.png)

At most companies, product development takes precedence over security.
It’s not that security is ignored; it just ends up being an afterthought.
After all, getting new features out the door is hard enough. You finally get budget approval, the team’s moving fast, and momentum feels great. Requests go in, requests go out. From a high level, everything seems good. The app is running, customers are happy, and investors see progress. This is a moment worth celebrating, but it’s also the moment when cracks start to form.
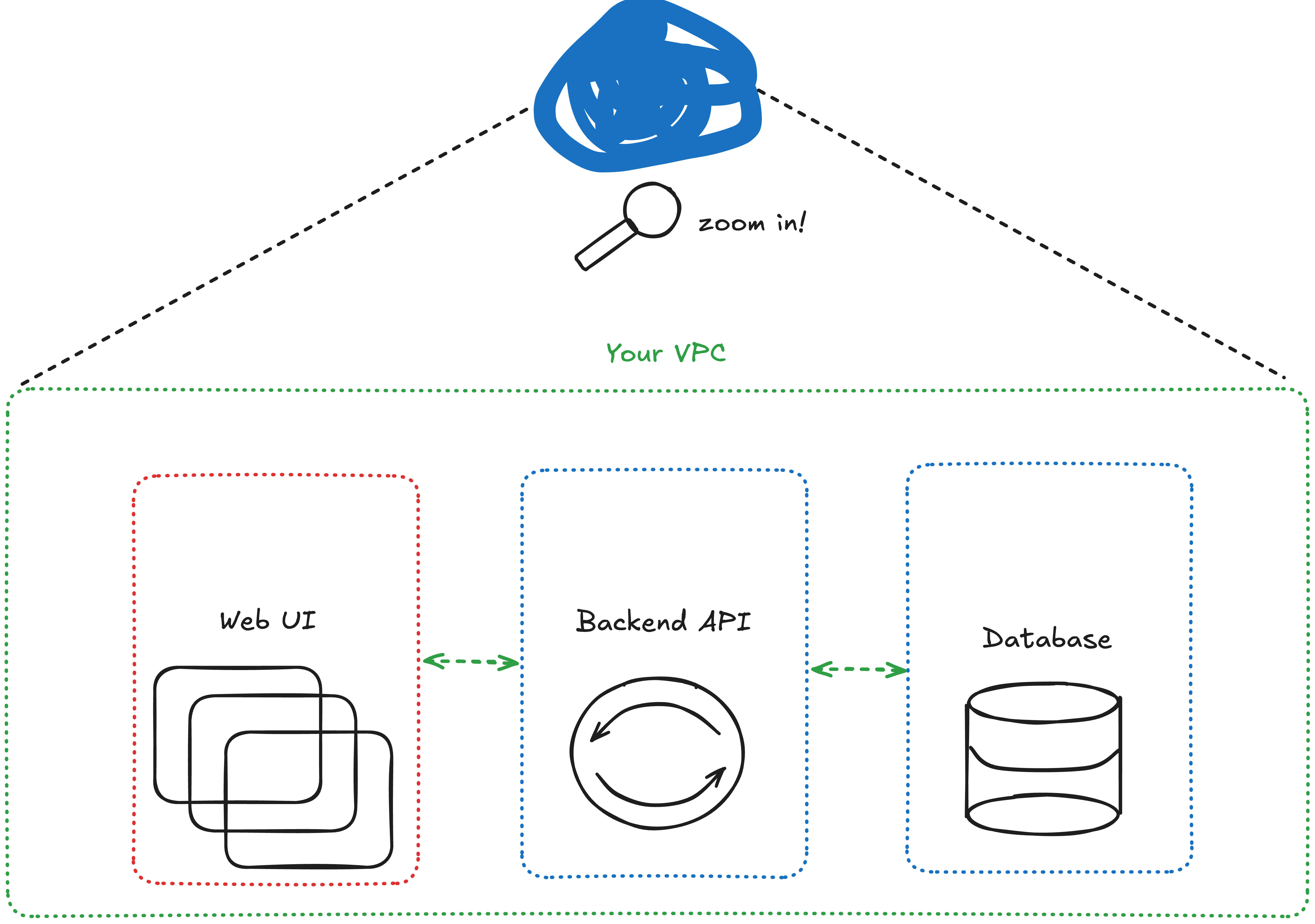
Every system looks simple from 10,000 feet away. A few boxes and arrows in an architecture diagram, a blue squiggly dot to represent “the cloud,” and it all seems under control.
But go one level deeper, and that simple system starts to branch out. APIs, databases, CI/CD pipelines, caches, queues, cloud services. Then you add users across multiple regions, new integrations, and a few different teams managing different layers. Suddenly, the mental model you started with no longer matches reality.
This is where security risk hides. The gap between how you think your system works and how it actually behaves.
Let’s say you’re running across AWS regions. Each region has:
Multiple instances of the same service
Separate network rules
Slightly different IAM roles
Distinct logging or monitoring setups
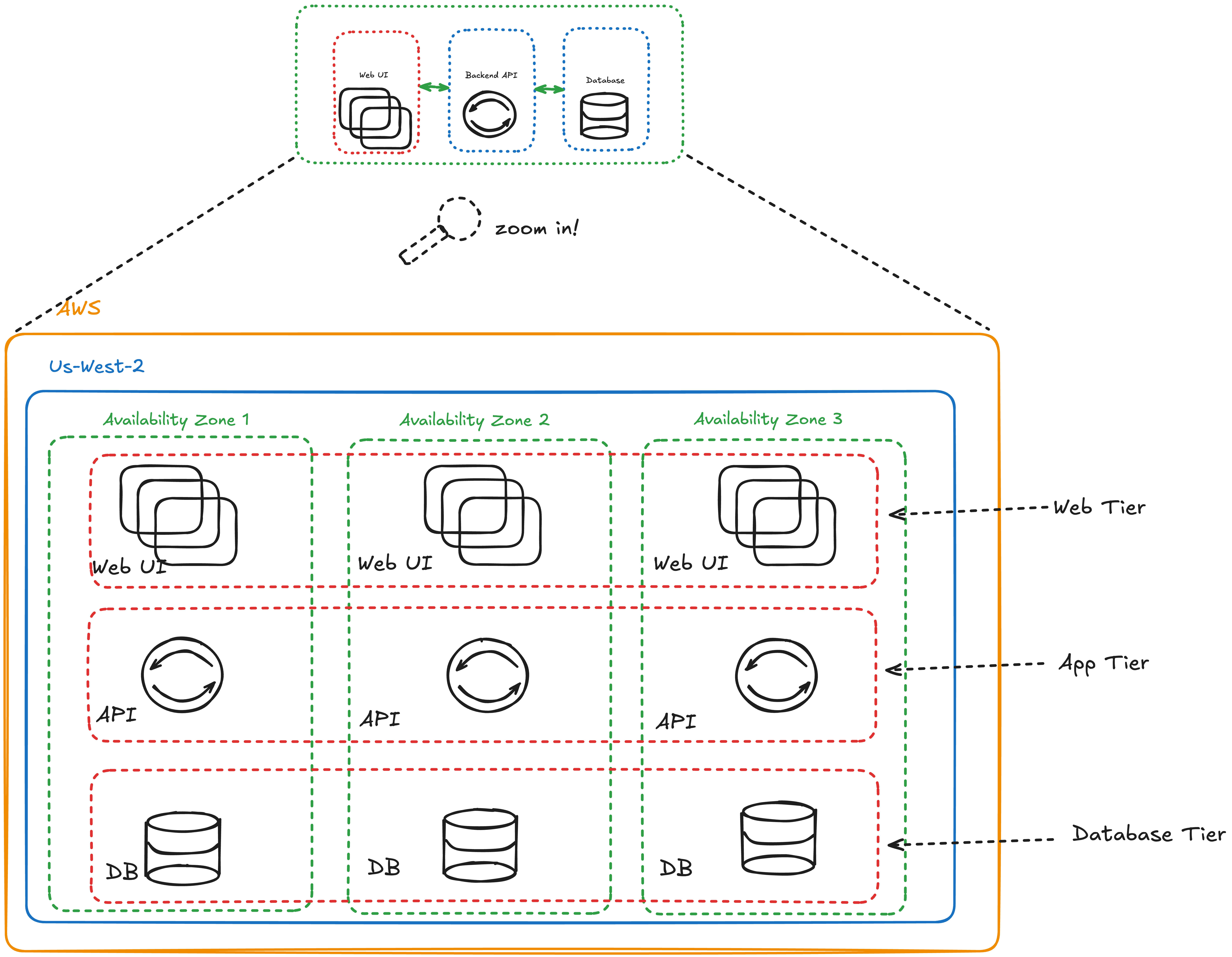
Now multiply that across environments (dev, test, prod), third-party dependencies, and CI/CD systems. Each “small difference” compounds.
At this stage:
Configuration drift starts to appear
Teams make manual fixes that aren’t tracked
Secrets end up in places they shouldn’t
Ownership becomes blurry
A good team knows the stack well. A great team documents, delegates, and builds visibility so the system isn’t just working, it’s understood.
A SaaS company I worked with once deployed a quick fix to improve performance. It passed testing, went live, and stakeholders were thrilled.
Two weeks later, an internal monitoring API was accidentally exposed to the public internet.
The root cause wasn’t the code. Iit was the process that broke down.
No one had double-checked the Terraform plan. No one checked the AWS IAM roles. The system worked, but it wasn’t safe.
You can’t secure what you don’t understand.
Security doesn’t start with firewalls or scanners. it starts with visibility and ownership.
Can you redeploy every component from scratch without manual intervention?
Who owns each piece of your infrastructure and can someone else find that out easily?
What’s your process for detecting configuration drift or failed deployments?
Are secrets, keys, and credentials managed the same way across regions?
Do you know what “normal” looks like in your system and what would signal a breach?
If you can’t answer all five, you’re not alone. Most companies can’t. But every step toward clarity reduces risk.
Security isn’t a blocker. It’s the measure of how well your team understands its own system.
When product teams slow down just enough to map their stack, automate the basics, and document ownership, they don’t just prevent incidents. They build trust with customers, partners, and themselves.


