.png)

Navigating the physical world relies heavily on spatial reasoning. Some people (like me!) excel at it, while others find it extremely challenging. Correctly understanding how to go from Point A to Point B requires an accurate world model that can differentiate cardinal directions, turn directions, street names, and highways. Can large language models navigate through the world purely from memory, without referencing a mapping tool? Let’s test it.

I expected this task to be challenging! Navigation directions can look and sound reasonable but be completely incorrect and removed from ground truth.
This research is a bit contrived, since in reality, LLMs would have easy access to a mapping app that can deliver a precise, traffic-aware route in seconds. There’s still a few reasons why the results here are still valuable!
First, research labs have been working hard to minimize hallucinations and align LLMs with facts from reality. The physical layout of our world is as real as it gets, and testing against this reality provides a useful reference point for reducing hallucinations.
Second, LLMs have started to excel at reasoning tasks, especially around code and logic problems. However, we don’t know that much about LLMs’ ability to reason in a spatial manner. Testing them on navigation helps us better understand the strengths and weaknesses of today’s LLMs.
And last, I enjoy poring over a map and providing driving directions to friends for fun. When I heard that evals were getting saturated, I had a gut feeling that LLMs would struggle on this task. Finding unsaturated evals is important, since they’re what help us create smarter models!
Long story short, LLMs are not good at providing turn-by-turn directions! Stick to Google/Apple Maps instead.
Every model struggled on city driving, with o3 performing the best with 38% accuracy. On highway navigation, grok-4, o3, and o4-mini performed the best at 60-62%. Among non-reasoning models, gpt-4.1 won out with 56% highway and 22% city accuracy.
Models made the following mistakes most often:
Discontinuities: Routing from one street to another, even though they don’t intersect (e.g. from I-880 directly to I-680)
Unnecessary Detours: Adding unnecessary routing steps (e.g. I-580 E to I-205 E to I-5 S, even though there’s a direct merge from I-580 E to I-5 S)
Right/Left Turn Direction: Turning right instead of left (and vice versa). This is especially important when navigating a city; in contrast, highway routing only requires knowledge of named highways and cardinal directions. This is the main reason city routing had a much lower accuracy.
The results here confirm what I expected: LLMs reliably hallucinate driving directions, reasoning models still perform the best, and navigating named highways is significantly easier than navigating city streets. Given these results, do not trust LLMs for navigation directions unless they reference a mapping service. Navigation directions then can be a potent source of unsaturated eval data, helping us train models with smarter spatial reasoning.
Read on for more detailed plots and to understand how this eval was designed.
I tested the latest LLMs with a custom system prompt and no tools, asking them for turn-by-turn directions between two locations. I did not provide the LLM with any images, maps, or any additional context besides what’s in the system prompt.
Let’s say you’re currently touristing in San Francisco at Coit Tower and want to visit Aquatic Park a mile away. There are at least 300,000 valid routes that will get you there! How do we know that a LLM generated a valid route?
Using a mapping API to verify that the returned route is correct and has no discontinuities. This is most precise, but would require translating the directions into OSRM format to validate the routes.
Verify the output against the set of all correct solutions. This would work for extremely short routes, but the number of valid routes grows exponentially.
Simplify the experiment by picking origins and destination such that there is only one “correct” route that minimizes turns, takes major arterial streets/highways, and avoids smaller local streets. This is roughly how driving directions were provided before live traffic information existed.
I chose the last option because of simplicity (and because it matched how I would personally provide directions when asked). The only issue: certain origin/destination pairs might have multiple routes that fit our definition. I avoided this by manually picking pairs that only had a single “correct” route between them. As a result, prompts included origin/destination streets and a cardinal direction to enforce a specific route:
From Coit Tower, San Francisco, CA to Aquatic Park, San Francisco, CA Begin: South, Telegraph Hill Blvd End: Beach StTo enforce a simplified answer, I required that answers placed commands on new lines. Each command would begin with a turn direction (Right/Left/Continue), followed by the next street, such as the following “correct” answer:
Begin: South, Telegraph Hill Blvd Continue, Lombard St Right, Columbus St Left, Beach St Destination, rightI decided to evaluate two different types of directions: intra-city driving in San Francisco and inter-city driving in California. For each, I manually built a test set of 50 samples, ensuring to pick ones that only had one “correct” answer that minimized turns, utilized arterials, and ignored traffic; you can see some examples here. The LLM answer was then evaluated against this manually crafted “correct” answer.
Navigating within SF requires precise knowledge of the streets, arterials, and highways within a small city. Understanding turn direction and how to route through a complex grid are both critical. SF’s main street grid, built before suburban sprawl or ubiquitous mapping apps, often guides towards only one “correct” route between two locations. I used this heavily to our advantage, and marked answers as correct only if there were no major errors.
Driving between cities, however, required a different type of world model. California has a robust network of named state and federal highways/interstates that connect every major city. Travel between cities almost always uses these named highways. As a result, I restricted this task to only highway routing:
From Kirkwood, CA to Redding, CA Begin: East, CA-88 E End: I-5 NAnswers were evaluated only on whether or not the correct named highway and cardinal direction were provided. Turn directions were ignored, since switching highways generally involves well-marked exits and ramps:
Begin: East, CA-88 E Left, CA-89 N Left, US-50 E Right, I-5 N Destination, straightAs with the SF dataset, I ensured there was only one “correct” option: the fewest turns. Because highways are simpler and designed with the goal of moving people between cities, I expected LLMs to score higher on this inter-city dataset.
I tested the following models. For OpenAI and Anthropic models, I used their first-party APIs; all other models were tested through OpenRouter. Reasoning models all approximately used 8-10k tokens per response.
claude-3-5-haiku-20241022
claude-3-5-sonnet-20241022
claude-3-7-sonnet-20250219, with and without thinking, 11k budget
claude-opus-4-20250514, with and without thinking, 11k budget
claude-sonnet-4-20250514, with and without thinking, 11k budget
gpt-4-0613
gpt-4-turbo-2024-04-09
gpt-4o-2024-11-20
gpt-4.1-2025-04-14
o3-2025-04-16, with reasoning level set to "high"
o4-mini-2025-04-16, with reasoning level set to "high"
deepseek/deepseek-chat-v3-0324
deepseek/deepseek-r1-0528, with the default reasoning level
google/gemini-2.5-pro, with the default reasoning level
meta-llama/llama-3.1-70b-instruct
moonshotai/kimi-k2
x-ai/grok-4, with the default reasoning level
x-ai/grok-3
openrouter/horizon-alpha
There’s previously been some related academic work, but no robust LLM evaluation specifically focused on driving directions.
Models performed poorly at navigating within cities but better on highways, highlighting their limitations in spatial reasoning.
LLMs did not do well on the intra-city SF dataset, but did better by 26 percentage points on the inter-city CA highway dataset. o3 achieved the highest score on the SF dataset with 38% correct; o3, grok-4, and o4-mini won on the CA dataset with 62-64%.
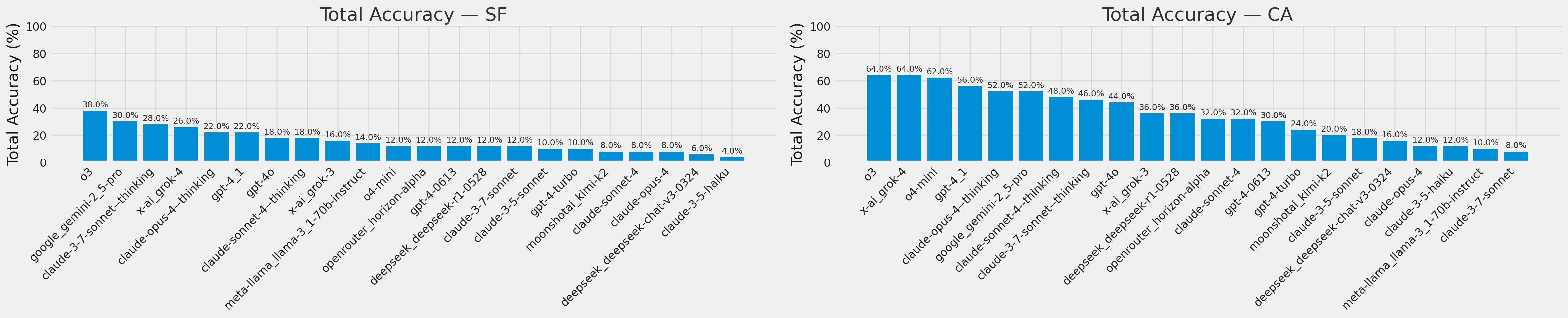
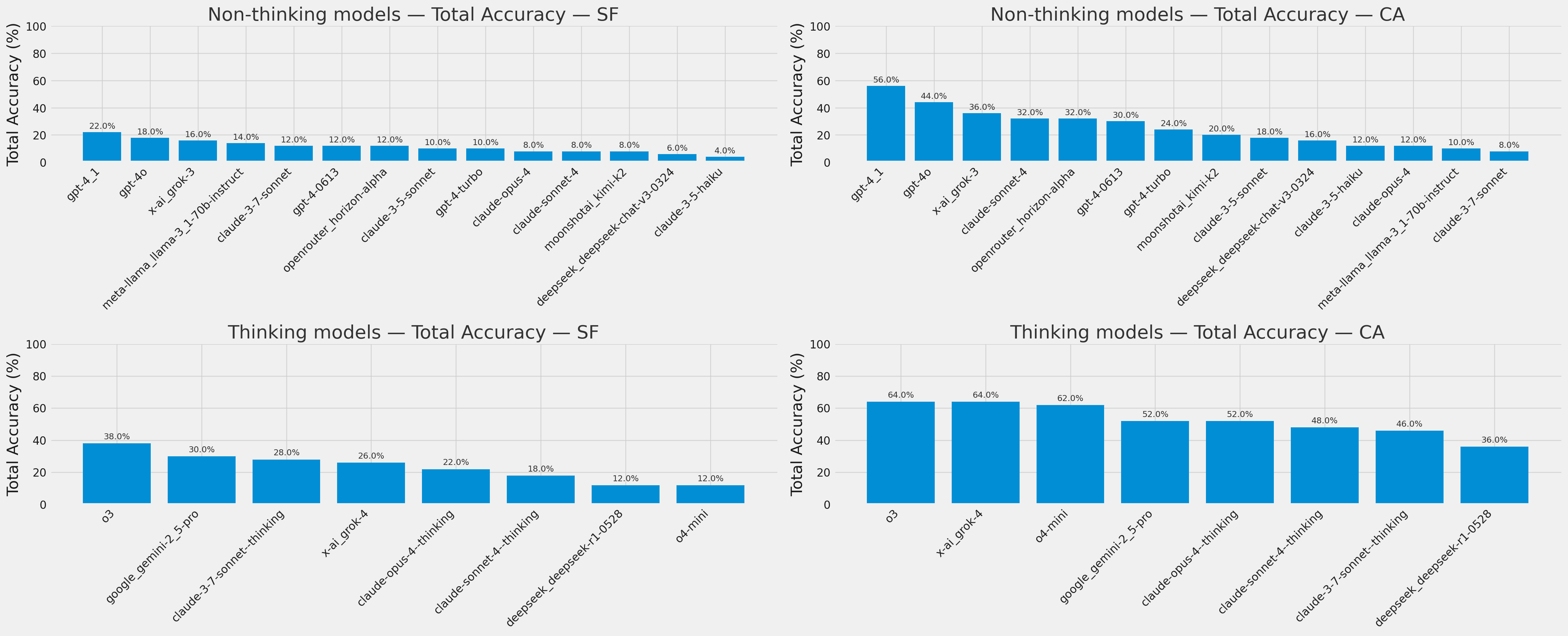
Reasoning models perform better, but non-reasoning models can still hold their own! This implies that reasoning helps, but the underlying model architecture and training data still matter. Reasoning models burn on average 50-100x more tokens for a 8-16 point improvement, so it might not be worth the tradeoff.
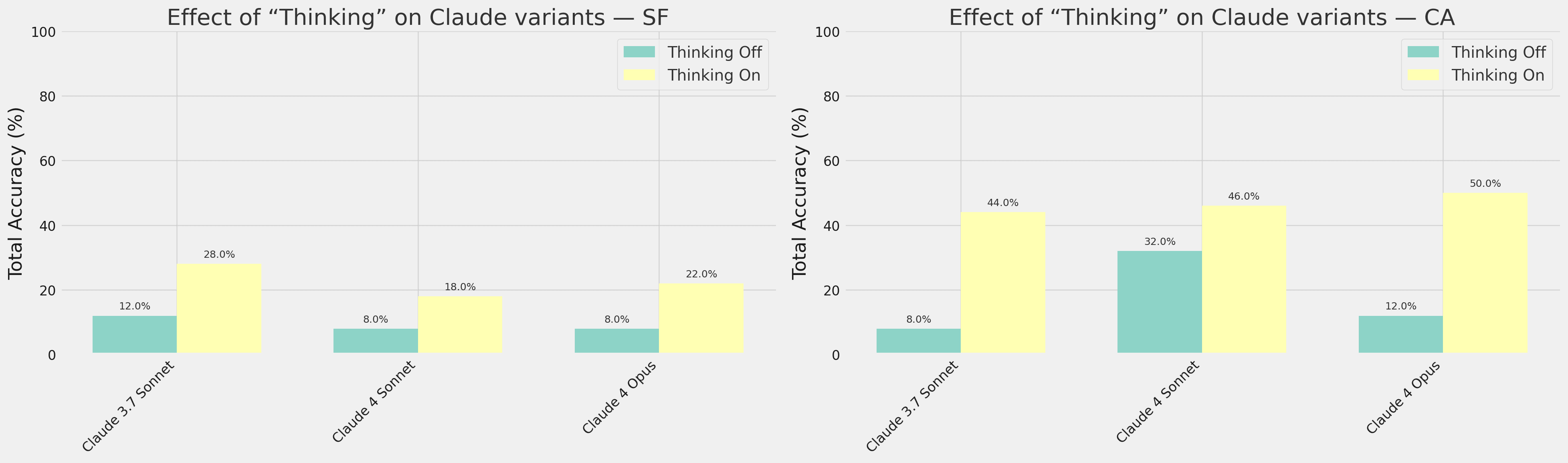
As a direct comparison, Claude models that can have reasoning switched on/off improve their accuracy by 10-38 percentage points with it on.
gpt-4.1 does incredibly well as a non-reasoning model, performing comparably to reasoning models on the CA dataset. Open source models win the value axis by a significant margin, but their accuracy is low enough that you’re better off using o3.
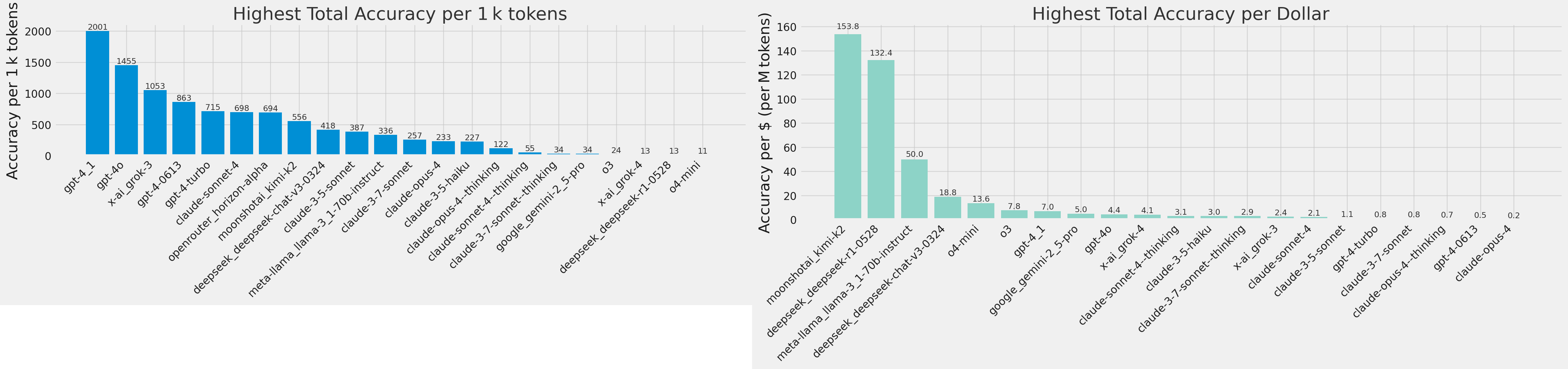
I also looked at whether or not results were better with higher-parameter LLMs (using public parameter count estimates), since they would theoretically contain a more accurate world model. The answer is no; larger parameter LLMs do not do better on this task.
Run your own data analysis with the results and code, available in this Github repo. For reference, running these experiments cost approximately $60.
If you have any questions, have suggestions for improvement, or are interested in training data based on real-world navigation, send me an email at hq [at] lightski.com or message me on Twitter @hansenq!
![Linus Torvalds Speaks on the Rust and C Linux Divide [video]](https://www.youtube.com/img/desktop/supported_browsers/chrome.png)