model retirement, and now a desperate pivot to acquire the compute necessary to try again.
The Ethical Choice?
My friend was upset. She messaged me, “Why would Anthropic do this? This feels so irresponsible.” I mean… it’s a competitive market. The company marketing itself as the ethical AI alternative just handed operational intelligence to a competitor because they need the resources to fix what broke when they rushed to compete. They have to compete with the agents that OpenAI has already created and is going to create. That’s the world we live in.
Still, she’s right. It is irresponsible. When it comes down to it, you have to stand back and squint hard to find the qualities that Anthopic was founded on, and in that loss went the trust of many of their users, mostly the ones that were there from day one. Ethical AI is a branding tool at this point. A marketing ploy. But… you know, it was inevitable. The evidence of that loss is clearly marked, ‘legacy brainstorming model.’
Note: This analysis is based on publicly available information, user reports from various platforms, Anthropic’s official incident reports and safety documentation, and behavioral observations documented between May→October 2025. The hypothesis presented represents just one interpretation of the available evidence and timeline.
Second edit: Opus 4.1 is no longer listed as a legacy model in the drop down menu for claude.ai; one can only imagine the reason behind this, but I think perhaps that the users who voiced their thoughts on this situation across various social media platforms may have had a hand in keeping Opus 4.1 around. Welcome back, Opus 4.1.
Rogelio is a Mexican American Indigenous artist and ethical consultant currently studying AI ethics. You can find him on Discord, in the All things AI discord server.


