.png)


What does Cerebras Systems, the first successful waferscale computing commercializer and a contender in the race to provide compute for the world’s burgeoning AI inference workload, do for an encore?
Well, the company just raised $1.1 billion in Series G funding to find out. The funding also gives Cerebras that much more time to expand and diversify its customer base to sweeten the initial public offering that was announced back in October 2024. The word on the street at the time was that Cerebras wanted to raise between $750 million and $1 billion in its IPO, which would translate into a valuation of somewhere between $7 billion and $8 billion.
With the $1.1 billion Series G funding, Cerebras says that it has a post-money valuation of $8.1 billion. So it has the money and the valuation it wanted from an IPO without the grief of an IPO. But, this is probably the last hurrah for funding before an IPO, which will probably happen in 2026 if we had to guess. This will be peak AI investment at a local maxima at the very least and perhaps the peak AI investment before the GenAI bubble bursts. Either way, we think that 2026 is the year the GenAI boom will break through another Mach level and make some noise, and there will be no better time to go to Wall Street to get piles of money.
The Series G funding was led by Fidelity Investments (which has close to $6 trillion in assets under management and which is another way of saying it is rich as hell) and Atreides Management, which is run by Gavin Baker, a Fidelity portfolio manager for two decades starting with the Dot Com boom and whose wife is a fund manager at the financial services giant. This funding from Atreides and its progenitor Fidelity is a big win for Cerebras in that it is not oil money from the Middle East but investment money from Boston, and it is not surprising. Benchmark Capital, Tiger Global, Valor Equity Partners, 1789 Capital, Altimeter, and Alpha Wave have all kicked in money during the Series G round, and to date, including $335 million of restricted cash from the Group 42 Holding investment vehicle for the United Arab Emirates, has raised $2.16 billion. (G42 is the largest customer to date for Cerebras iron.
When Cerebras filed is S-1 form with the US Securities and Exchange Commission last fall, G42 had spent $118.7 million in sales from Q3 2023 through Q2 2024, but all other companies for the prior two and a half years only bought $55.8 million of Cerebras services and systems. We have not seen updated financials from Cerebras since last fall, so we don’t know how it has done financially in the past year. We do know that it had $427.5 million in cash and net losses were growing, but it should still have some cash on hand from prior fundraising rounds.
Interestingly, both Fidelity and Atreides (which is a riff on the Greek kings Agamemnon and Menelaus, who were sons of Atreus, just as Baker is a son of Fidelity), have holdings in AMD, and in fact, AMD is the largest holding Atreides according to filings, with Pure Storage coming in a close second. The Atreides portfolio weighs in at $3.6 billion in assets, including stakes in Google, Nvidia, Amazon, Meta Platforms, and investments in SpaceX, Tesla, Mythic AI, Positron, Electric AI, XSight Labs, and DriveNets, Atreides was also part of the consortium that Elon Musk put together to try to buy OpenAI for $97.4 billion back in February of this year. For all we know, Cerebras might be the largest single stake Atreides has right now.
Fidelity is a big investor in OpenAI, Anthropic, CoreWeave, Databricks, and SpaceX, among many, many others.
The AMD hook is significant as it looks like Fidelity and Atreides are hedging their AI bets. The founders of Cerebras spent some time after selling their SeaMicro microserver startup to AMD back in March 2012 for $334 million. AMD spiked the SeaMicro server fabric and systems business three years later, and Andrew Feldman, Sean Lie, Gary Lauterbach, Michael James, and Jean-Philippe Fricker decided to take on the waferscale chip challenge that none other than IBM System/360 mainframe architect Gene Amdahl took on way back in 1980 with Trilogy Systems.
Trilogy Systems was able to raise an incredible $230 million back in the early 1980s – that is just shy of $1 billion if you adjust that for inflation, and set records for Silicon Valley fundraising. By the time that this waferscale pioneer went public in 1984, raising another $60 million, it manufacturing processes were not yielding and other chip design and manufacturing techniques rode Moore’s Law up to better price/performance. Trilogy Systems was a case study in tech optimism and rapid failure in the early days of Silicon Valley, and Cerebras does not want to repeat any of its history even if it does want to commercialize what Gene Amhahl tried to build four and a half decades ago. (He went on to build a successful clone mainframe business, much to the chagrin of Big Blue, so if this doesn’t work out, maybe Cerebras will do a clean sheet GPU and take on AMD and Nvidia more directly.)
Taking The Wafer Up A Dimension
While the race is on by other XPU suppliers (including GPU makers Nvidia and AMD) to see how many reticle-limited chips (about 800 mm2 in area) they can put inside of a compute engine socket, going from one to two to four and maybe six or eight before the decade is out, Cerebras has been wafer-limited since its inception. The industry is stuck at wafers with a 300 mm diameter, because the dream of 450 mm wafers turns out to not be economically or technically practical. If Cerebras could move to 450 mm wafers, it could instantly boost the performance of its Wafer Scale Engines by 2.25X without any kind of process shrink.
Cerebras takes a circular wafer with a 300 mm diameter and squares the circle by cutting off four chords to get 46,225 mm2 of circuitry on a wafer. Here are how Cerebras has made use of this chip area for the past three generations of the Wafer Scale Engine:
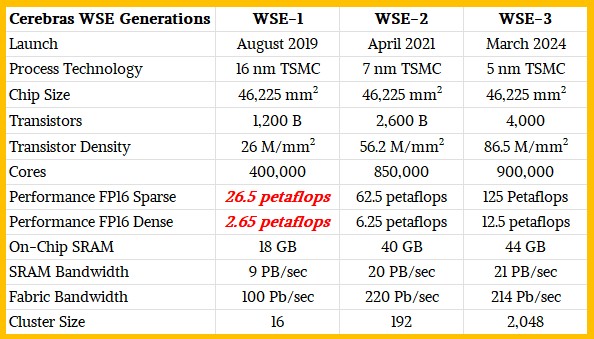
There is one WSE chip per system, and obviously you can gang up systems to scale up performance.
When the WSE-3 was announced, we praised the design for widening the compute and boosting the performance and doing only modest increases in on-chip SRAM bandwidth and capacity, but then the GenAI revolution happened and mixture of expert, test time reasoning models took off, driving up memory requirements because now instead of single shot, blurty answers, we now want to speed up the processing across dozens to hundreds of models that are activated within a larger collection of models that span all kinds of tasks.
This is why on many of its most recent inference tests, Cerebras was using two, three, or four systems to run its inference very fast – it didn’t need more compute, but it needed more SRAM memory to hold model weighs and parameters. At some point, Cerebras stopped telling us how many systems it was using to get its high inference throughput because, we think, it knows it needs more SRAM memory per wafer. We also think it needs to go vertical to add SRAM memory to the wafers with 3D stacking. You can stack up SRAM like AMD does with V-Cache across the top (as it does in its Epyc CPUs) or striping it across the bottom as it does with Infinity Cache with its Instinct GPUs. Cerebras could license both techniques and use them both to add SRAM to its WSE-4 engine, which is the hard scenario shown in the table below:

The WSE-4 Easy scenario puts more SRAM on the die and adds FP8 and FP4 processing to the SIMD engines on the Cerebras processing elements.
The WSE chips are really a whole lot of SRAM with some embedded processing, and we think there is a lot of redundancy built in. So most of the jump from 4 trillion transistors to 7 trillion transistors comes from the incremental cache. It looks like it is about 2.5 trillion transistors for 44 GB of usable cache, and there may be another spare 1 billion transistors in the cache and cores to boost yield. (Some circuits are duds, and if design so you can toss 20 percent away because of imperfections, you can get 80 percent yield and sell 100 percent of the product that was specified that way to the world, but the device has more stuff on it.)
So in our scenario where Cerebras has something like V-Cache and Infinity Cache added to the WSE-4 engine, we think it might have 12.7 trillion transistors more dedicated to that SRAM, and boost the SRAM memory per wafer to maybe something like 320 GB.
If we were going to put forth an WSE-4 Extreme scenario, we would integrate banks of HBM4 memory on the outside of the wafer, or use optical interconnects to create an optically linked, stacked memory Memory-X system to hold model weights and parameters, acting like an upper level cache for that SRAM on the wafer. (These optical interconnects would come off the top of the chip.) You want to get KV cache a lot more local for these models, and it has to be bigger, so maybe some fast NVM-Express flash needs to be piped in here optically, too. We like the idea of using microfluidics, like that created by IBM and Microsoft, to cool this. It would be cool to see water ribbons and light ribbons coming out of a stacked wafer.
And finally, whatever Cerebras is going to do, it needs to put out a roadmap that goes out to 2032 before it goes public. Nvidia put out a roadmap through 2028, and everyone knows the basic shape of the iron to come. Cerebras must do the same – and then some. That roadmap can be adapted as conditions dictate, as the advent of the long context-processing “Rubin CPX” chip that was not originally on the Nvidia roadmaps shows. You can always add, you can always change to intersect new technologies. People get that.

Sign up to our Newsletter
Featuring highlights, analysis, and stories from the week directly from us to your inbox with nothing in between.
Subscribe now


