.png)

Will “AI” take our jobs? Will it enshittify our profession, transitioning us into managers for stupid robots? Does it dream of electric sheep? Today I’d like to introduce a new fear and, perhaps, throw you a rope with which to pull yourself out.
If LLMs turn out to be a fad and you’re reading this after they jump the shark, please accept this article as a historical artifact from a time when we entertained the idea that fancy autocomplete might eat the world.
Aside, for those who don’t know what Elixir is: it’s the best general purpose language in the world and if you haven’t heard of it wake up and smell the bacon.
The argument goes like so: Now that you have a bunch of folks who are “vibe coding”, they will just do whatever ChatGPT or Claude tell them to do. They will also be evaluating things almost solely against “how well did my ‘AI’ do with it” for making decisions going forward. For Elixir, this sounds like bad news bears. Here is a portion of a very long-winded response from ChatGPT when I asked it how I could “build a website like Amazon”.
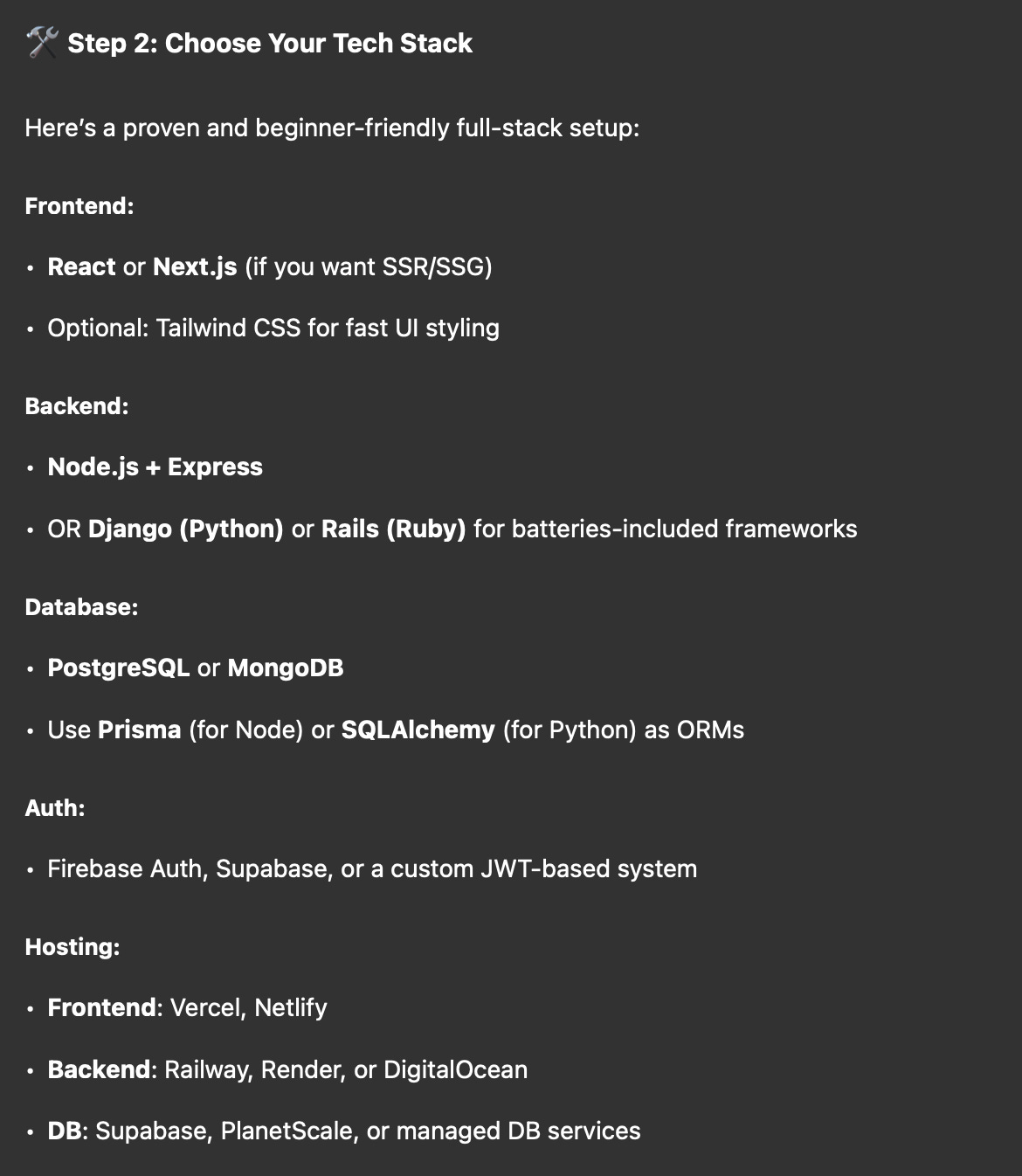
Oh no! I in my ultimate wisdom know that this is nowhere close to the best stack for the job. But the noobs won’t know that at all! Let’s say instead they’ve heard of Elixir on a blog post, or they saw this article topping the hacker news charts 🤞 (hi mom!).


I’m in this unique situation where time-to-market happens to matter. Also what do you mean “learning curve”, you’re supposed to do the learning for me. Thanks Chat, you really helped me dodge a bullet here, guess I’ll stick with Node & Next.js, thanks! 🥰
Mixing metaphors like a boss. While I’m sure the above scenario will play out countless times, at the end of the day this isn’t new. Theoretically this all goes one of two ways.
“AI” is able to overcome the fundamental issues with any tool, thus equalizing effectively all programming languages.
Vibe coders & new programmers working with LLMs hit the same walls that drove Elixir to exist in the first place.
In my opinion, both of these realities are “good news” in a way. In scenario 1, we’ve got magical mystery robots and they’ll just create the one programming language to rule them all and now we all have infinite automation in our pockets. Let’s talk about scenario 2, the one I find far more likely.
It’s no surprise that these things will mirror popular opinion. We can finagle our way there. This is a fresh prompt.

After giving me a bunch of sensible recommendations like using a CDN, horizontally scaling, using background jobs, migrating from Vercel to ECS, and scrolling past the recommendations to rewrite in Go and Rust, we finally found what we were looking for 🥹.

This brings us to a crucial realization: if LLMs can successfully guide someone toward Elixir when the use case demands it, then perhaps the real challenge isn't LLM bias toward mainstream tools - it's making sure LLMs can work effectively with our tools to enable developers to make that choice.

Alright, I’m up and running. Not sure how this would cost someone $10k on Vercel but I’m sure someone could find a way.
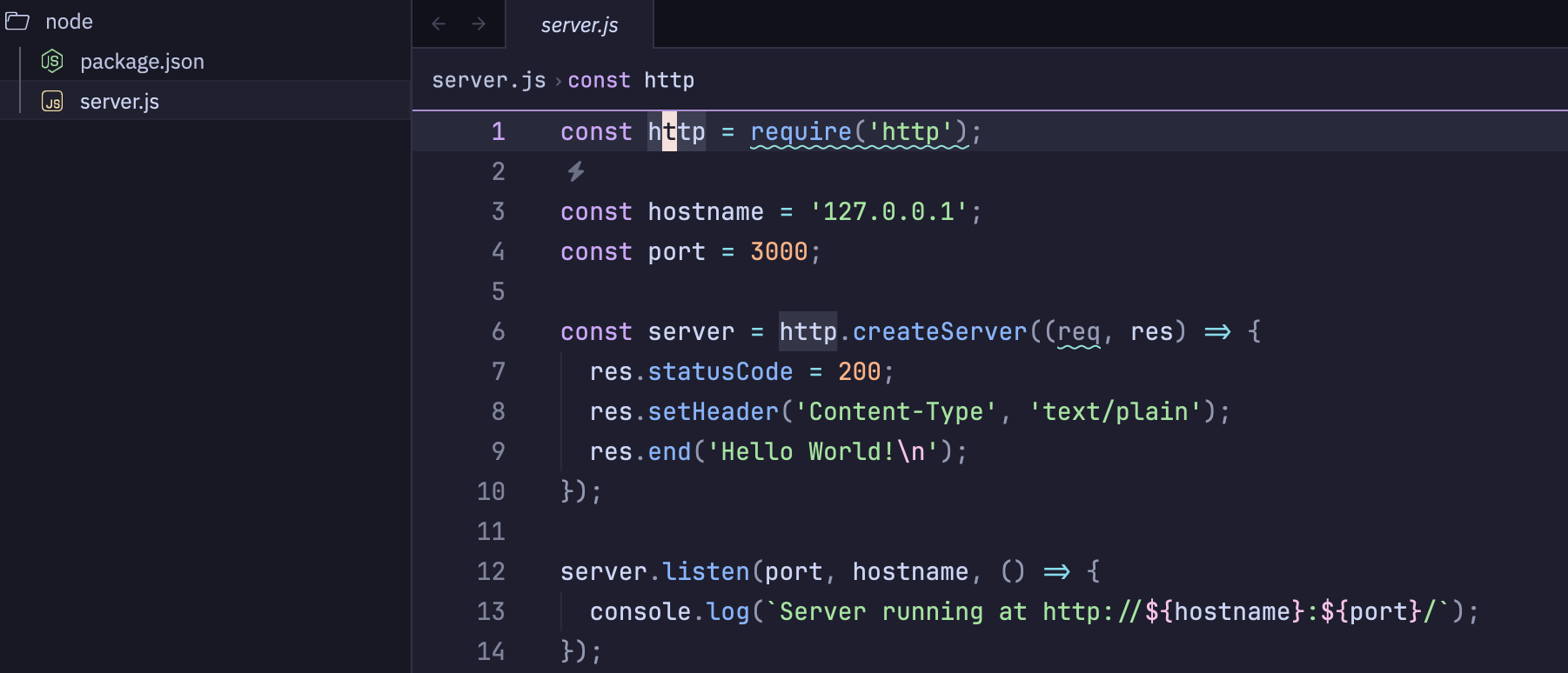
So let's test this theory. If I take Claude's advice and decide to explore Elixir, how well can it help me actually build something?

Not only does it work, but it does it effectively the same way that I personally would have done it if given the same task.
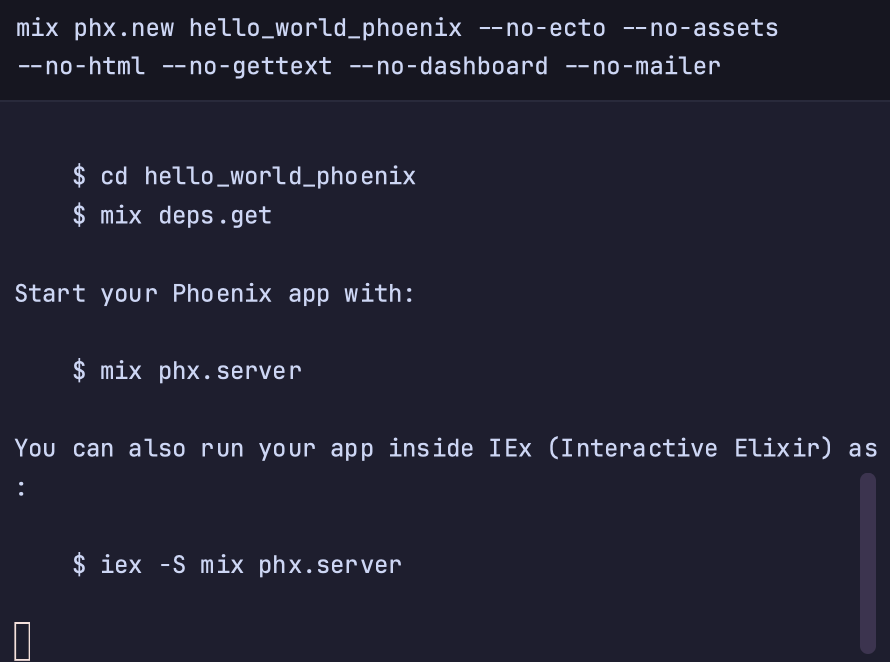
LLMs are quite good at translation. Where they often fall down with invention, this kind of thing is their bread and butter. It even kept it compatible with the node server I started with.
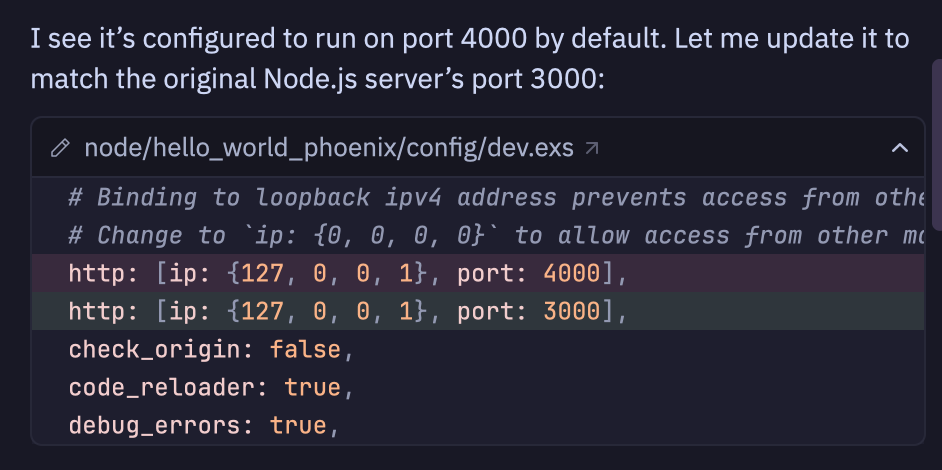
Plus some goodies:

Now, this doesn’t necessarily mean that non-mainstream technologies will be naturally surfaced over time, but, well…

If LLMs never get good enough to do things like troubleshoot esoteric technology and learn new things that weren’t in their training set, then they’ll fade into irrelevance anyway. So let’s extend this line of thinking out. If you think (like we probably all do) that your soup du jour is better than the other guy’s, then guess what? Either the LLMs will get “smart” enough to realize it too, or you’ll eat all the vibe coder’s lunch because they never figure it out.
Yes and no. I know there are a lot of people who will hate what I’m about to say. People I respect, and whose opinions I value despite how incorrect they are on this front. “AI” is going to significantly change what it looks like to build software. I’m not worried about how I’m going to stack up against the “Giving into the vibes, embrace exponentials, and forget that code even exists” folks, but I am aware that there are significant new tools & variables at play here. Not factoring them in is how you become a dinosaur. Which, for what it's worth, is fully your prerogative.
With that in mind, if we want our tools to succeed in this space, we need to invest in it as well. Not exclusively, maybe even not significantly. But being relevant here is non-optional IMHO.
I’m the author of an application framework for Elixir called Ash Framework. This article is not about Ash, but my work on it and the support that I provide for it have given me some potentially unique insights. Over the last few months I’ve observed:
a new item on the rubric for tools: the quality of answers from Claude & ChatGPT about it
a huge increase in fully off the wall and weird questions driven by LLM hallucinations
methodologies for working with LLM agents that are making me wish *more* of my users used them, not *less*
People are finding that the magic word smusher gives surprisingly good results for things like Typescript & Rust. All of a sudden, they have a new thing to factor in when making their decisions. FOMO is a powerful thing, so I think this plays a bigger factor than we’d like. Folks are worrying even more than ever about the future-proofing of their knowledge in the context of a major industry shift. If I invest my time to learn something that “AI” can’t help me with, will I be left behind? It’s a very real and important question, and I think to succeed these days, you have to alleviate the concern in some way.
Fairly often these days I get questions about code that no one would ever have had a reason to think should work. These cases are clearly coming from folks asking LLMs how to do something, or using an agentic assistant. The first knee-jerk response here is to tell people that we don’t answer questions about “AI” generated code. And in some cases, if it’s clear that the person asking the question did zero research on their own, they’ll get a response like that. But what if there was another way?
Ultimately you should not be relying on an LLM as a source of “knowledge”. This is true effectively always, even for popular tools, because LLMs won’t “know” about recent changes, but is magnified when asking questions about things that are more esoteric.
The key to succeeding with LLMs is to treat them as if they are only capable of doing things like summarization and pattern transformation. Assume that, before extracting an “answer” to your question, you must first do something that would *place* that answer into its context window, making its job the summarization and/or reformatting of the information into some desired result/effect. Here are some real things you can do to this effect.
Here is a concrete example of using LLMs “badly”.
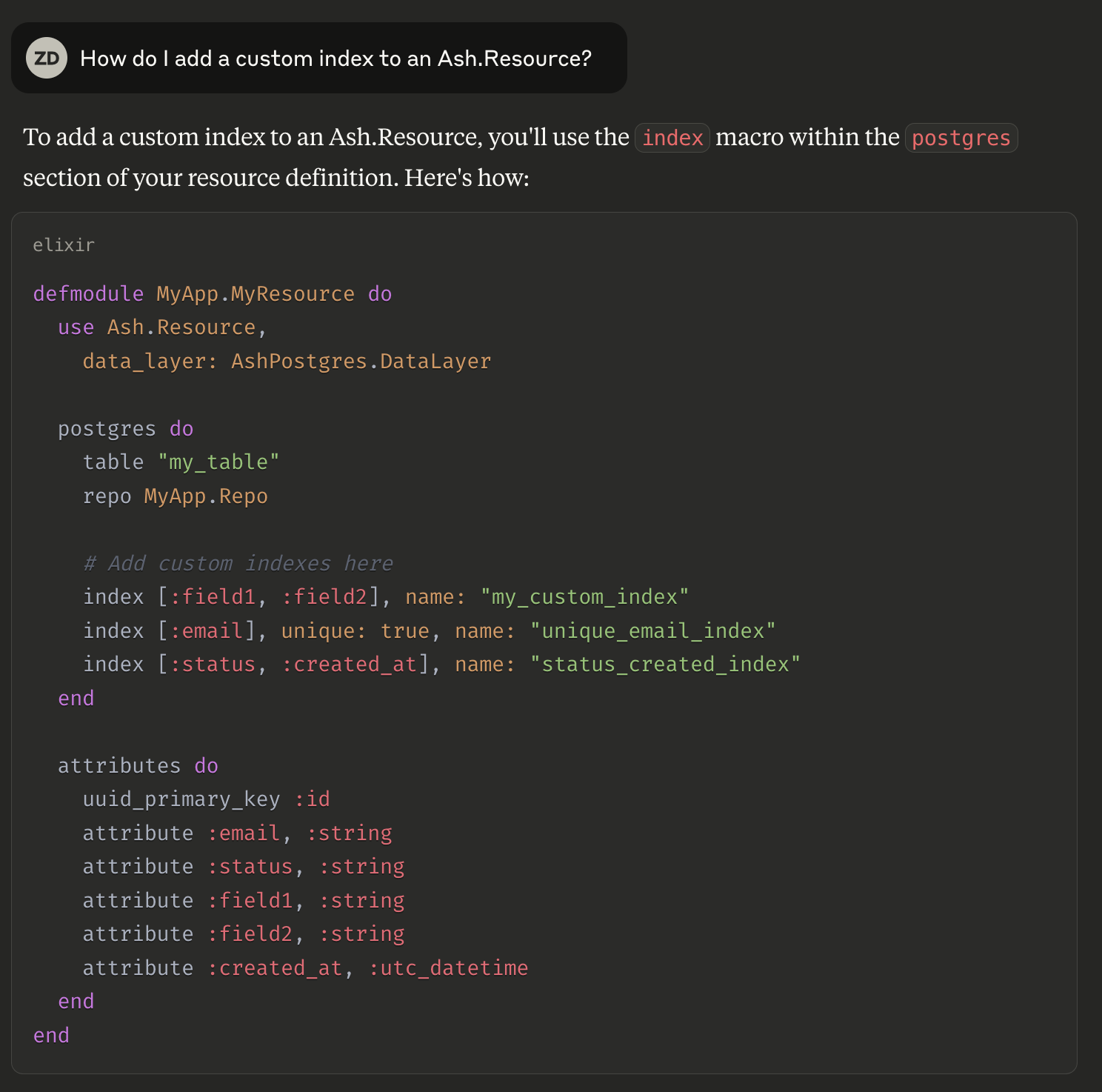
Looks plausible enough right? But as you can guess, it’s just flat out wrong. Let’s try again, but better this time. I’ll cheat a bit because I know where the docs that it needs are.
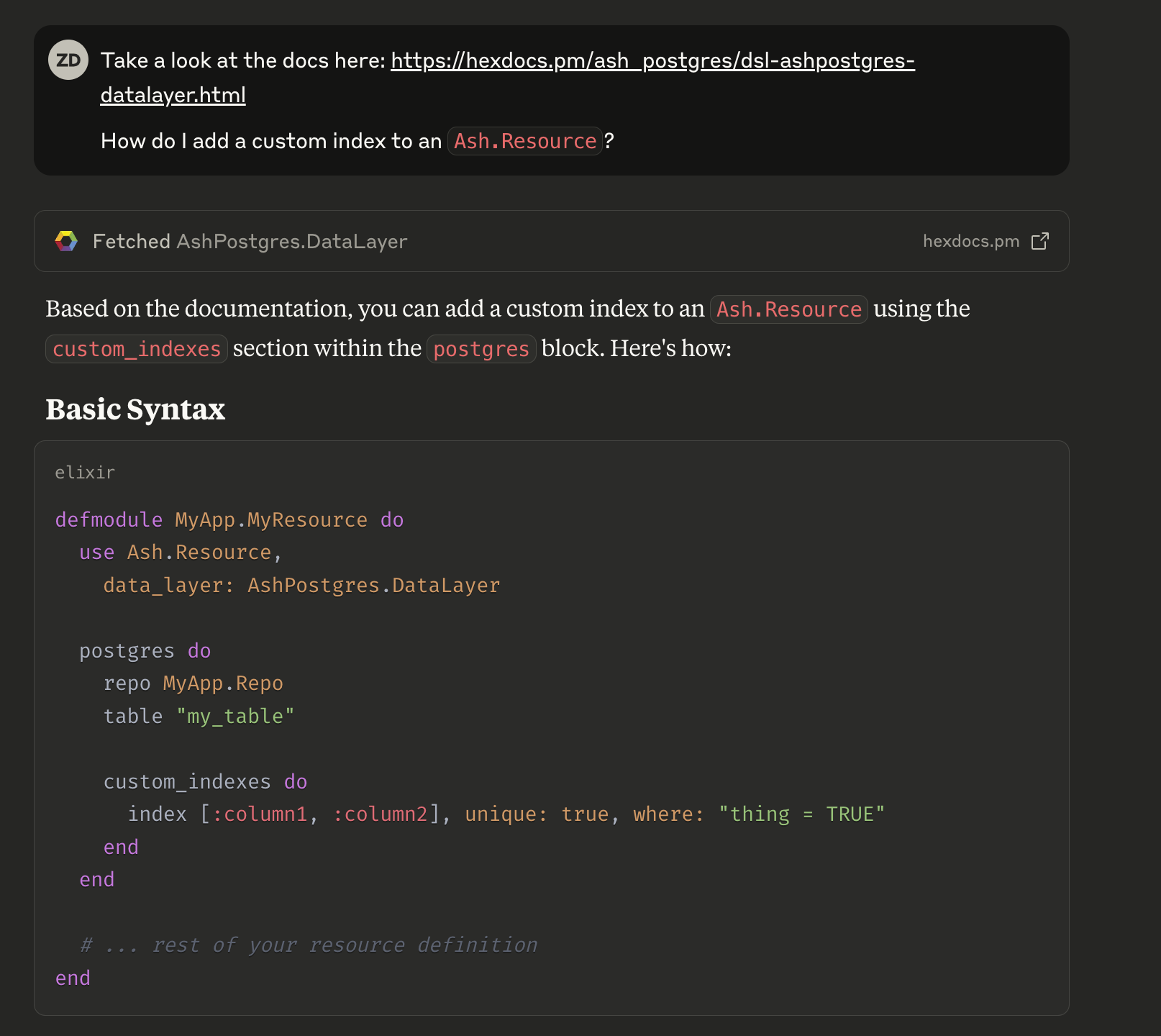
Not only is this correct, but it continues on to provide advice that would likely be easy to miss if skimming the docs. See the full answer here. All of a sudden, I’m not in the world of “please stop using LLMs to answer your questions”, I’m in the world of “please stop using LLMs badly to answer your questions”. I knew where to find this documentation, but what if I didn’t?
Have a look at another way of asking this question. First, I ask it to find the relevant docs. It does a great job. If you read the linked conversation, I then follow that up with the same question as before, and I get a correct answer without ever leaving Claude’s GUI.
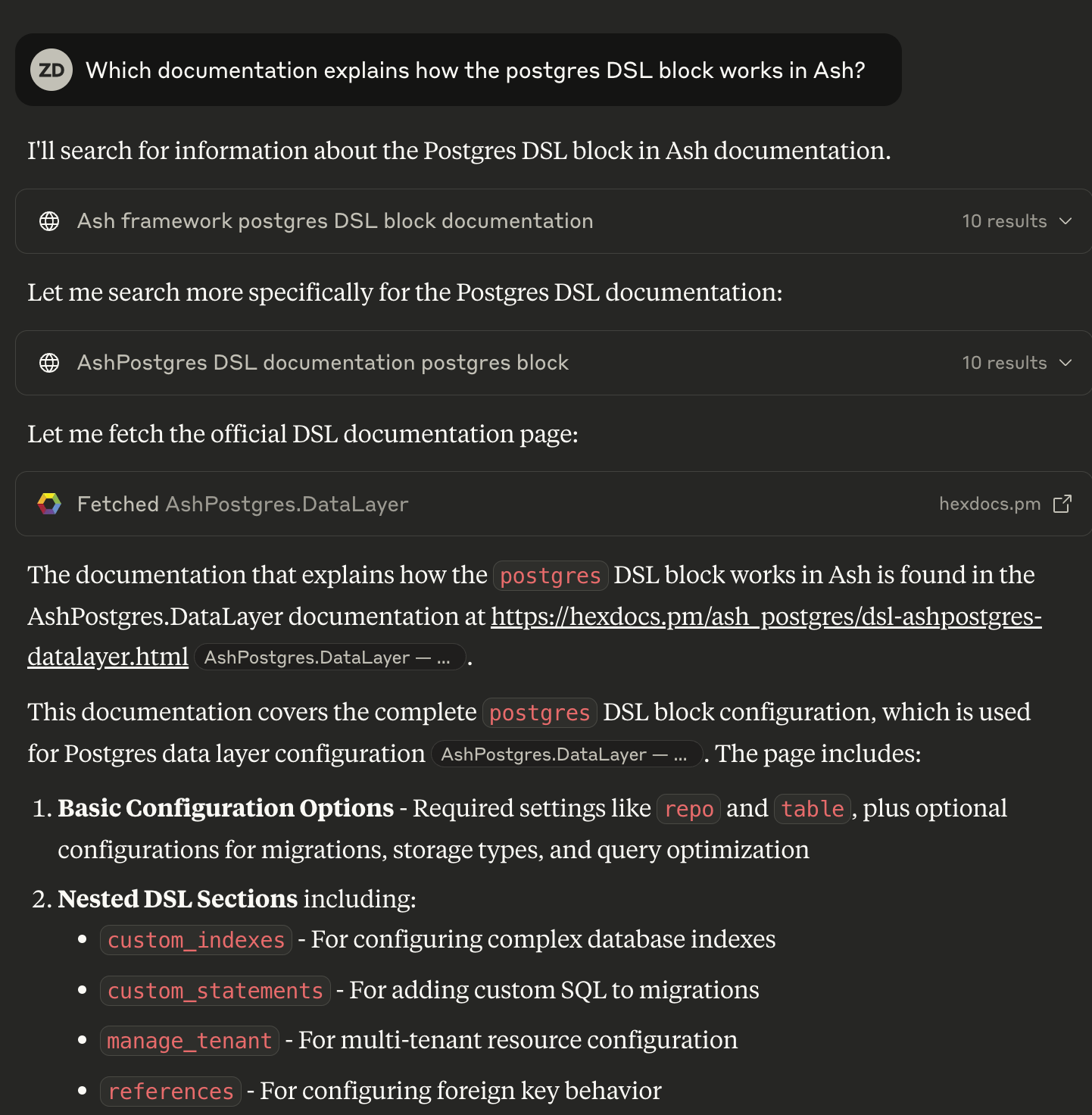
Tidewave is a server that speaks MCP (Model Context Protocol) that you can serve directly from your application. Think of it as giving your LLM a direct hotline to your running code - not just static documentation, but your actual living application.
Here's what this looks like in practice. Instead of asking Claude "How do I create a user in this app?" and getting a generic answer that might be outdated, Tidewave lets the LLM use tools like:
project_eval - runs code snippets directly in your application context
run_sql_query - executes database queries using your app's actual schema and tooling
search_hex_docs - searches the documentation of your specific package versions
This means your agent might do things like search the hex docs of your dependencies to see how Ash works, use the `project_eval` tool to poke around in your running app, try creating a user using your app to see if it works, and then run a SQL query after the fact to make sure the user exists in the database. Wildly powerful stuff.
This one is easy, and you can try it on your own apps today. Often when you end up building new features, they bear resemblance to one or more of the other things in your application. LLMs are very good at synthesis, summary, and categorization. So put them to work at it! A really excellent prompt to kick off an agent’s task often looks like this:
I'd like to make a feature to track user activity. Let's start with "last_login_at" and "last_seen_at". To start, we'll need a new plug in our router, kind of like @/path/to/similar/plug.ex, except instead of X it does Y. For the fields, take a look at `last_updated` for an example of the kind of field we want, except this one should be accepted as input when updating a user.I'm trying to push a new pattern for Elixir packages that I think could be game-changing. The concept is simple: any library can include a usage-rules.md file - essentially very terse documentation designed specifically for LLM context windows, explaining what to and what not to do when using the library.
We've done this for the main Ash packages, and the transformation is remarkable. We went from LLM agents being practically useless for Ash development to being able to generate idiomatic, production-ready code. The dichotomy of "meet my standards" versus "let the LLM do it" simply disappeared.
This isn't just about Ash or even Elixir. This is a template for how any technology community can turn LLMs from a threat into their most effective growth tool.
We can go even further. Instead of just helping LLMs use Elixir better, we can help train them to be better at Elixir in the first place. This is something we discussed at the contributors summit, so it is the product of many minds, not just mine.
The Elixir community could build evaluation datasets that test real-world scenarios: GenServer supervision trees, OTP fault tolerance patterns, Phoenix LiveView reactivity, writing Ecto queries, building applications with Ash. When companies like Anthropic and OpenAI train their models, they need diverse, high-quality benchmarks - and right now, they're mostly testing on Python and JavaScript.
If we get these evaluations to a degree of quality and scale, we get a bunch of benefits. We can determine which models are the best at writing Elixir. If done well enough, companies like OpenAI and Anthropic may even opt to use it to train their private models (something we should encourage in this scenario). You can find collections of benchmarks in various places, like: Hugging Face and GitHub. I see plenty of python stuff there, but not no Elixir 🤔.
Here's the kicker: Elixir's runtime makes it perfect for performance-based evals. We can build harnesses that don't just check if code compiles, but whether it actually handles concurrent load properly, recovers from crashes gracefully, or manages memory efficiently.
As models get better at Elixir through these evaluations, they become better advocates for it. We would be going beyond just making LLMs write better Elixir - we'd be making them recommend Elixir when it's the right choice.
If I can make LLMs a force to be reckoned with not only for Elixir but for the niche-within-a-niche that is Ash Framework, I think it's safe to say that LLMs are not, in-and-of-themselves, an existential threat to Elixir.
In fact, I think we're looking at this backwards. The real opportunity isn't surviving the LLM revolution - it's using it as a force multiplier. Better technologies have lost adoption battles because they had steeper learning curves or less accessible documentation, but maybe LLMs can flatten that learning curve if we do the work to make our tools competitive in this space.
The question isn't whether LLMs will change how we build software. They already have. The question is whether we'll shape that change or let it shape us.



