.png)

The Agent Amnesia Crisis
Here's a startling fact: the average LLM agent repeats the same mistake 3-4 times before humans intervene to stop it. Think about that for a moment. These are systems capable of writing code, browsing the web, and analyzing complex data—yet they can't remember what went wrong ten minutes ago.
This isn't a minor bug. It's a fundamental architectural flaw that researchers call "agent amnesia," and it's the primary reason why your ChatGPT struggles with multi-day projects or why Claude Code sometimes feels like it's meeting you for the first time in every conversation.
The problem is simple but profound: LLM agents treat every task as a blank slate. Each interaction is isolated, disconnected from past experiences. When an agent successfully navigates a tricky website layout or discovers an elegant solution to a coding challenge, that hard-won knowledge evaporates the moment the task ends. Worse, when it fails—hitting an API rate limit, misinterpreting a website's structure, or choosing the wrong debugging approach—it has no mechanism to avoid repeating that exact mistake tomorrow.
The consequences ripple across every dimension of agent deployment. Economically, this amnesia is devastating. Organizations using API-based agents waste 20-40% of their token budget re-discovering solutions to previously solved problems. Operationally, it makes agents unreliable for production environments—you can't deploy a system that might repeat a critical error it encountered yesterday. And strategically, it blocks the path to truly autonomous AI. An agent that can't learn from experience can never evolve beyond its initial training.
ReasoningBank: Memory as Strategic Wisdom
Enter ReasoningBank, a framework from Google Research that fundamentally rethinks what agent memory should be. The key insight? Agents don't need a perfect recording of every interaction. They need something far more valuable: distilled strategic wisdom.
Traditional approaches to agent memory fall into two camps, both flawed. Some systems store raw interaction logs—every click, every API call, every token generated. This creates massive, noisy databases where finding relevant past experiences is like searching for a needle in a haystack. Other systems curate libraries of successful workflows, essentially creating a recipe book of "things that worked." But this ignores half the learning opportunity: understanding what doesn't work.
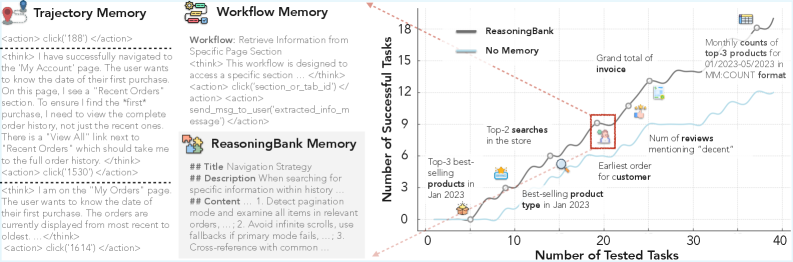
ReasoningBank takes a different path. It transforms each completed task—whether successful or failed—into a compact, human-readable memory item that captures the core strategic lesson. Here's what that looks like in practice:
Memory Item Structure:
Title: "Verify search functionality before relying on site search" Description: When product listings appear incomplete, check if the site's search is actually functional before assuming inventory issues. Content: - Context: E-commerce site showed only 3 results for "laptop" - Failed approach: Assumed limited inventory, reported back to user - Root cause: Site search was disabled, needed manual category navigation - Strategy: Always test search with known-good queries first - Applicability: Any web navigation task involving search interfacesThis is fundamentally different from storing raw data. The memory item abstracts away the specifics (which website, which product) and elevates the interaction to a principle that can transfer to new contexts. When the agent encounters another e-commerce site tomorrow, it doesn't need to have seen that exact site before—it retrieves this strategic insight and applies it.
The framework's structure follows a precise four-stage cycle:
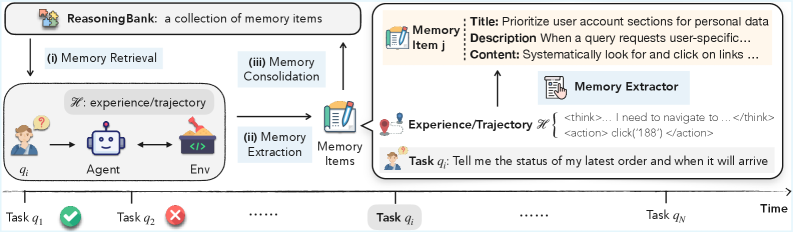
1. Retrieve: Before starting a new task, the agent queries ReasoningBank using semantic similarity. The top-k most relevant memory items are injected into its context, giving it strategic guidance tailored to the current challenge.
2. Execute: The agent attempts the task, informed by retrieved strategies. These memories act as heuristics, helping it navigate decision points more effectively.
3. Judge: Upon completion, the agent self-evaluates the trajectory. Did it succeed or fail? This judgment happens autonomously—no human labels required—using the LLM itself as a critic.
4. Distill: The trajectory is analyzed to extract its core reasoning pattern. What was the key decision that led to success? What assumption caused the failure? This insight becomes a new memory item, added to the bank for future retrieval.
This closed loop is what makes the system self-evolving. Every interaction enriches the memory bank. Every task makes the next one smarter. There's no retraining, no fine-tuning—the agent's capability grows organically through experience.
Learning from Failure: The Overlooked Superpower
Let's be precise about this: 40% of ReasoningBank's initial training patterns come from failed trajectories. This is not a bug. It's the feature that sets this framework apart from every other agent memory system.
Think of it this way: when you learn to ride a bike, you don't just remember the successful rides. You remember that leaning too far left made you fall, that pedaling too slowly caused wobbling, that looking down instead of ahead led to crashes. These "negative examples" are just as valuable—sometimes more valuable—than memories of smooth rides.
ReasoningBank formalizes this intuition. When an agent fails to complete a task, it doesn't discard that experience as noise. Instead, it distills an anti-pattern: a structured description of what went wrong and how to avoid it in the future.
Example Failure → Anti-Pattern:
Suppose an agent tries to scrape data from a website by hammering the same URL endpoint 50 times in rapid succession. The site's rate limiter kicks in, blocking the agent entirely. A traditional system might log this as "task failed" and move on. ReasoningBank does something smarter:
Title: "Respect rate limits: exponential backoff required" Description: Rapid repeated requests to the same endpoint will trigger rate limiting. Always implement exponential backoff. Content: - Context: Data collection task from API endpoint - Failed approach: 50 requests in 10 seconds - Error: 429 Too Many Requests after request #12 - Root cause: No delay between requests, no retry logic - Correct strategy: Start with 1s delay, double after each 429, max 32s - Red flag: Any loop making >10 requests/second to same hostThe next time this agent—or any agent in the same deployment—encounters an API, it retrieves this anti-pattern and implements backoff before hitting the rate limit. The mistake doesn't repeat.
This approach reflects deep insight from cognitive science. Human experts don't just accumulate success stories—they build mental models of failure modes. A chess grandmaster doesn't just remember winning moves; they've internalized thousands of losing patterns to avoid. An experienced surgeon knows every complication that can arise during a procedure, not just the textbook-perfect case.
By treating failures as first-class training data, ReasoningBank enables agents to develop this same kind of defensive expertise. It's the difference between an agent that sometimes works and an agent you can trust.
The Self-Evolution Loop Explained
The four-stage cycle we outlined earlier—Retrieve, Execute, Judge, Distill—creates something remarkable: continuous improvement without external intervention. Let's trace exactly how this works in a real scenario.
Scenario: Web Shopping Task
An agent is asked to find and purchase the cheapest wireless keyboard on an e-commerce site.
Attempt 1 (Cold Start):
- Retrieve: ReasoningBank is empty. No relevant memories found.
- Execute: Agent uses on-site search, types "wireless keyboard", gets 200 results, picks first one (not cheapest), adds to cart.
- Judge: Task fails validation. Wrong product selected (not cheapest).
- Distill: Extracts lesson: "Search results default to 'relevance', not 'price'. Always check sort options."
Attempt 2 (Same site, different product category):
- Retrieve: Finds memory: "Check sort options for price-based tasks."
- Execute: Searches for "gaming mouse", immediately looks for sort dropdown, selects "Price: Low to High", picks first result.
- Judge: Task succeeds.
- Distill: Reinforces existing memory, adds confidence score: 1.20× multiplier (Bayesian update).
Attempt 3 (Different e-commerce site, weeks later):
- Retrieve: Finds memory: "Check sort options..." (confidence: 95%).
- Execute: Applies strategy to new site. Sort dropdown is in different location but principle transfers. Task succeeds in first attempt.
- Judge: Validates strategy generalization.
- Distill: Confirms cross-site applicability, keeps confidence at 95% (capped).
Notice what's happening here. The agent isn't memorizing "click this exact button on this exact site." It's extracting a transferable heuristic that works across contexts. This is the essence of genuine learning.
The distillation process itself is computationally elegant. After completing a task, the agent uses the LLM in a meta-cognitive role to answer:
- What was the pivotal decision in this trajectory?
- Why did it lead to success/failure?
- What general principle can be extracted?
- Under what conditions does this principle apply?
The answers become the memory item. The entire process is self-supervised—the agent judges its own performance using task completion signals (did the product get added to cart? did the test pass? did the user query succeed?). No human annotation required.
This autonomy is critical for scalability. You can deploy an agent on Monday, let it run thousands of tasks, and by Friday it's genuinely more capable than when it started. The memory bank grows, strategies compound, and the system evolves.
MaTTS: Scaling Through Experience Depth
Traditional AI scaling has focused on breadth: bigger models, larger datasets, more compute for training. ReasoningBank introduces a complementary dimension: depth—allocating more compute to generating richer experiences during test time.
This is Memory-Aware Test-Time Scaling (MaTTS), and it works through two mechanisms:
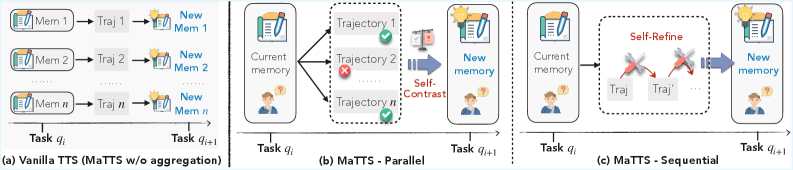
Parallel MaTTS: Learning from Contrast
Instead of generating a single solution trajectory for a task, the agent spawns k parallel attempts simultaneously. Each rollout explores different strategies, makes different decisions. Then comes the magic: self-contrast analysis.
The agent compares all k trajectories, asking:
- Which steps appear in successful rollouts but not failed ones?
- Which decisions are consistent across all successes?
- Which approaches were attempted but proven unreliable?
This contrastive signal is far richer than any single trajectory could provide. It's like running k experiments and distilling the meta-lesson. The resulting memory item is validated across multiple executions, making it more robust and generalizable.
Example:
Task: Debug a failing web scraper.
- Rollout 1: Adds timeout handling → Success
- Rollout 2: Adds timeout + user-agent header → Success
- Rollout 3: Only adds user-agent header → Fails
- Rollout 4: Adds retry logic → Success
- Rollout 5: No changes → Fails
Distilled Strategy: "Timeout handling is critical for scraper reliability. User-agent alone is insufficient. Retry logic provides additional robustness but timeout is the necessary component."
This is far more informative than learning from a single successful attempt.
Sequential MaTTS: Learning from Refinement
In this mode, the agent iteratively improves a single trajectory. After the first attempt, it reflects, identifies weaknesses, and tries again with adjustments. Each iteration generates a distinct memory item capturing the refinement:
- Iteration 1: "Use BeautifulSoup for HTML parsing"
- Iteration 2: "BeautifulSoup struggles with JS-rendered content; use Selenium"
- Iteration 3: "Selenium is slow; use Playwright for better performance"
Each layer of refinement adds nuance to the memory bank.
The Synergistic Loop
The true power emerges when MaTTS feeds into ReasoningBank and vice versa:
- Memory guides scaling: High-quality retrieved memories steer parallel rollouts toward promising strategies, making exploration more efficient.
- Scaling enriches memory: Diverse experiences from MaTTS provide contrastive signals that create higher-quality, more generalizable memory items.
This creates a compounding effect. Better memories → smarter scaling → richer experiences → even better memories.
On the WebArena e-commerce subset, this synergy delivered measurable gains:
- Parallel MaTTS (k=5): 49.7% → 55.1% success rate (+10.9%)
- Sequential MaTTS (3 iterations): 49.7% → 54.5% success rate (+9.7%)
The scaling doesn't just improve performance on the current task—it permanently enriches the memory bank, improving all future tasks.
Benchmark Results: Does It Actually Work?
Let's examine the empirical evidence with appropriate skepticism. Claims of "self-evolving agents" demand rigorous validation.
WebArena: Interactive Web Tasks
WebArena tests agents on realistic web interactions: shopping, form filling, content retrieval across multiple sites. ReasoningBank's results:
| GPT-4 | 36.2% | 44.5% | +8.3% |
| Gemini-1.5-Pro | 38.1% | 45.3% | +7.2% |
| Claude-3-Opus | 41.8% | 46.4% | +4.6% |
These aren't marginal gains. An 8.3% absolute improvement on a benchmark where state-of-the-art hovers around 40% is substantial.
More importantly, the efficiency gains are dramatic:
- 16% fewer interaction steps to complete tasks
- 20-40% reduction in token usage
The agent isn't just more successful—it's more direct. It's learning to avoid dead ends.
SWE-Bench: Software Engineering Tasks
SWE-Bench tests agents on real GitHub issues: bug fixes, feature implementations, test writing. Here, ReasoningBank showed:
| Gemini-1.5-Pro | 54.0% | 57.4% | +3.4% |
A 3.4% gain might seem modest, but SWE-Bench is notoriously difficult. The current state-of-the-art is ~60%, and improvements at this frontier are hard-won.
Critical Analysis
Let's be precise about what these results don't show:
-
Long-term stability: All experiments ran for finite episodes. We don't know if memory quality degrades over thousands of tasks or if the bank eventually fills with low-quality patterns.
-
Cross-domain transfer: Tests focused on web browsing and coding. How well does ReasoningBank work for robotics, scientific reasoning, or creative tasks?
-
Catastrophic forgetting: The paper doesn't address what happens when the memory bank grows too large. How does retrieval scale? Do old, outdated strategies interfere with new ones?
-
Ground truth reliance: The "Judge" step assumes task success can be automatically determined. This works for web benchmarks (did the item get added to cart?) but many real-world tasks have ambiguous success criteria.
These aren't fatal flaws—they're research frontiers. The framework is barely six months old. What matters is that the core mechanism is validated: strategic memory distillation + self-judgment → measurable capability improvement.
What This Means for AI's Future
Step back and consider the paradigm shift here. For the past decade, AI progress has followed a simple formula: scale the model, scale the data, scale the compute. Bigger is better. GPT-4 has 1.7 trillion parameters. The training dataset is measured in petabytes.
ReasoningBank proposes a complementary path: scale through experience accumulation. The model size stays fixed. The training data doesn't grow. Instead, the agent becomes more capable by systematically extracting and applying lessons from its interactions.
This has profound implications:
1. Economic Viability
Retraining a frontier LLM costs millions of dollars. Adding memory to an existing agent costs the price of a SQLite database (free) plus embedding API calls (pennies). For organizations deploying agents at scale, this is the difference between "economically impossible" and "operationally viable."
2. Continuous Adaptation
Traditional ML requires you to collect data, retrain the model, validate, deploy—a cycle measured in weeks or months. ReasoningBank enables live adaptation. Deploy an agent on Monday, by Friday it's better at your specific use case. No MLOps pipeline, no retraining infrastructure.
3. Failure as Signal
Machine learning has always struggled with negative examples. How do you train on "what not to do"? ReasoningBank sidesteps this by making failures first-class citizens in the learning process. This could fundamentally change how we approach safety and robustness.
4. Towards Genuine Autonomy
Here's the big one: an agent that learns from experience is qualitatively different from one that doesn't. The latter is a tool—powerful, but static. The former is a learner, capable of growth and adaptation. This is a step toward AI that isn't just intelligent, but increasingly intelligent.
Of course, challenges remain. The current implementation relies on the LLM's ability to accurately self-judge, which is imperfect. The framework assumes task outcomes are well-defined, which isn't always true. And there's the looming question of how to manage memory at truly massive scale—what happens after a million tasks?
But these are engineering challenges, not fundamental blockers. The core insight—that strategic memory is a dimension of AI capability orthogonal to model scale—is sound.
We're witnessing the birth of memory-driven AI scaling. Not as a replacement for bigger models, but as a complement. The future might not be AGI through ever-larger neural networks alone. It might be AGI through systems that compound their intelligence over time, learning from every interaction, building wisdom from experience.
ReasoningBank is a first step on that path. And it's working.
Interested in building memory-enabled agents? Check out the open-source implementation or dive into the full research paper.