.png)


I've been writing code for over a decade now, and if there's one thing that's consistently made my programs more reliable, readable, and maintainable, it's adopting functional programming principles. And I’m not talking about writing everything in some obscure language that no one uses. I spend most of my time in Python and R, languages that aren't traditionally "functional", but I've found that thinking functionally has transformed how I approach problems and architect solutions.
Even in our current AI-powered reality where we're supposedly writing less code than ever, the code we do write needs to be cleaner, more maintainable, and easier to reason about. The thing is though: even as AI tools become more sophisticated, the ability to reason about code structure, debug complex systems, and make architectural decisions remains fundamentally human. Good programming practices aren't just about writing code, they're about understanding it, maintaining it, and building systems that don't collapse under their own weight.
When I started coding, the programming landscape looked very different. C++, Java, and C# were the "serious" languages that real software engineers used and considered the undisputed kings of enterprise development. Object-oriented programming wasn't just a paradigm; it was the paradigm, marketed as the silver bullet for software complexity. If you weren't thinking in classes, SOLID design principles, and UML diagrams, you weren't really programming.
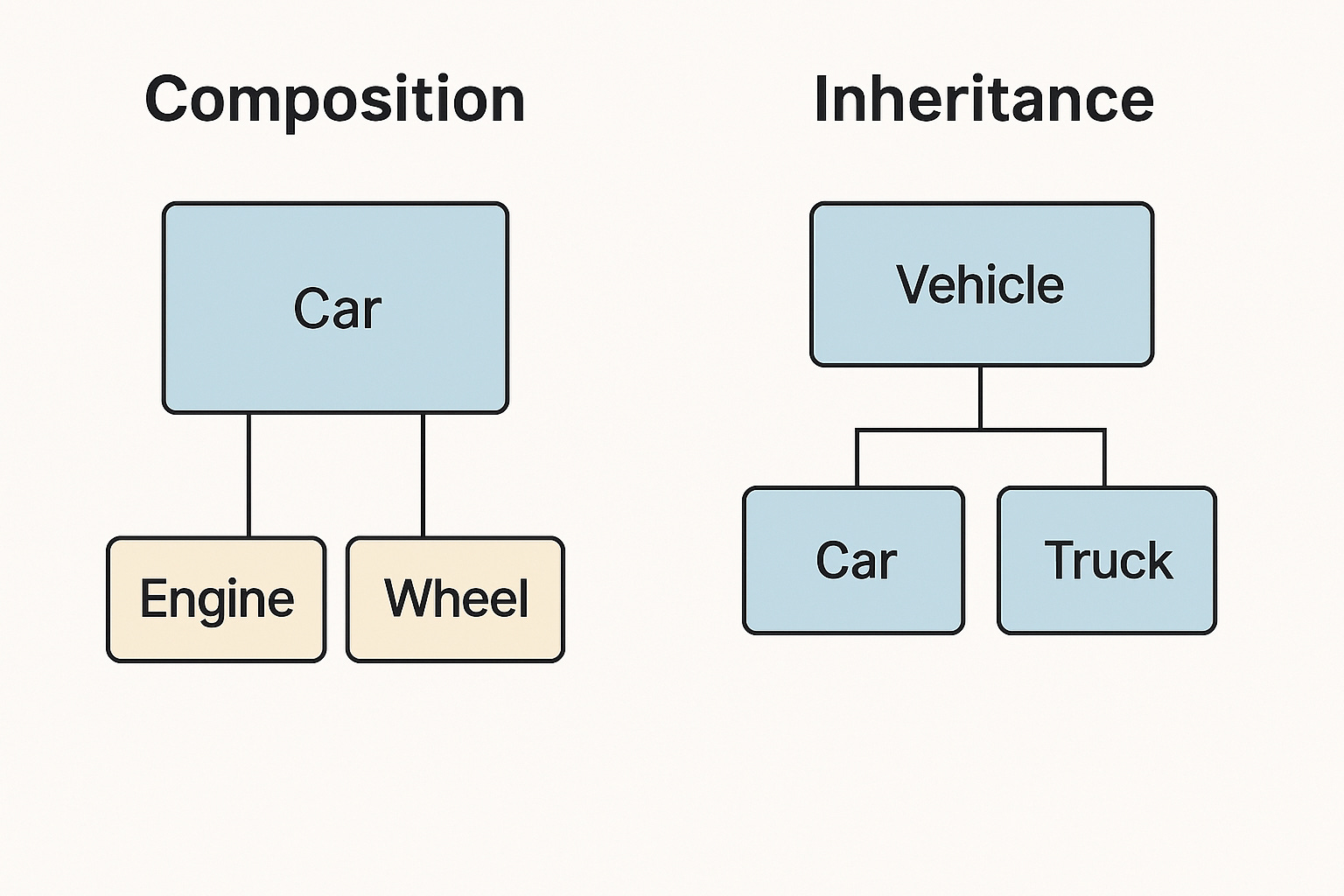
This dominance wasn't accidental. When OOP burst onto the scene 30-40 years ago, it promised to solve the chaos of procedural programming. Until this point, most programs were collections of functions and scripts duct-taped together, often resulting in what we now call "spaghetti code". OOP offered a compelling alternative: organize your code around real-world concepts. Create a Vehicle class, inherit from it to make Car and Motorcycle classes, encapsulate data and behavior together, and voilà — your code would mirror the real world in elegant, maintainable ways.
The OOP evangelists promised us:
Encapsulation: Hide complexity behind clean interfaces
Inheritance: Reuse code through hierarchical relationships
Polymorphism: Write flexible code that works with different types
Modularity: Build systems from interchangeable components
On paper, it sounded revolutionary. In practice? Well, anyone who's worked on a large OOP codebase knows it’s not that simple.
This post is not a dig at OOP; in fact, I think it has some real benefits. Encapsulation does help organize complex systems. Inheritance can reduce code duplication when used judiciously. Polymorphism enables powerful abstractions. But somewhere along the way real-world turned out to be more complex than the textbooks suggested.
Instead of elegant class hierarchies, we got sprawling inheritance trees that nobody could navigate. The promise of reusability often led to over-engineering, where adding a single feature meant modifying six different classes across three different modules.
The "real world modeling" that seemed so intuitive often led to bizarre abstractions. Is a DatabaseConnectionPool really modeling something from the physical world? What about AbstractSingletonProxyFactoryBean? (Yes, that's a real class name from the Spring Framework.)
The biggest problems emerge in production scenarios:
Class explosion: Hundreds of tiny classes in convoluted hierarchies.
Leaky abstractions: Hidden state and side effects that make it impossible to understand what your code is doing without tracing object interactions through layers of factories and service locators.
Rigid structures: Changing one class signature can cascade through dozens of dependent classes, turning a small refactor into something that might take days.
Functional programming sometimes gets a bad rep for being too abstract or mathy. In part because a lot of people are first introduced to it in a CS course, probably through Haskell. The professor likely starts with category theory, throws around terms like "monads" and "functors," and makes jokes about how "a monad is just a monoid in the category of endofunctors". By the time you get to "practical" examples, half the class has mentally checked out.

The truth, though, is much more encouraging and practical than the academic presentation suggests. You don't need to understand the mathematical foundations of lambda calculus to benefit enormously from FP (though it helps). Most modern languages like Python, JavaScript, C#, and even Java have been quietly incorporating functional features for years. You can start writing more functional code tomorrow without throwing away your existing tech stack.
But here's what nobody told me back then: I was already using functional programming concepts without knowing it. Every time I used JavaScript's map() function, composed functions that did one thing together, or tried to avoid global variables, I was thinking functionally.
Let me walk you through some of the most practical and immediately useful FP concepts that you can start applying regardless of which language you're currently working in. Think of these as tools that you can gradually add to your toolkit, rather than a complete philosophical overhaul of how you approach software development.
Imagine you need to process a list of customer orders for an e-commerce system. In a traditional object-oriented approach, you might create an OrderProcessor class with methods for each step: validateOrder(), calculateTotal(), applyDiscounts(), and updateInventory(). The problem is that these methods become tightly coupled to the class and each other, making it difficult to test individual pieces or reuse the logic in different contexts.
A functional approach would break this down into separate, focused functions. One for filtering valid orders, another for calculating totals, a third for applying discounts, and so on. These functions can then be composed together like building blocks to create the complete order processing pipeline. Want to process orders differently for premium customers? Swap out the discount calculation function. Need to test the total calculation logic? You can test that function in complete isolation without worrying about the rest of the pipeline.
This approach creates code that's easier to test because you can verify each small function independently, easier to understand because each function has one clear purpose, and easier to modify because you can swap out or recombine pieces without affecting the entire system.
Another core tenet of FP is that you can’t (or shouldn’t) change your data. But then how do you get anything done? Consider the difference between modifying an array in place versus creating a new array with your changes. When you modify data in place, you lose the ability to compare before and after states, which makes debugging significantly more difficult. You also risk unexpected changes propagating through your system when multiple parts of your code hold references to the same data structure.
Immutable data structures provide several concrete advantages in real-world programming scenarios. You never have to worry about whether a function might secretly modify data you pass to it as an argument. You can cache results confidently because you know the inputs won't change behind your back, invalidating your cached values. Parallel processing becomes dramatically safer because multiple threads can work with the same data without any coordination or locking mechanisms.
This concept recognizes that functions can be treated just like any other data type. You can pass them as arguments to other functions, return them as results, and store them in variables or data structures. This flexibility unlocks powerful patterns for code reuse and abstraction that can make your programs both more concise and more expressive.
These higher-order functions let you express complex data processing pipelines in a clear, readable way that closely matches how you might describe the operations in natural language. Instead of nested loops with temporary variables and complex state management, you get a chain of transformations that reads almost like a step-by-step description of what you want to accomplish.
Despite compelling advantages, FP has taken decades to gain mainstream traction in commercial software development, and understanding the reasons helps explain both the historical resistance and the current momentum toward adoption.
Developers who have spent years thinking in terms of objects, classes, and mutable state need time to internalize a fundamentally different approach to problem-solving. Another factor is the influence of established codebases and team practices that make it difficult to introduce new approaches incrementally. There has also been a persistent perception that FP is inherently less performant than imperative alternatives, though modern hardware and runtime improvements have largely eliminated this concern.
Every major programming language has been incorporating functional features because the benefits have proven too significant to ignore in practice. C# added lambda expressions, LINQ, and immutable collections. Java introduced streams, functional interfaces, and optional types. Python's functools modules provide powerful functional programming utilities that many developers use without even thinking of them as "functional programming."
This convergence reflects a growing recognition that FP solves real, persistent problems that plague modern software systems.
FP complements OOP and procedural approaches, so there’s no need abandon everything you know until to this point. Instead, we're adding powerful new tools to your toolkit that will make you a more effective developer, regardless of which languages you work with or which domains you tackle.
Subscribe (it’s free) and stay tuned for part two, where we'll get hands-on with functional programming in Python and see how these concepts translate into cleaner, more maintainable code.

![New 'ghost tapping' scam warning: How to protect yourself [video]](https://www.youtube.com/img/desktop/supported_browsers/firefox.png)
