.png)


“You become responsible, forever, for what you have tamed.”
– Antoine de Saint-Exupéry, in The Little Prince
Each company draws its own line between Product Engineering and Platform/Infrastructure/DevOps but the difference between them is clear: Product Engineering is “stuff the whole company wants” (making features) and the other is “stuff the engineers say we have to do, I guess”.

I’ve worked both above and below this divide and several times now I’ve led the entire span of engineering, from feature development down to whatever you call the bottom layer.
I think I know why that bottom layer has so many1 names: It’s actually two separate things. Both are invisible outside Engineering but they require radically different architectures, leadership, and investment models.
The Product function peers down into the technical stack like a person in a boat, trying to see the depths. There’s a limit to our perception from the surface. To see further we must plunge into the water ourself.
Everything visible when looking at the UX — the surface of the tech stack — is considered “Product Engineering”. Below that the work is opaque and is assumed to be a cost center for the company.
This view gives us two levels: The visible, and the invisible. And the line between them depends on the technical sophistication of the viewer.
This separation serves us poorly.
Partly because it prioritizes the merely visible over the important. To return to our aviation metaphor, prioritizing just visible product work is like making a plane out of just the visible parts: A fuselage, a flight stick, wheels, etc. We actually need a whole plane — with all the little details — if we want to fly.
The separation between visible and invisible work also obscures how the lower levels are more foundational in the system than the surface. If a feature breaks then just that feature is broken. If something deeper breaks then all features break.
I believe there are exactly three levels to Engineering in a product-shipping company, not two. These three levels exist no matter the size of the company and they do not necessarily map to the org chart.
They have many names but I call them Product Engineering, Domain2 Engineering, and Infrastructure Engineering.

They all work toward different purposes, with very different constraints, and along completely different timelines.
Let me show you.
There’s a Big Bang moment at the start of every tech company. The first line of code is instant and the next lines are the beginning of a permanent deceleration in velocity.
The team focuses entirely on making features and the system gets more complex until, hopefully, it’s actually useful. As new software engineers join the team they add further complexity and new patterns. Their excitement about features is tempered by a growing frustration with the underlying complexity. Folks tidy as they go but their goal is value creation, not cost reduction. The company hasn’t yet earned the right to clean up its mess.
Then one day, usually when there’s between 5 and 15 engineers at the company, one of them gets frustrated enough that they stop creating new features. They break away from the team and focus their attention on, say, the deployment script or the database config or the test suite.
Voilà. An infrastructure org is born.

This buys the company some time. With one person tending to complexity the rest of the team is free to keep piling new value into it. The infrastructure person fixes whatever problems exist, regardless of the type of problem. They can refactor source code, fix databases, debug BI dashboards, or improve deployments.
With their breadth of skills they’re prioritizing across the whole company’s needs, not limiting their work to just one layer in the technology stack or one app or technology. They can do this because they’ve helped create everything so far.
Other engineers may follow this person from feature development to infrastructure. The correct ratio between product work and infrastructure work depends entirely on the seniority of the product engineers and how much of the system they can reason about as they build new features. Anything the product engineers can’t perceive or don’t make time for the infrastructure team handles for them – so if your product engineers are junior you’ll need more infrastructure people3.
One day someone will be hired directly onto this infrastructure team. At this moment the engineering org undergoes a fundamental change and creates a problem it may not notice for years: There is now a person who’s fixing a foundation without understanding what that foundation supports.
An external hire doesn’t know the messiness of the product implementation. The features are, by definition, unique to the company so they can only learn them here. An external hire on an infrastructure team likely cannot upgrade, migrate, and reason about the system as a whole. They have other – very impressive – skills, but they can’t improve product internals. To do that they’d first have to build product features, which takes them away from growing their low level skills that command higher salaries under titles like ‘DevSecOps Engineer’ or ‘Cloud Architect’ or ‘SRE’. Going into product engineering would slow their career.
The product engineers may be justifiably impressed with these folks and the reverse is (hopefully) also true; neither group can do the other’s job. One knows the specific product in detail, the other knows the patterns for software generally.
It’s bad enough that the company may have just recreated the exact problem that DevOps intended to solve (one team writes software while the other one runs it), but there are well known solutions to that. The trap here is that, increasingly over time, some engineers are building features at the top edge of the system while others work at the extreme bottom of it.
Nobody is looking at the middle.
The middle of the system is messy.
Ask any engineer working at a large org what’s the hardest part of making features and they’ll likely say the dead center of the product suite is a giant mess.
Because ‘middle of the system’ is super vague let me be more clear. When the very first feature is created, all the technology at the company is in two categories:
- The unique logic, designs, and choices that comprise that first feature
- All the frameworks and tools to support changing and running that feature

The top category is the implementation of the company’s value proposition. Nothing up on top is particularly transferable between jobs because it’s the company’s competitive business advantage — it’s by definition totally unique.
The lower category is the opposite – if you work here at one company you can get up to speed on it quickly at another. Every company must run unit tests and deploy software so these patterns don’t change much, they’re less a matter of invention and more of learning enormous vocabularies of implementations. You can get paid well for knowing that a process with an exit code of zero has succeeded and applying that knowledge across industry-standard tools.
If there’s anything in this lower category that’s a unique pattern — anything at all — it either should be deleted or it belongs up with the features.
Once we add our second and third features the middle of the system reveals itself.

This middle layer is the glue that binds everything together. We can define it as “Everything that’s unique to this company’s features but not unique to any one feature.” It’s the internal semantics of the product suite as a whole, even if that product suite isn’t a suite yet. Even if it’s not a whole product yet.
Try to hire an infrastructure person from another company to fix your deployment and they’ll have it done quickly.
Try to hire a software engineer to build new features and they’ll do fine, as long as they passed the minimum technical bar and the feature is well specified.
Try to hire someone to work in this middle layer? They’ll immediately stumble over the internals of your company’s unique inventions.
How the middle atrophies
There’s a good reason this middle is so often unowned or poorly owned.
Two reasons, actually. I call them Infrastructure Gravity and Feature Lift.
They’re hidden but powerful forces pulling our engineers to the extreme top and bottom of the technology stack, forcing individual engineers to perform heroics in order to keep the middle alive.
Infrastructure Gravity
This bottom layer has a gravity to it, pulling engineers lower into the tech stack and keeping them there.
There’s a clear line in the tech stack above which most new infrastructure hires never venture. This line can be hard to see if you’re looking at source code but once the code is running it’s very clear: It’s the process boundary for the running app. Anything that supports running processes on a computer is below the line. Your cloud architecture, config scripts, the test harness, etc. Every system call that a process makes is dealt with below this line.
Above the line is the internal state of the processes themselves (and, by extension, their source code). Not just the business logic of each application but also the software frameworks and libraries, the features’ performance, and the semantic interconnections between all features and dependencies.
It’s easy to see why this line gets brighter over time. Inside a running process is code written by, possibly, a new employee in a big hurry a long time ago. Imagine you have a choice to, on the one hand, understand and improve this code or, on the other hand, find a way to execute the process 5% more efficiently using transferable Unix and cloud skills. Which would you choose? Only the latter is guaranteed to even work and it’s the one that provides the best career advancement in a role with the better pay.
This is Infrastructure Gravity.

It pulls the people working on Infra / Devops / SRE / etc. down out of the middle layer towards the stuff below this line where they have a much higher chance of success and protection from the debt of the product work.
Luckily, a company needs this gravitational force to keep the most foundational parts of their system stable. Without it there’s very little chance the system will be resilient or correct or secure. Infrastructure Gravity provides incredible value, it just also prevents people working at the bottom of the stack from helping out in the middle.
Because it prevents people who work below this line from learning what’s above it, we find that when they feel inspired to invent something it will probably be an appliance that exists below this line. Perhaps a new deployment tool or an orchestrator or a scheduler. Perhaps a new message bus or an API that provides a novel datastorage pattern. These seem like big improvements if you spend all your time below the line (or currently work at Google in the year 2007) but the value they provide is minuscule compared to any improvement in this middle layer. What good is a new message bus if the user account data is broken?
Once you recognize Infrastructure Gravity in your org it becomes clear that staffing investment in Infrastructure Engineering is more or less a fixed amount. The minimum reasonable investment is also the maximum. Staffing this below the minimum might be catastrophic and adding more engineers here will not provide any increase in product value.
Feature Lift
At the same time there’s an opposite force pressuring product-shipping engineers to stay at the top of the tech stack. Feature Lift pulls an engineer toward only the work necessary to launch a visible change.

Some feature work can be accomplished either quickly or slowly, the quick way producing a hidden mess. An engineer working through a backlog of tickets will sometimes take the slower path in order to fix the system a little. But an engineer who consistently takes this slow path will be at odds with their team’s mandate to ship features. Especially with teammates who don’t agree about the necessity of going slow (or who can’t perceive the mess). This leaves even the most well-intentioned and systems-minded engineer in a tension: Their ability to effect systemic improvements for the company requires them to spend social capital or to move to the lower, infrastructure layer.
This Feature Lift grows every time shipping fast is rewarded. Every time a product engineering team rewards itself for adding new value to users. Every launch, every performance review where someone has to write up their “impact”, and every time a new shiny thing is shown to colleagues – the Feature Lift increases its pressure.
Feature Lift, like Infrastructure Gravity, is powerful and good. It focuses a team tightly on what matters most right now. Without Feature Lift a company wouldn’t launch anything. There’s an old phrase among SREs at Google about “running to stay in place” – refactoring and fixing the internals of a system in a cycle, forever, with no visible output. In fact, this is the most common reason I’ve seen infrastructure tools companies fail: They’re founded and led by people who hesitate to send debt-ridden, valuable features out the door (I’ve been guilty of this as a founder).
So this Feature Lift provides enormous value — it often provides a company’s only value! But that value needs to be integrated with itself over time, the features consolidated with each other and the overall system smoothed out to make room for new features. No one feature is responsible for the company’s competitive advantages. It’s the system that holistically connects all features together, that integrates the features correctly, securely, and usably — that’s what makes a modern product worth using and sometimes even worth paying for.
Creating features one after another without consolidating them is like making a linked list. Useful, to be sure, but the cost of traversing it is `O(n)`. If we were to structure these features in a better architecture then it’s like storing elements in a binary tree. Which, under ideal conditions, can yield a far more efficient `O(log(n))` performance.
But a binary tree must be periodically rebalanced. If we just add items to it and never rebalance the tree it has the exact same poor performance as a linked list.

Once we recognize Feature Lift in our org it’s clear that staffing investments here is roughly linear – each additional engineer can provide a marginal increase in feature development. Additional headcount here is like adding items to an unbalanced binary tree.
So we go to the middle to get real acceleration. The middle of the system is where we add more engineers and see a superlinear return on our investment.
The Gap – A space for Domain Engineering
As a CTO you own one large sociotechnical system of people and technology and you can reason about it as a whole. Systems theory gives us that a system has properties that none of its component parts have, so if we fail to zoom all the way out we will miss some quality of this big thing we’re responsible for.
At this widest view, there are two ways the company is able to look at the technical system. These two perspectives map to Feature Lift and Infrastructure Gravity.

Most of the company perceives the system from the user experience. This view shows us all of the features pretty clearly. They’re built for people to use (even the 3rd party APIs) so it’s not too hard to see the system from this angle. This lets the company, and particularly the Product and Design functions, direct our work to improve the user experiences.
The other view is one that comes from the people who feel Infrastructure Gravity. These folks have developed sympathy for the runtime experience of the hardware and software itself. The memory use of processes, the latency of the network and filesystem writes, the data plumbing and storage patterns — this is a view of the system from the bottom.
There’s no “Middle Layer Non-Gravity Non-Lift” pulling anyone to the middle. The only thing that naturally draws engineers to look at the middle of their system is pure blinding rage. Given enough exposure to the neglected center someone will eventually make time to fix the things that bother them, whether they can make much progress or not.
Those heroes burn out quickly and they tend to be precisely the people you need mentoring junior folks, fixing security and performance, and doing interviews of senior talent. So lets not rely on only them to fix the middle of the system. These heroes feel responsible for the mess in the middle often because they helped make it but you, the executive, are actually the one person responsible for the mess. And that’s good, because this is a point of enormous leverage.
As we look closer we can make better sense of what this middle layer actually is: This is Domain Engineering; your company’s competitive advantage and your greatest asset as a technical leader.
Domain Engineering is the process of reusing domain knowledge to minimize the cost of developing products.
We see this in automobile manufacturing as shared chassis between models of cars. Or in software consulting as frameworks that generate software, making the work more configuration than coding. And at any company that would employ you or me Domain Engineering is the encapsulation and consolidation of the domain concepts underpinning more than one feature.
Let’s make this concrete with an example.
Imagine your engineers are designing an authorization/authentication layer to let users access a suite of products. It might be tempting to say that, because every product depends on this, the whole user access system is Domain Engineering. Most of it is actually the lower Infrastructure layer because every company needs a way to store secure user credentials, perform authentication, handle password and token verification, revocation, etc. None of that supports the competitive advantage of the company.
It might be hard to imagine what would exist in the middle, below the products and above the credential management. It’s hard to imagine because it’s rare for a company to even build it.

In between these two layers is a big opportunity to make great investments. For example, what happens when a user is not allowed to see a resource, generally? Do they see an error page or get redirected somewhere? What messages are displayed and how is the user guided through a UX flow? How are resources partitioned between tiers of authentication sensitivity?
All of that should be solved in a library so an engineer can choose the right pattern when implementing a new feature. If any of those details require development time from a feature-shipping team then the product roadmap is being delayed unnecessarily.
Domain Engineering is the place to bake in all the company-specific decisions about authentication flows, service-to-service APIs, library integrations, error pages, and anything else that you don’t want to drag on Product Engineering as they make new features.
And that’s just the beginning. Domain Engineering is also the right conceptual home to shepherd better development of the company’s competitive product advantages. It’s easy to spot a competitive advantage — it’s usually one of the oldest concepts around, it appears in virtually all of the products one way or another, and the implementation at some point becomes a huge mess. To GitHub this would be repos and commits, to Stripe and Square this would be the processes that create businesses and payments and purchased items, to Airbnb this would be the data and APIs that manage listings and reviews, etc. Any competitive advantage at your company will be leveraged across many features and is therefore best owned by the layer of engineers underneath Product Engineering.
You might think this sounds like ‘Platform Engineering’ and it has a lot of overlap. I deliberately avoid that word because it’s too easy to conflate that with “infrastructure” work and this layer needs to be insulated from Infrastructure Gravity. Anything pulling engineers down into infrastructure or up to building features will compromise Domain Engineering’s success.
Or, to think about this another way, how incredible is it that the competitive advantage of a company, something that appears in almost every feature, wouldn’t have engineering teams dedicated to increasing the impact of its use across the company?
A Financial Model of Domain Engineering
As executives we’re on the hook for the budget and outcomes from our org. It’s not enough to have strong opinions on “right” ways to operate, we need to show results and we need accurate predictive models for those results. In the face of impending layoffs or fierce competition we need a financial model that lets us know what we can do to avoid failing our people.
My most useful staffing model is also my simplest4: The product velocity at any given moment is a function of the staffing on Product Engineering multiplied by the speed of development.
The development speed is thrust divided by drag, just like an airplane’s windspeed: Big engines are no match for having a fuselage in the shape of, say, a cube.
And that thrust/drag ratio that leads to the development speed is itself a simple function of Domain Engineering staffing multiplied by how long Domain Engineering has been allowed to make progress.

This is where we find our superlinear investments. We can stop asking “how much staffing is best?” and start with a far more interesting question: “What’s the timeframe in which we need to maximize overall product output?”
If we have something like a Shipped Potential5 chart we can model the velocity, which we expect will go up as development drag goes down.

And with a timeframe to target we can aim to optimize the total delivered value within that timeframe. This is the integral of the velocity during that window.
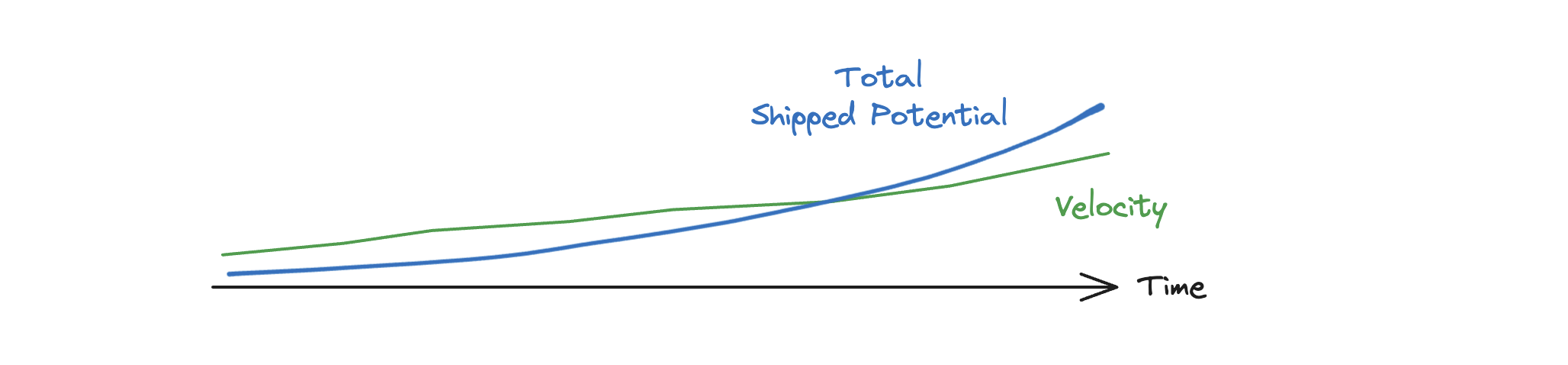
Knowing how long we have to maximize our velocity lets us staff Product Engineering and Domain Engineering appropriately. It’s not an exact science but it’s far, far better than just piling more engineers into Product Engineering and Infrastructure, watching the former get ever slower and watching the latter contribute nothing to revenue.
Receive future posts via email. Typically only a few per year.



