.png)

In my opinion, the worst bugs are the ones you decide not to look further into.
Maybe the problem only manifests 2% of the time, or when you run the code on a particular brand of toaster. Maybe the customer doesn't supply enough information to begin narrowing down the cause. Maybe you just don't have enough time to track the issue down fully.
And everyone eventually moves on. But when you see the same bug strike again months later, you quietly mutter to yourself and wish you'd been persistent the first time. This is one of those stories.
The ClickPipes team had encountered a bug with logical replication slot creation on Postgres read replicas—specifically, an issue where a query that was already taking hours rather than the few seconds it usually took couldn’t be terminated by any of the usual methods in Postgres, causing customer frustration and risking the stability of production databases. In this blog post, I’ll walk through how I investigated the problem and ultimately discovered it was due to a Postgres bug. We’ll also share how we fixed it and our experience working with the Postgres community.
At ClickPipes, our charter is simple. Allow customers to easily move lots of data from <X> to ClickHouse Cloud, where X is an ever-growing set of object stores, queues, and databases. My team and I look after the database pipes. But before this, we were a startup named PeerDB, which made a product that moved lots of data from Postgres to <X> instead. By being Postgres-focused, the team had significant experience with Postgres CDC at scale.
For the uninitiated, change data capture (CDC) is the process of continuously tracking database changes, allowing ClickPipes to replicate them to ClickHouse in near real-time. Postgres performs change data capture (CDC) primarily through logical replication slots. Logical replication slots decode changes from the write-ahead log (WAL) and stream them to consumers for replay. They act as an intermediary layer, transforming raw WAL data into consumable change events. The Postgres ClickPipe is built around logical replication, creating slots and using them to read from hundreds of customer databases.
It all began when one of our biggest PeerDB customers pinged us, letting us know that they had set up a pipe to replicate data from their new Postgres read replica, but it appeared to have become "stuck." Keeping a few possibilities in mind, I pulled up their instance and saw nothing wrong—just a single active connection that was doing… something.
When creating a new pipe, one of the first steps is to create a logical replication slot. This typically takes a few seconds, but it was taking far longer here. We don't see any wait_event associated, which means Postgres thinks this command is not stuck waiting on anything. Additionally, we noticed the slot we're trying to create has shown up in the pg_replication_slots system table with an active PID.
After determining that the issue seemed to be on the Postgres side, one of our initial troubleshooting steps was to "turn it off and on again" and reset the pipe so it started afresh. Doing this led to an even more troubling discovery: even though the ClickPipe had disconnected, this rogue command wouldn't go away. We even used SQL commands to send SIGINT and SIGTERM signals to the backend process assigned to this query, but neither was taking effect. SIGTERM not taking effect is bad because that's supposed to be the "nuclear" option here.
We now had a replication slot marked as "active", and since the process connected to the slot refuses to quit, we cannot drop it. The slot was also now beginning to retain WAL for the decoding process, which is dangerous, as without a way to read from or drop the slot, it can continue retaining WAL indefinitely, risking storage exhaustion. As the customer was running a managed Postgres service, the only option they had to get out of this situation was to fully restart the Postgres instance to remove this process, which is not a very appealing proposition as it’d lead to downtime for things dependent on it.
As alluded to earlier, this is not the first time we have seen this exact problem. A few months earlier, another customer using a different managed Postgres service saw the same symptoms while creating a few pipes on a read replica. While we were not able to deterministically solve it, tuning some settings (like turning on hot_standby_feedback) seemed to make it go away, so we attributed it to some idiosyncrasy in their managed service (we now know that this was not the case). But it was worrying to see it in a completely different managed service on the latest Postgres version with all recommended settings. This was when I set aside time to investigate this further.
I got my first clue from support for the customer's Postgres provider, which was a strace output on the backend process running the broken query:
strace: Process 117778 attached restart_syscall(<... resuming interrupted nanosleep ...>) = 0 nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0 nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0 nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0 nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0 nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0 nanosleep({tv_sec=0, tv_nsec=1000000}, NULL) = 0 ...Seeing only nanosleep here and no IO or other syscalls would suggest that the backend is in a loop of sleep() calls with a constant duration of 1ms each. This was already a good clue since there are only a few places where such a loop exists in Postgres code. After finding a function in the control flow of creating replication slots that could sleep in this manner under certain conditions, I worked backwards to figure out what this function does and what can get it into this state. And while this bug is not that common in production databases, the "reproduction" of this issue is relatively trivial:
- Either set up or nicely ask a managed service to give you a Postgres cluster (v16+ since that's when standbys started supporting creation of logical replication slots) with a primary instance and a read replica.
- On the primary, start a transaction and perform any DML operation. As an optimization, Postgres only assigns transactions a transactionid/XID once they have written data, so this is to make the transaction "real". Don't COMMIT or ROLLBACK just yet; just leave the session open.
- On the read replica, create a logical replication slot (the most straightforward method would be to use the SQL function pg_create_logical_replication_slot). Once you issue the command, Ctrl-C becomes useless. Trying to cancel or terminate the backend from another session doesn't work either. If you read syscalls from the backend process via strace or similar, you'd see a lot of nanosleep syscalls like the one above.
- COMMIT/ROLLBACK the transaction from step 2. Doing this will eventually cause the slot creation to return successfully (if you tried to cancel it earlier, it will notice the attempt now and cancel itself).
Internally, creating a replication slot requires waiting for transactions before the slot creation query is issued to COMMIT/ROLLBACK, to reach a "consistent point" where the slot can decode all future transactions. While it is not ideal to have long-running transactions on Postgres for various reasons, the reality is that certain transactions (think reporting queries or large data backfills) can take a while. If we create a slot under these conditions, it will have to wait for transactions to complete and therefore take longer than usual.
2025-05-22 10:44:53.868 UTC [1195] LOG: 00000: logical decoding found initial starting point at 0/356B148 2025-05-22 10:44:53.868 UTC [1195] DETAIL: Waiting for transactions (approximately 1) older than 6068 to end.Since waiting on these older transactions can take an arbitrary amount of time, it is crucial to implement this wait as efficiently as possible. Postgres already handles various locks for different operations, and we can reuse this infrastructure to take a lock on older transactions. Since transactions only release their transactionid lock after completing, acquiring this lock confirms that the transaction is done. This approach provides visibility—system tables display active waits, allowing administrators to monitor progress.
If needed, one can cancel the problematic transactions or the slot creation process that’s still waiting. However, this holds only for a “typical” Postgres instance. As it turns out, being a Postgres read replica breaks some invariants, which leads to different behaviour in the same case.
While "read replica" is the colloquial term for a Postgres instance serving read-only traffic (a term that makes it seem more straightforward than it actually is), Postgres refers to these as "hot standbys". A hot standby is a Postgres instance in "recovery mode" that constantly receives WAL records from a primary Postgres instance and uses these to maintain an exact copy of all data on the primary. The relevant detail here is that the standby can only indirectly observe what transactions running on the primary are doing via the write-ahead log. Specifically, the standby continuously maintains a list of transactions running on the primary known as KnownAssignedXids based on information from incoming WAL records.
The function that implements the "wait for a transaction to complete" operation described earlier is named XactLockTableWait, and the crucial part for us is this loop (code simplified for brevity):
void XactLockTableWait(TransactionId xid, Relation rel, ItemPointer ctid, XLTW_Oper oper) <...> for (;;) { Assert(TransactionIdIsValid(xid)); SET_LOCKTAG_TRANSACTION(tag, xid); (void) LockAcquire(&tag, ShareLock, false, false); LockRelease(&tag, ShareLock, false); if (!TransactionIdIsInProgress(xid)) break; pg_usleep(1000L); } <...>Postgres acquires a lock on the transaction ID provided as input via LockAcquire, which hangs until the transaction completes and releases its lock. After obtaining the lock, we release it immediately and check if the transaction is still in progress via TransactionIdIsInProgress. If it isn't, we exit. However, there is a 1ms sleep before the loop repeats, which we hit if we find the transaction is still running. If we only reach the check after we acquire a lock, how can this happen? As mentioned in a comment within this function, there is a window where the transaction has registered itself as running but hasn't yet acquired its lock on the transactionid. While the code handles this case regardless, the sleep is good for avoiding repeated locking until the transaction reaches a consistent state. Under regular operation, this case should rarely be hit and not for very long.
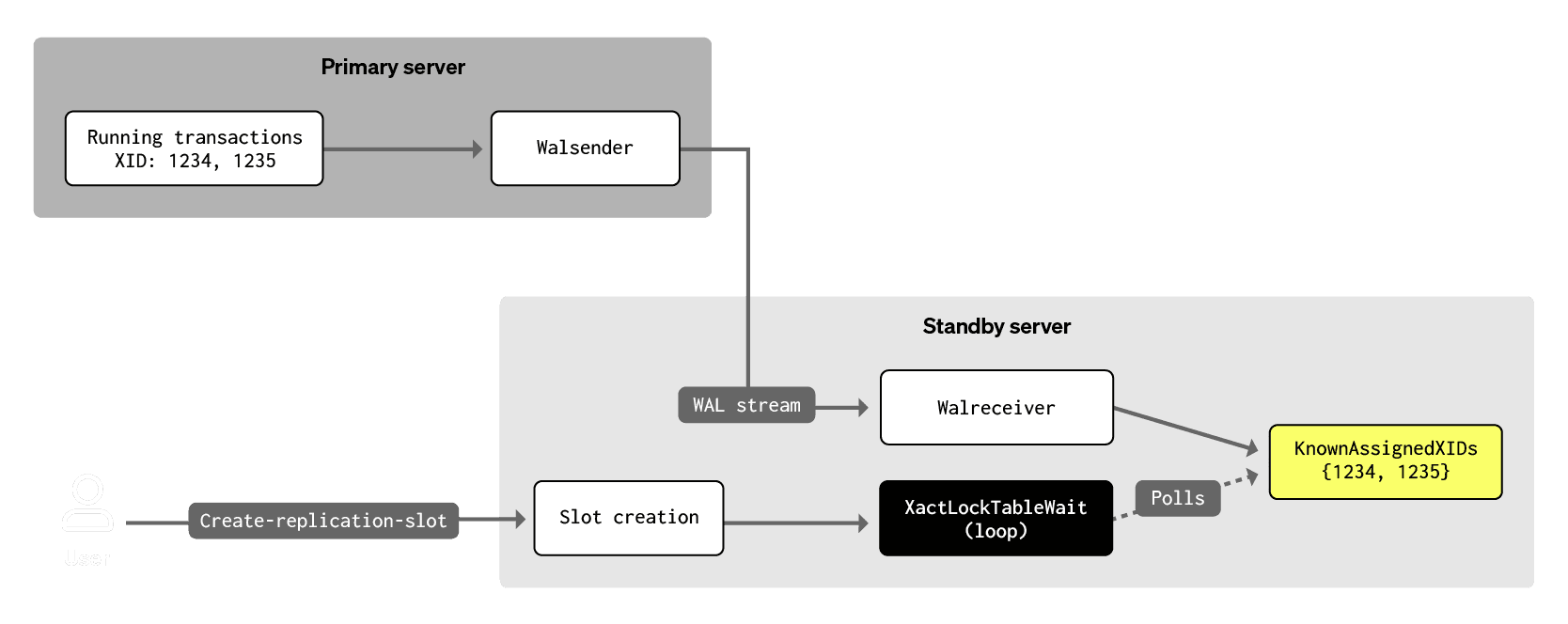
Let's now consider the case of a hot standby. A standby still needs to find a consistent point while creating a logical replication slot, and older transactions need to end for that. It isn't the one running the transaction; therefore, the LockAcquire will always return immediately on standby. But TransactionIdIsInProgress does take KnownAssignedXids into account, so we know that the transaction is still running. Thus, we hit the 1ms sleep and then another loop iteration. But unlike earlier, this is not a transient situation; we can be stuck here for hours.
- The optimized LockAcquire wait on the primary is replaced by a fixed 1ms polling loop that wastes cycles if we need to wait a long time.
- If LockAcquire needs to wait, it also handles interrupts. Since the function was designed around waiting in LockAcquire and the sleep case is for transient cases, there is no code for handling interrupts within the loop. This is what made the backend process "unkillable".
- We don't report that we're waiting on an external operation, as LockAcquire handled this. The only way a regular user can tell that their slot creation is stuck on this is to look at logs, which still mention the need to wait for older transactions to complete. On a primary, this same wait would be visible in system tables.
This issue is a good example of well-written code causing problems because it was unwittingly roped into handling something it was not designed for. This tends to happen in any codebase of sizable complexity.
Our immediate concern was that it was currently impossible to stop a slot creation waiting for a consistent point on a standby. To this effect, I submitted a patch to the Postgres mailing list, which just added an interrupt check before each sleep call:
+ CHECK_FOR_INTERRUPTS(); pg_usleep(1000L);Postgres maintainers quickly accepted this patch (thanks, Fujii Masao, for reviewing it!) and backported it to all supported major versions of Postgres. After a minor version upgrade, this problem should be mitigated for all users running hot standbys.
Another community member graciously addressed the issues around the lack of a wait_event here and the inefficient loop. A patch is out to add a new wait event that highlights this case, and there is also an ongoing discussion about improving the way standbys wait for transactions to complete on the primary. Both these changes are still in flight and should hopefully make it to Postgres 19 next year.
Once the ClickPipes team understood that this issue was not a one-off case, it took me a day or two to determine the RCA and develop the patch that addresses it. Being familiar with the Postgres codebase, its well-structured nature allowed me to hone in on XactLockTableWait() and work backwards. While the Postgres community has an older and sometimes daunting contribution process of submitting patches to a mailing list, they were also instrumental in reviewing the patch soon and getting it backported, continuing to ensure a high-quality user experience.
This investigation into a seemingly simple bug reveals the incredible depth and complexity that lie beneath the surface of modern database systems. Postgres, with decades of development and its battle-tested architecture, still harbors edge cases where different subsystems can interact with each other in unexpected ways. Similarly, ClickHouse, with its columnar storage engine and rich feature set, also presents fascinating challenges in pushing the boundaries of analytical performance. As both databases are open source, it’s easier to identify issues like this, fix them, and submit your patches upstream, repaying your debt to a system that has served you well.
Replicating data from PostgreSQL to ClickHouse unlocks columnar storage performance, parallel query execution, and advanced time-series analytics, enabling workloads that would be impractical or impossible on row-based transactional systems. We recommend ClickPipes for Postgres for ClickHouse Cloud users, offering managed real-time replication with zero infrastructure overhead. Self-hosted ClickHouse users should consider PeerDB, which provides high-performance self-hosted CDC capabilities. Both solutions work seamlessly with Postgres read replicas for CDC operations, allowing you to offload replication traffic from your primary database.


