.png)

Does it really need to be this complicated?
What if we stripped everything away?
Your LLM Framework Only Needs
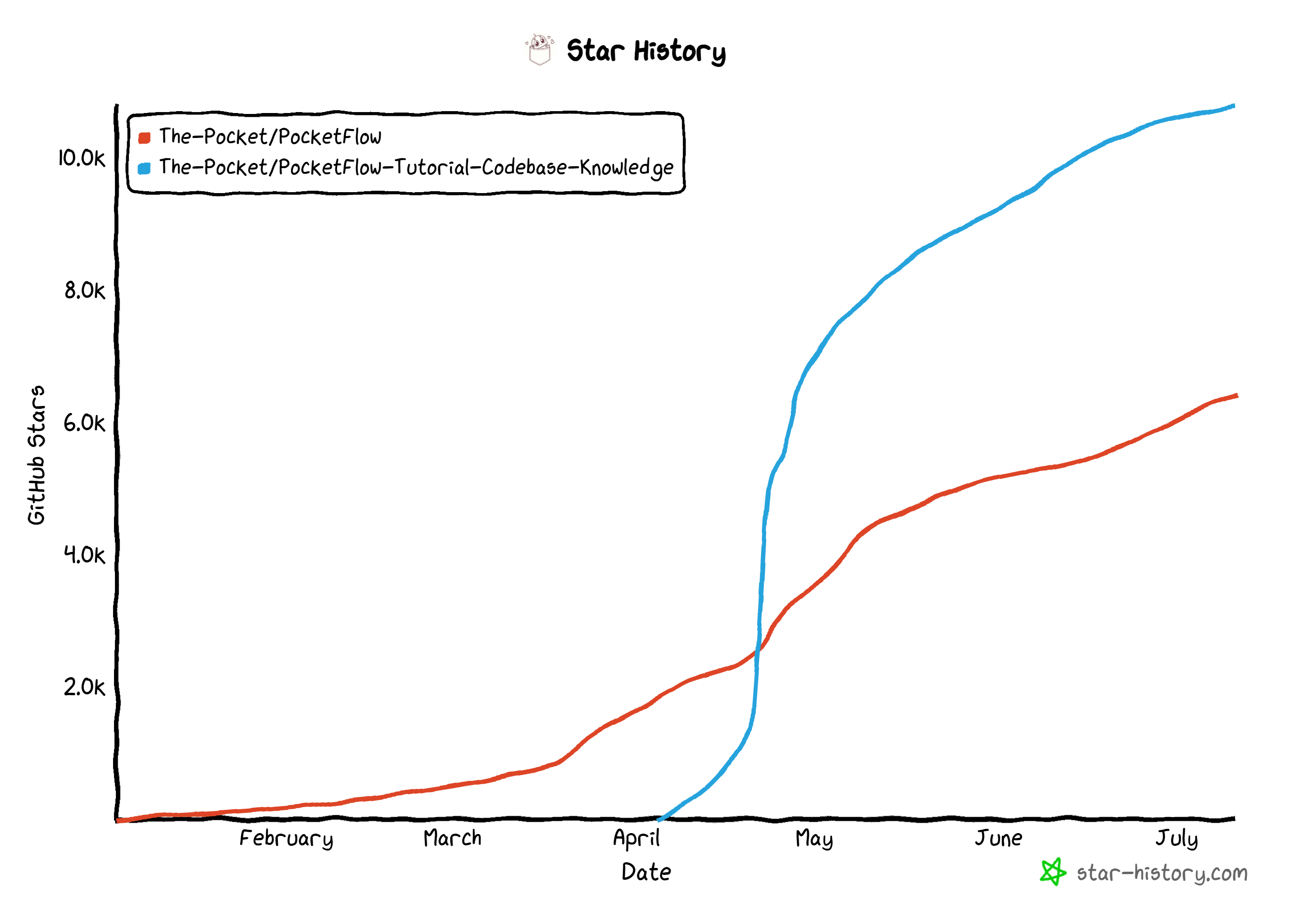
https://github.com/The-Pocket/PocketFlow
import asyncio, warnings, copy, time class BaseNode: def __init__(self): self.params,self.successors={},{} def set_params(self,params): self.params=params def next(self,node,action="default"): if action in self.successors: warnings.warn(f"Overwriting successor for action '{action}'") self.successors[action]=node; return node def prep(self,shared): pass def exec(self,prep_res): pass def post(self,shared,prep_res,exec_res): pass def _exec(self,prep_res): return self.exec(prep_res) def _run(self,shared): p=self.prep(shared); e=self._exec(p); return self.post(shared,p,e) def run(self,shared): if self.successors: warnings.warn("Node won't run successors. Use Flow.") return self._run(shared) def __rshift__(self,other): return self.next(other) def __sub__(self,action): if isinstance(action,str): return _ConditionalTransition(self,action) raise TypeError("Action must be a string") class _ConditionalTransition: def __init__(self,src,action): self.src,self.action=src,action def __rshift__(self,tgt): return self.src.next(tgt,self.action) class Node(BaseNode): def __init__(self,max_retries=1,wait=0): super().__init__(); self.max_retries,self.wait=max_retries,wait def exec_fallback(self,prep_res,exc): raise exc def _exec(self,prep_res): for self.cur_retry in range(self.max_retries): try: return self.exec(prep_res) except Exception as e: if self.cur_retry==self.max_retries-1: return self.exec_fallback(prep_res,e) if self.wait>0: time.sleep(self.wait) class BatchNode(Node): def _exec(self,items): return [super(BatchNode,self)._exec(i) for i in (items or [])] class Flow(BaseNode): def __init__(self,start=None): super().__init__(); self.start_node=start def start(self,start): self.start_node=start; return start def get_next_node(self,curr,action): nxt=curr.successors.get(action or "default") if not nxt and curr.successors: warnings.warn(f"Flow ends: '{action}' not found in {list(curr.successors)}") return nxt def _orch(self,shared,params=None): curr,p,last_action =copy.copy(self.start_node),(params or {**self.params}),None while curr: curr.set_params(p); last_action=curr._run(shared); curr=copy.copy(self.get_next_node(curr,last_action)) return last_action def _run(self,shared): p=self.prep(shared); o=self._orch(shared); return self.post(shared,p,o) def post(self,shared,prep_res,exec_res): return exec_res class BatchFlow(Flow): def _run(self,shared): pr=self.prep(shared) or [] for bp in pr: self._orch(shared,{**self.params,**bp}) return self.post(shared,pr,None) class AsyncNode(Node): async def prep_async(self,shared): pass async def exec_async(self,prep_res): pass async def exec_fallback_async(self,prep_res,exc): raise exc async def post_async(self,shared,prep_res,exec_res): pass async def _exec(self,prep_res): for i in range(self.max_retries): try: return await self.exec_async(prep_res) except Exception as e: if i==self.max_retries-1: return await self.exec_fallback_async(prep_res,e) if self.wait>0: await asyncio.sleep(self.wait) async def run_async(self,shared): if self.successors: warnings.warn("Node won't run successors. Use AsyncFlow.") return await self._run_async(shared) async def _run_async(self,shared): p=await self.prep_async(shared); e=await self._exec(p); return await self.post_async(shared,p,e) def _run(self,shared): raise RuntimeError("Use run_async.") class AsyncBatchNode(AsyncNode,BatchNode): async def _exec(self,items): return [await super(AsyncBatchNode,self)._exec(i) for i in items] class AsyncParallelBatchNode(AsyncNode,BatchNode): async def _exec(self,items): return await asyncio.gather(*(super(AsyncParallelBatchNode,self)._exec(i) for i in items)) class AsyncFlow(Flow,AsyncNode): async def _orch_async(self,shared,params=None): curr,p,last_action =copy.copy(self.start_node),(params or {**self.params}),None while curr: curr.set_params(p); last_action=await curr._run_async(shared) if isinstance(curr,AsyncNode) else curr._run(shared); curr=copy.copy(self.get_next_node(curr,last_action)) return last_action async def _run_async(self,shared): p=await self.prep_async(shared); o=await self._orch_async(shared); return await self.post_async(shared,p,o) async def post_async(self,shared,prep_res,exec_res): return exec_res class AsyncBatchFlow(AsyncFlow,BatchFlow): async def _run_async(self,shared): pr=await self.prep_async(shared) or [] for bp in pr: await self._orch_async(shared,{**self.params,**bp}) return await self.post_async(shared,pr,None) class AsyncParallelBatchFlow(AsyncFlow,BatchFlow): async def _run_async(self,shared): pr=await self.prep_async(shared) or [] await asyncio.gather(*(self._orch_async(shared,{**self.params,**bp}) for bp in pr)) return await self.post_async(shared,pr,None)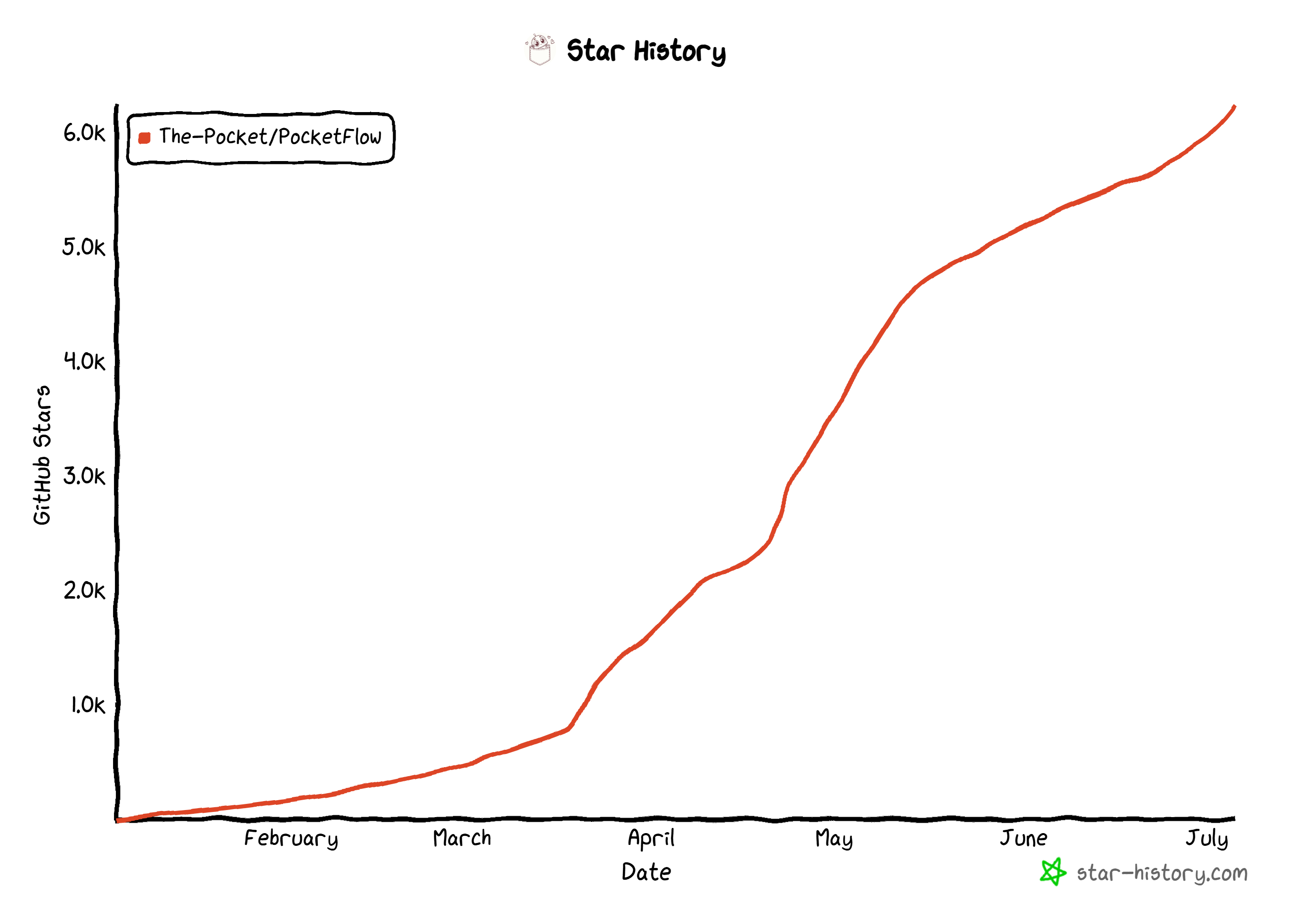
| LangChain | Agent, Chain | Many (e.g., QA, Summarization) |
Many (e.g., OpenAI, Pinecone, etc.) |
405K | +166MB |
| CrewAI | Agent, Chain | Many (e.g., FileReadTool, SerperDevTool) |
Many (e.g., OpenAI, Anthropic, Pinecone, etc.) |
18K | +173MB |
| SmolAgent | Agent | Some (e.g., CodeAgent, VisitWebTool) |
Some (e.g., DuckDuckGo, Hugging Face, etc.) |
8K | +198MB |
| LangGraph | Agent, Graph | Some (e.g., Semantic Search) |
Some (e.g., PostgresStore, SqliteSaver, etc.) |
37K | +51MB |
| AutoGen | Agent | Some (e.g., Tool Agent, Chat Agent) |
Many [Optional] (e.g., OpenAI, Pinecone, etc.) |
7K (core-only) |
+26MB (core-only) |
| PocketFlow | Graph | None | None | 100 | +56KB |
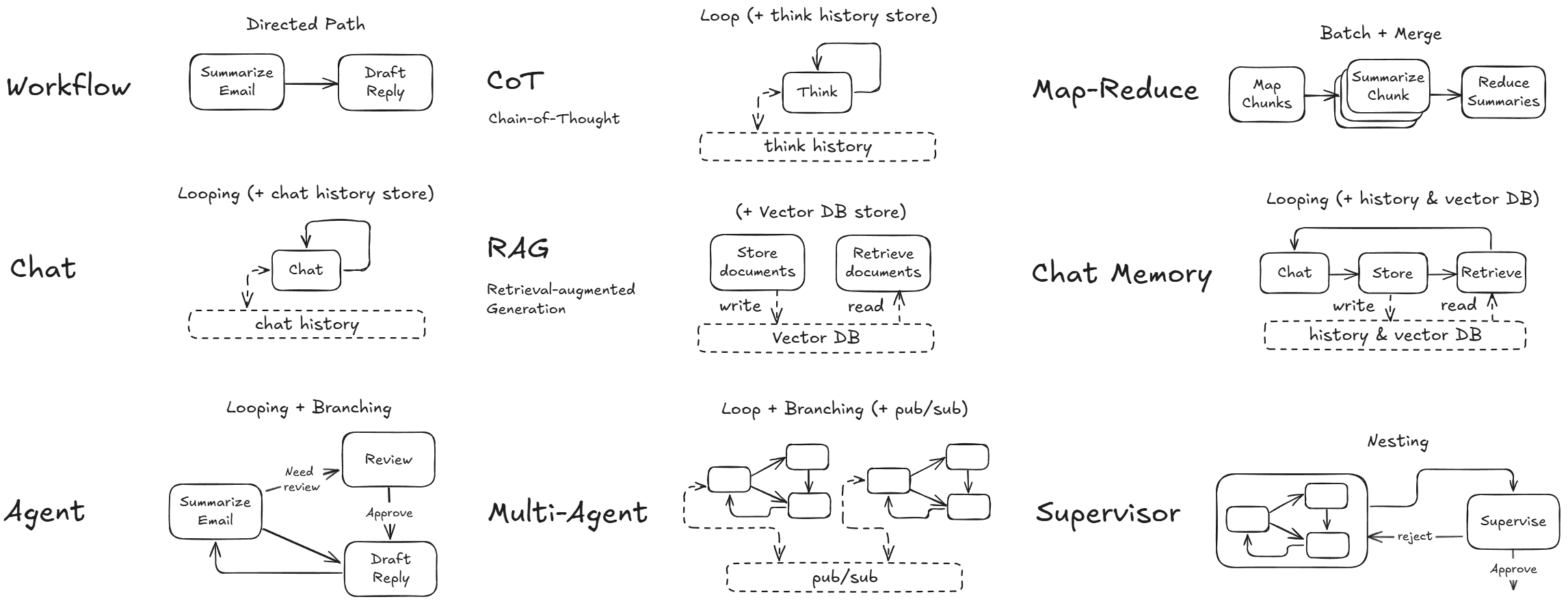
You will learn how agents ACTUALLY work.
You will learn how RAG is REALLY built.
You will learn from THE GROUND UP.
If you know a little bit of Python.
You're ready.
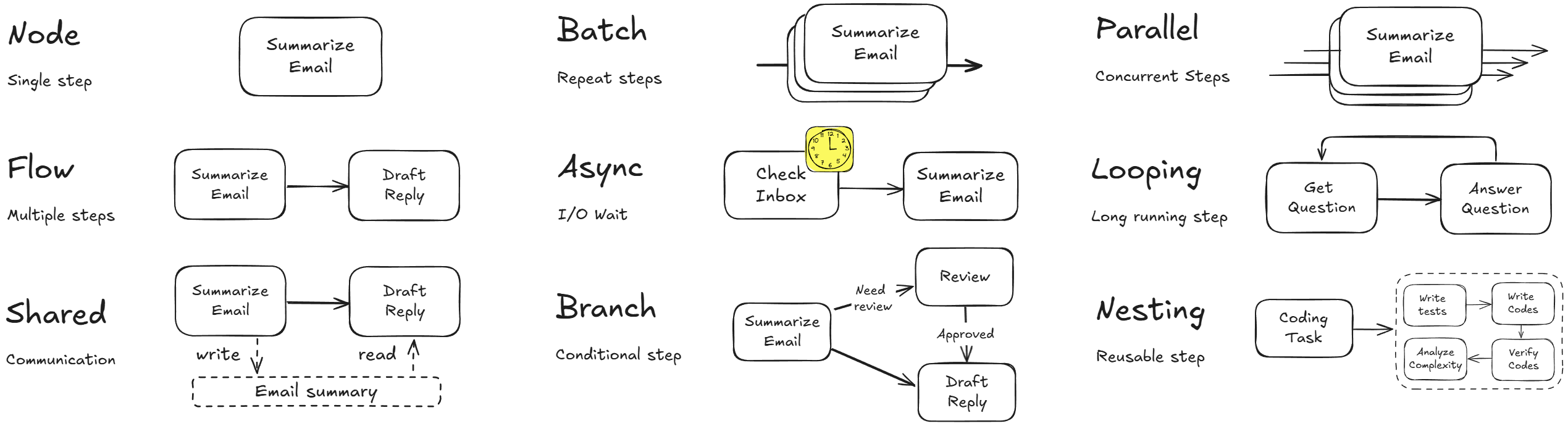
The Node • The Shared Store • The Flow
prep: Reads from shared store to get ready.
exec: Performs the core task in isolation.
post: Writes results back and returns an 'action' string for the next Node.
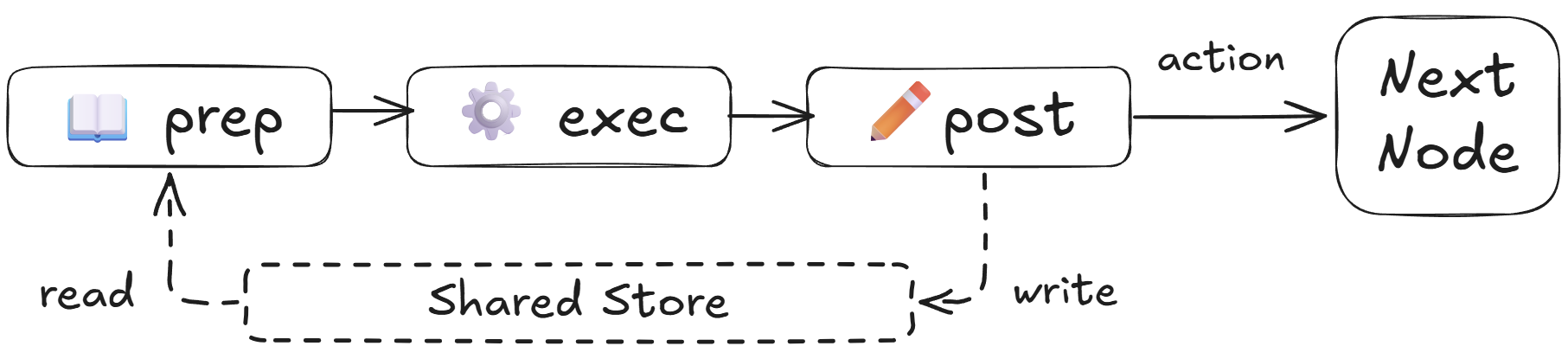
The Node • The Shared Store • The Flow
{ }
The Node • The Shared Store • The Flow
%%{init: {'theme': 'dark'}}%% graph LR A[Node A] --> B[Node B]
# A simple, default transition node_a >> node_b%%{init: {'theme': 'dark'}}%% graph TD A[Review Node] -->|approved| B[Payment Node] A -->|rejected| C[Finish Node]
# Named transitions for branching logic review_node - "approved" >> payment_node review_node - "rejected" >> finish_node%%{init: {'theme': 'dark'}}%% graph LR subgraph Flow A[Node A] --> B[Node B] end Flow --> C[Node C]
This allows for powerful, nested workflows.
No OpenAI. No Anthropic. No Google.
%%{init: {'theme': 'dark'}}%% graph LR subgraph B[LLM Framework] A[LLM API] end C[You] --> B
Maintenance Nightmare
from openai import OpenAI import os def call_llm(messages): client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY")) response = client.chat.completions.create( model="gpt-4o", messages=messages ) return response.choices[0].message.contentWrite the function yourself!
%%{init: {'theme': 'dark'}}%% graph LR chat[ChatNode] -- "continue" --> chat
A chatbot is just a self-loop.
class ChatNode(Node): def prep(self, shared): # Initialize messages if this is the first run if "messages" not in shared: shared["messages"] = [] print("Welcome to the chat!") # Get user input user_input = input("\nYou: ") # Add user message to history shared["messages"].append({"role": "user", "content": user_input}) # Return all messages for the LLM return shared["messages"] def exec(self, messages): # Call LLM with the entire conversation history response = call_llm(messages) return response def post(self, shared, prep_res, exec_res): # Print the assistant's response print(f"\nAssistant: {exec_res}") # Add assistant message to history shared["messages"].append({"role": "assistant", "content": exec_res}) # Loop back to continue the conversation return "continue" # Create the flow with self-loop chat_node = ChatNode() chat_node - "continue" >> chat_node flow = Flow(start=chat_node) # Start the chat if __name__ == "__main__": shared = {} flow.run(shared)%%{init: {'theme': 'dark'}}%% graph TD prep["prep()"] --> exec["exec()"] --> post["post()"]
%%{init: {'theme': 'dark'}}%% graph TD style prep fill:#4CAF50,stroke:#333 prep["prep()"] --> exec["exec()"] --> post["post()"]
%%{init: {'theme': 'dark'}}%% graph TD style exec fill:#4CAF50,stroke:#333 prep["prep()"] --> exec["exec()"] --> post["post()"]
%%{init: {'theme': 'dark'}}%% graph TD style post fill:#4CAF50,stroke:#333 prep["prep()"] --> exec["exec()"] --> post["post()"]
What you WANT
name: Jane Doe email: [email protected]What you GET
"Certainly! The name mentioned in the document is Jane Doe, and you can find her email at [email protected]."JSON - Fragile
{ "dialogue": "Alice said: \"Hello Bob.\\nHow are you?\"" }escaping
YAML - Robust
dialogue: | Alice said: "Hello Bob. How are you?"no escaping
Before
!! JOHN SMTIH !! contact: 123-456-7890. email me at [email protected] Work Experience: - at ABC Corportaion i was the SALES MANAGER - XYZ Industries, position: ASST. MANAGERAfter
# The clean, structured data { "name": "JOHN SMTIH", "email": "[email protected]", "experience": [ {"title": "SALES MANAGER", "company": "ABC Corportaion"}, {"title": "ASST. MANAGER", "company": "XYZ Industries"} ] }Solution: The BatchNode
Standard Node
class Node: # Returns one item to process def prep(self, shared): return one_item # Processes one item def exec(self, one_item): return one_result # Receives one result def post(self, shared, prep_res, exec_res): passBatchNode
class BatchNode(Node): # Returns a LIST of items def prep(self, shared): return [item1, item2, item3] # Processes ONE item at a time def exec(self, one_item_from_list): return one_result # Receives a LIST of all results def post(self, shared, prep_res, exec_res_list): passSolution: The BatchNode
Standard Node
class Node: # Returns one item to process def prep(self, shared): return one_item # Processes one item def exec(self, one_item): return one_result # Receives one result def post(self, shared, prep_res, exec_res): passBatchNode
class BatchNode(Node): # Returns a LIST of items def prep(self, shared): return [item1, item2, item3] # Processes ONE item at a time def exec(self, one_item_from_list): return one_result # Receives a LIST of all results def post(self, shared, prep_res, exec_res_list): passSolution: The BatchNode
Standard Node
class Node: # Returns one item to process def prep(self, shared): return one_item # Processes one item def exec(self, one_item): return one_result # Receives one result def post(self, shared, prep_res, exec_res): passBatchNode
class BatchNode(Node): # Returns a LIST of items def prep(self, shared): return [item1, item2, item3] # Processes ONE item at a time def exec(self, one_item_from_list): return one_result # Receives a LIST of all results def post(self, shared, prep_res, exec_res_list): passSolution: The BatchNode
Standard Node
class Node: # Returns one item to process def prep(self, shared): return one_item # Processes one item def exec(self, one_item): return one_result # Receives one result def post(self, shared, prep_res, exec_res): passBatchNode
class BatchNode(Node): # Returns a LIST of items def prep(self, shared): return [item1, item2, item3] # Processes ONE item at a time def exec(self, one_item_from_list): return one_result # Receives a LIST of all results def post(self, shared, prep_res, exec_res_list): passThe Implementation: Dumb Simple
class BatchNode(Node): # This is the entire implementation. def _exec(self, items): # It's just a simple for loop. return [super(BatchNode, self)._exec(i) for i in (items or [])] class BatchResumeParserNode(BatchNode): def prep(self, shared): # Assumes a list of resumes is already in the shared store. return shared.get("resumes", []) def exec(self, resume_text): prompt = f"""Analyze the resume below. Output ONLY the requested information in YAML format. **Resume:** ``` {resume_text} ``` **YAML Output Requirements:** - Extract `name` (string). - Extract `email` (string). - Extract `experience` (list of objects). **Example Format:** ```yaml name: Jane Doe email: [email protected] experience: - title: Manager company: Corp A ``` Generate the YAML output now: """ response = call_llm(prompt) # A simple way to extract the YAML block from the response yaml_str = response.split("```yaml")[1].split("```")[0].strip() structured_result = yaml.safe_load(yaml_str) # Assertions to enforce the output structure assert "name" in structured_result, "Name is required" assert "email" in structured_result, "Email is required" return structured_result def post(self, shared, prep_res, all_results_list): # This runs only ONCE, after all items are processed. # It receives a list of all individual results. shared["all_parsed_resumes"] = all_results_listBatch Node Walkthrough
%%{init: {'theme': 'dark'}}%%
graph TD
A["prep():
returns [resume1, resume2, resume3]"] --> exec_loop
subgraph exec_loop ["_exec() loop"]
C["exec(resume1)"] --> E["exec(resume2)"] --> G["exec(resume3)"]
end
exec_loop --> H["post():
receives [result1, result2, result3]"]
%%{init: {'theme': 'dark'}}%% graph TD subgraph exec_loop ["_exec() loop"] C["exec(resume1)"] --> E["exec(resume2)"] --> G["exec(resume3)"] end
Total Time = Sum of All Tasks
%%{init: {'theme': 'dark'}}%% sequenceDiagram participant You participant LLM You->>LLM: Process Resume 1? activate LLM Note over You, LLM: 10+ seconds of waiting... LLM-->>You: Result 1 deactivate LLM You->>LLM: Process Resume 2? activate LLM Note over You, LLM: 10+ seconds of waiting... LLM-->>You: Result 2 deactivate LLM
5-20 seconds of pure, wasted time... per resume.
The Slow Chef
%%{init: {'theme': 'dark'}}%% graph TD A[Start Eggs] --> B[Wait for Eggs] B --> C[Serve Eggs] C --> D[Start Toast] D --> E[Wait for Toast] E --> F[Serve Toast]
The Smart Chef
%%{init: {'theme': 'dark'}}%% graph TD subgraph " " A[Start Eggs] --> B[Wait for Eggs] C[Start Toast] --> D[Wait for Toast] end B --> E[Serve Eggs] D --> F[Serve Toast]
async
A label for functions that might wait
await
Pause one task and let others run
Total Time = Time of Longest Task
Before - Synchronous
from openai import OpenAI import os def call_llm(messages): client = OpenAI(api_key=...) response = client.chat.completions.create( model="gpt-4o", messages=messages ) return response.choices[0].message.contentAfter - Asynchronous
from openai import AsyncOpenAI import os async def call_llm_async(messages): client = AsyncOpenAI(api_key=...) response = await client.chat.completions.create( model="gpt-4o", messages=messages ) return response.choices[0].message.contentBefore - BatchNode
# Before class BatchResumeParserNode(BatchNode): def prep(self, shared): return shared.get("resumes", []) def exec(self, one_resume_text): ... response = call_llm(prompt) ... def post(self, shared, prep_res, exec_res_list): shared["all_parsed_resumes"] = exec_res_listAfter - AsyncParallelBatchNode
# After class BatchResumeParserNode(AsyncParallelBatchNode): async def prep_async(self, shared): return shared.get("resumes", []) async def exec_async(self, one_resume_text): ... response = await call_llm_async(prompt) ... async def post_async(self, shared, prep_res, exec_res_list): shared["all_parsed_resumes"] = exec_res_listBatchNode - Sequential
class BatchNode(Node): def _exec(self, items): # A simple, sequential for loop return [super(BatchNode, self)._exec(i) for i in (items or [])]AsyncParallelBatchNode - Parallel
class AsyncParallelBatchNode(AsyncNode, BatchNode): async def _exec(self, items): # Creates tasks and runs them all concurrently return await asyncio.gather(*(super(AsyncParallelBatchNode, self)._exec(i) for i in items))A loop becomes a gather. That's it.
Sequential Time
10 resumes × 10 seconds
Parallel Time
Time of Longest Task
1. Watch for API Rate Limits
2. Ensure Tasks are Independent
C+
Generic rambling output
Break big tasks into small tasks
%%{init: {'theme': 'dark'}}%% graph LR A[Outliner] --> B[BatchDrafter] --> C[Combiner]
List → Parallel Processing → Combine
%%{init: {'theme': 'dark'}}%% graph LR A[Outliner] --> B[BatchDrafter] --> C[Combiner]
%%{init: {'theme': 'dark'}}%% graph LR A["[Outliner]"] --> B[BatchDrafter] --> C[Combiner] style A fill:#4CAF50,stroke:#333
%%{init: {'theme': 'dark'}}%% graph LR A[Outliner] --> B["[BatchDrafter]"] --> C[Combiner] style B fill:#4CAF50,stroke:#333
%%{init: {'theme': 'dark'}}%% graph LR A[Outliner] --> B[BatchDrafter] --> C["[Combiner]"] style C fill:#4CAF50,stroke:#333
By breaking one complex request into 3 simple requests...
%%{init: {'theme': 'dark'}}%% graph LR A[Outline] --> B[Draft] --> C[Combine]
What if it could REWRITE its plan?
What if it could ADAPT on the fly?
What if it could actually THINK?
Magic? Consciousness? A Black Box?
%%{init: {'theme': 'dark'}}%% graph TD A[Decide Node] -->|action: 'search'| B[Search Node] A -->|action: 'answer'| C[Answer Node] B --> A
The Brain: DecideAction Node
class DecideAction(Node): def prep(self, shared): context = shared.get("context", "No previous search") question = shared["question"] return question, context def exec(self, inputs): question, context = inputs prompt = f"""Given the context, should you 'search' for more info or 'answer' now? Context: {context} Query: {question} Actions: - search - answer Respond in YAML: ```yaml action: <your_choice> search_query: <if searching> ```""" response = call_llm(prompt) yaml_str = response.split("```yaml")[1].split("```")[0].strip() decision = yaml.safe_load(yaml_str) return decision def post(self, shared, prep_res, exec_res): if exec_res["action"] == "search": shared["search_query"] = exec_res["search_query"] return exec_res["action"]The Tool: SearchWeb Node
class SearchWeb(Node): def prep(self, shared): return shared["search_query"] def exec(self, search_query): # Search the web for information search_client = GoogleSearchAPI(api_key="YOUR_API_KEY") results = search_client.search({ "query": search_query, "num_results": 3, "language": "en" }) formatted_results = f"Results for: {search_query}\n" for result in results: formatted_results += f"- {result.title}: {result.snippet}\n" return formatted_results def post(self, shared, prep_res, exec_res): previous = shared.get("context", "") shared["context"] = previous + "\n\nSEARCH: " + \ prep_res + "\nRESULTS: " + exec_res return "decide" # Loop back to the brainThe Exit: DirectAnswer Node
class DirectAnswer(Node): def prep(self, shared): question = shared["question"] context = shared.get("context", "") return question, context def exec(self, inputs): question, context = inputs prompt = f"""Based on the following information, answer the question. Question: {question} Research: {context} Provide a comprehensive answer using the research results.""" return call_llm(prompt) def post(self, shared, prep_res, exec_res): shared["answer"] = exec_res return "done" # End the flowWiring the Graph
# Connect the nodes together decide_node - "search" >> search_node decide_node - "answer" >> answer_node search_node - "decide" >> decide_node # The loop flow = Flow(start=decide_node)%%{init: {'theme': 'dark'}}%% graph TD A[DecideAction] -->|search| B[SearchWeb] A -->|answer| C[Answer] B --> A
%%{init: {'theme': 'dark'}}%% graph TD A["[DecideAction]"] -->|search| B[SearchWeb] A -->|answer| C[Answer] B --> A style A fill:#4CAF50,stroke:#333 linkStyle 0 stroke:#FFD700,stroke-width:4px
%%{init: {'theme': 'dark'}}%% graph TD A[DecideAction] -->|search| B["[SearchWeb]"] A -->|answer| C[Answer] B --> A style B fill:#4CAF50,stroke:#333
%%{init: {'theme': 'dark'}}%% graph TD A["[DecideAction]"] -->|search| B[SearchWeb] A -->|answer| C[Answer] B --> A style A fill:#4CAF50,stroke:#333 linkStyle 1 stroke:#FFD700,stroke-width:4px
%%{init: {'theme': 'dark'}}%% graph TD A[DecideAction] -->|search| B[SearchWeb] A -->|answer| C["[Answer]"] B --> A style C fill:#4CAF50,stroke:#333
✓ Chatbots
✓ Batch Processing
✓ Parallel Workflows
✓ Agents
...all from 100 lines.
The Node • The Shared Store • The Flow
Of course you do.
https://github.com/The-Pocket/PocketFlow
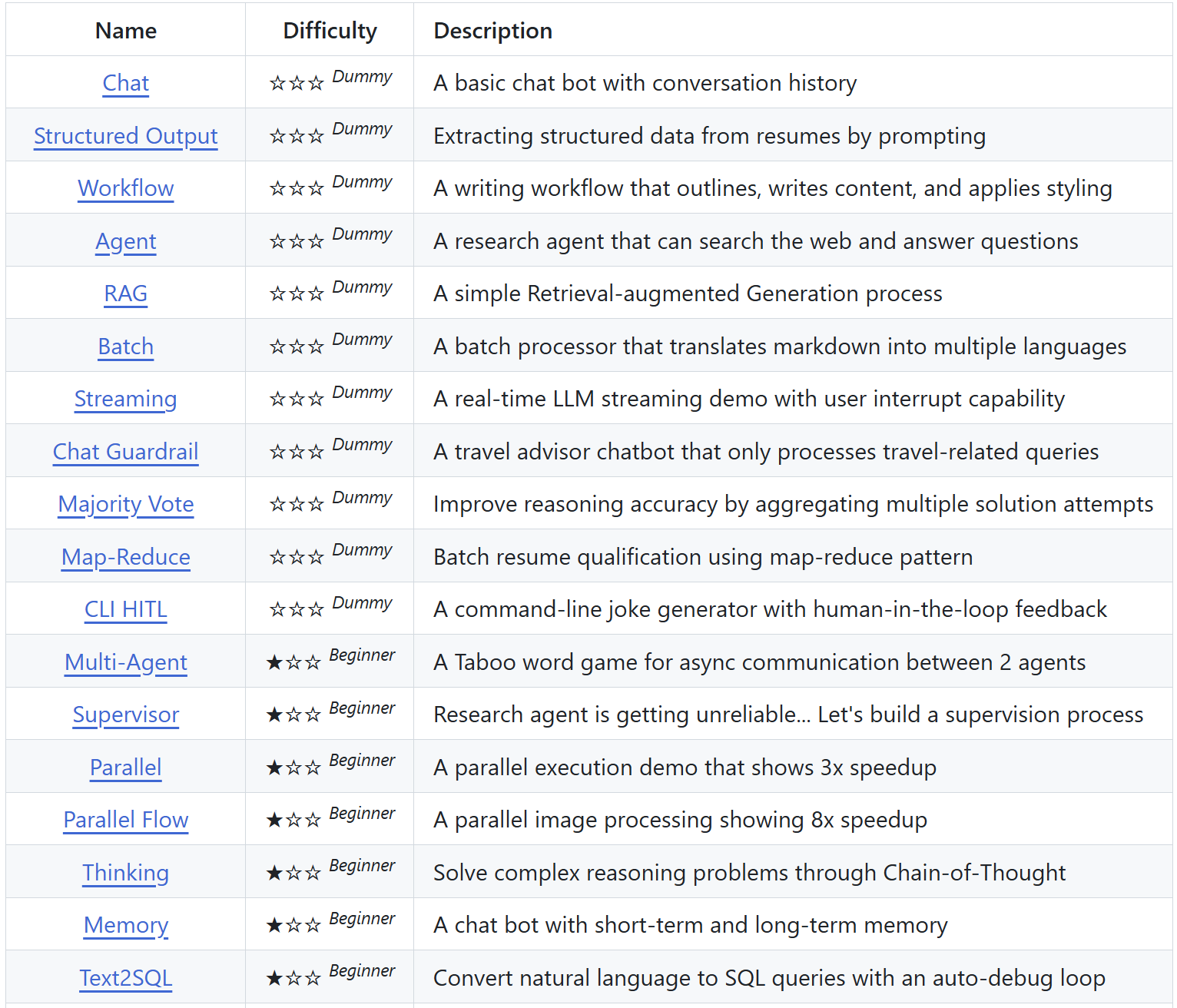
All built on the same 100-line foundation.
Let me show you something.
Just a more complex workflow. A bigger graph.

https://github.com/The-Pocket/PocketFlow-Tutorial-Codebase-Knowledge
%%{init: {'theme': 'dark'}}%% flowchart TD A[FetchRepo] --> B[IdentifyAbstractions] B --> C[AnalyzeRelationships] C --> D[OrderChapters] D --> E[Batch WriteChapters] E --> F[CombineTutorial]