.png)

I have begun to truly embrace vibe coding over the last few months, using Cursor as my main code editor and Claude Sonnet 4 for my agent's LLM. It's an exciting time as a developer, we get to experiment with something that promises to 100x our productivity while pioneering the new workflows and strategies for implementing these tools.
But, as most people who have done any extensive development with LLMs in a sufficiently sized code base knows, it's a bit like trying to herd scared cats.
As your code base grows more complex and distributed, more of the context needs to be managed, more file-specific rules are needed, and it generally becomes more difficult to get quality output from your agent. Ironically, the better we organize our code, the more context management tasks the LLMs need to perform to locate it.
Even with a suite of AI tools reviewing our PRs, or generating tests, we still feel uneasy shipping AI generated code. How do we know our vibe-coded feature won’t take down production? How do we even know if it actually works at all? I have even seen my agents comment out huge portions of code just to get a build to pass.
There’s a blind-spot in the agentic code cycle, but we can fix it.
We can tweak prompts, add docstrings, or refine agent rules, but none of that solves the core issue: LLMs can't see what happens when their code actually runs. They're throwing darts in the dark, making change after change yet never able to correct their aim. In fact, any errors that show up in the generated code begin to multiply as the LLM iterates blindly on top of those issues.
Currently, context management largely relies on managing which files to include with a prompt. MCP (Model Context Protocol) brings us a little further, allowing us to exchange context information between multiple data sources.
If you currently use a tool like Cursor or Claude Code with limited MCP integration, your context likely only contains the source code of your app, maybe some documentation, and anything you might have copy and pasted in.
You might have run some code, and manually fed the logs into your LLM to help it solve issues. What we want to do is incorporate a feedback loop where we can generate code, collect telemetry on the execution, and then inform the LLM of those results so it can iterate on the solution with guidance.
To understand how we can close this feedback loop, let's first examine what traces are and how they can provide the missing execution visibility. With an MCP server, we can add that vital context to our LLM agent and close the visibility gap.
We use Sentry to monitor our apps for errors and performance issues in production. For every event in the application, such as navigating to a page, or clicking a button, the timing and flow of all app activity can be tracked and measured. Even through various distributed services, across regions and clouds.
This gives us a timeline of events, with a wealth of additional metadata that we can analyze, and use to verify that our code executed as expected, in-line with what we asked our AI to code for us.
Here’s a portion of a trace from one of my apps. You can see the trace contains both a React front end application, and a backend server running on Cloudflare Workers. With this trace “waterfall” view, we can break down what happened.
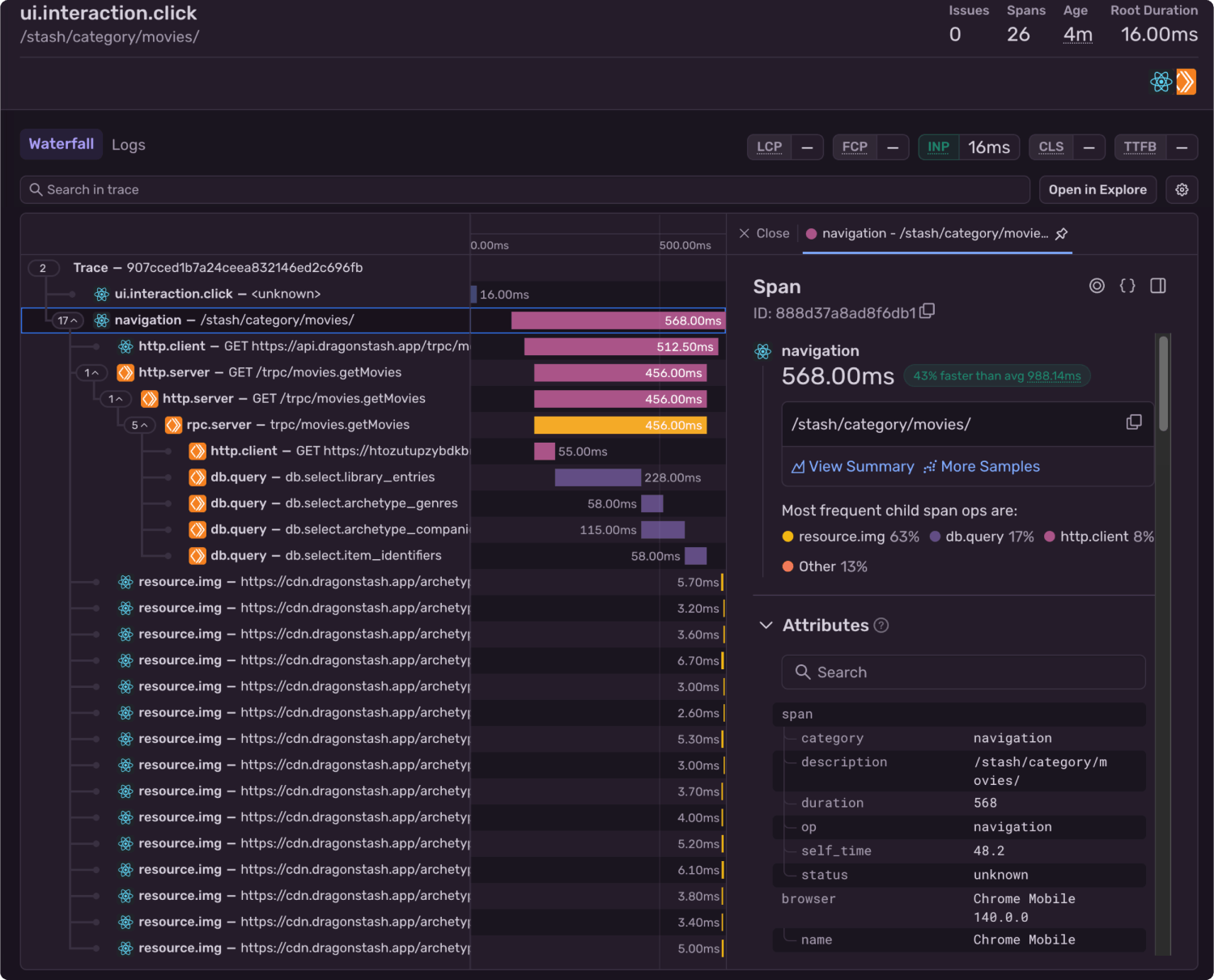
In this example, we can see the user navigated to a page /stash/category/movies/ , and all of the subsequent operations that kicked off from there took a total of 0.568 seconds.
Almost the entire time was taken up by database queries. The db.select.library_entries query is twice as long as the next longest query. If we were focused on optimization that might be where we start. After the database queries finish, the frontend grabs a bunch of images, which if we were to dig into deeper, we would see they were cached locally.
But what we really need to do is feed this type of data back into our LLM so we can automatically analyze the results, and make any changes if needed.
Sentry offers a hosted MCP server that can be easily added to any MCP-capable client such as Claude Code, ChatGPT, or Cursor. For Cursor & VS Code you can install it as an extension with a single click. For other clients, you may need to copy and paste a small snippet from the MCP docs into your editor.
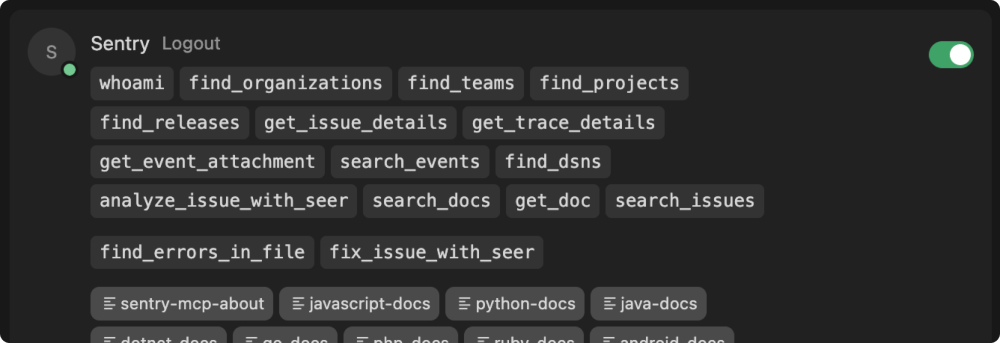
Once authenticated, the MCP server will provide your agent with Sentry documentation to help automatically instrument traces in your app if they are not enabled yet, and a number of tools that the agent may call to fetch additional context about how your app behaved when executed.
Now we can ask our agent to summarize and investigate the latest events in our app. For speed and accuracy, I still like to feed the specific trace or span ID that I want to investigate, but you can also just do a search like:
Click to Copy

If configured correctly, you'll see that your agent understands it should be using the MCP provided tools to fetch the additional context.

The response, in my case generated by Claude Sonnet 4, contained a break down step by step with timing information of what happened, and provided suggestions for potential performance improvements, particularly around image loading.
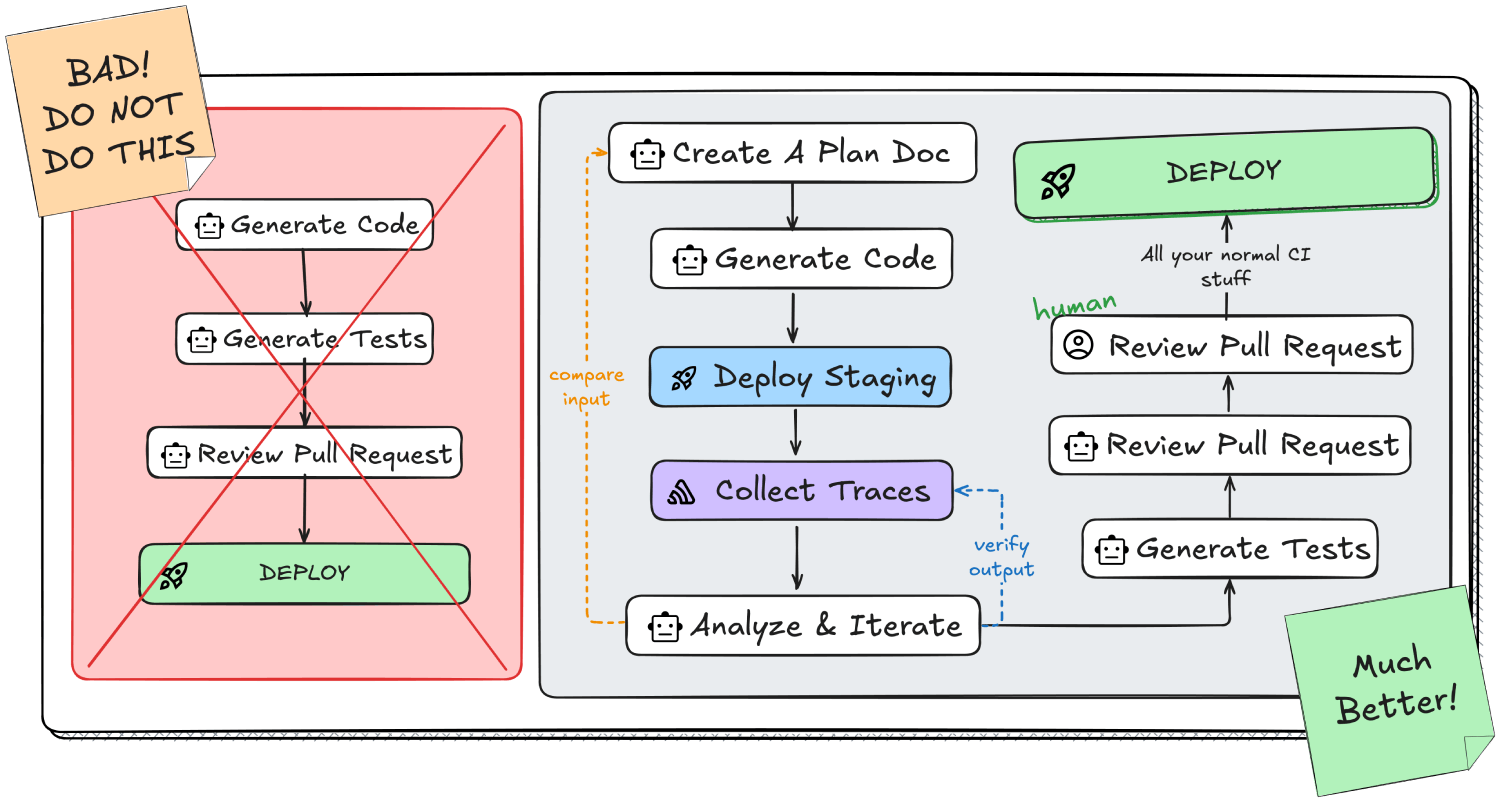
Let’s close the loop and give our agent full visibility into our application. Not just the source code, but the results of running that code. Here is a workflow I use when implementing new features in my vibe-coded apps.
Start by drafting a plan document in a fresh branch. This gives you a persistent artifact that outlives the LLM’s context window, making it easier to track changes and validate assumptions.
Example prompt:
Click to Copy
Once your plan doc is ready, start a new chat window with a clear context window and feed it your document. Ask the LLM to implement the plan as described.
These types of longer operations are where I like to use Cursor background agents, where we can leave them running mostly unattended without the need for much intervention. Taking advantage of file-based rules for your agents too, to provide specific context and instructions for critical components of your app.
Deploy to a staging environment (or a local dev server), and test out your new feature. Good ole’ QA testing. The easiest way to make sure the code wasn’t total junk (besides reading it), is to just try it out.
If you haven’t instrumented Sentry in your app, you’ll want to do that before deploying and testing, so we can collect metrics on what happens during that testing. You can set the Environment tag in your Sentry init to distinguish and filter between production/staging/etc.
Finally, the crucial step where we take that data and close the feedback loop. We now have a plan doc that describes what the LLM was originally aiming to have accomplished, and we have executed that code with tracing enabled, allowing us to verify what actually happened.
Now, let’s ask the LLM to compare the trace data from Sentry with the plan doc, and verify everything went according to plan. We are looking to see if any functions were not called, database queries not made, and any errors captured.
Trace verification prompt example:
Click to Copy
Don’t forget the rest of the guardrails. We are waging a war against random chaos, and the best weapons we have, are many layers of automated checks and validation... and humans. Run your typical CI workflows — check your linter, your type checker, formatter, unit tests, integration tests, e2e-tests, etc.
Sentry can also both generate tests for your pull request, and review it, automatically. Once you are confident you have generated good, clean, efficient, and composable code, protect it with tests. Testing is famously overlooked, either because it's tedious or just because of poor practices. With the plan documentation and code changes in context, it's possible to automatically generate fairly high quality tests.
I doubt anyone can accurately predict what the nature of agentic development flows will look like in the near future. But it's safe to assume we won't abandon good software and CI practices, even if they become less rigid while we figure things out.
What's likely is that we'll adopt current practices at greater scale with tighter guardrails. Will code coverage % finally become an important metric? Will we begin enforcing docstrings in our linters? As AI agents become more sophisticated, the practices that seemed "nice to have" may become essential for maintaining code quality at machine speed.
The feedback loop we've put together is just the first step in the right direction. Sentry recently released an AI agent called Seer, which operates with the full context of your app's stack traces, commit history, logs, errors, and traces to automatically fix production issues as they happen.

Seer can be configured to react to newly captured errors and generate pull requests automatically. Then AI tools like GitHub Copilot or Sentry's @sentry review can provide code suggestions on the PR. You can keep re-requesting reviews and merging changes until you're satisfied with the solution, and finish it up with new tests @sentry generate-test, all without leaving the PR.
We're moving beyond the era of "hope and pray" LLM agent coding by borrowing from reinforcement learning: introducing feedback loops that let our agents observe their actions, "learn" from the results, and continuously improve.
We're pioneering the landscape for the next decade of development and CI practices. It's a rare and exciting opportunity to shape how software gets built tomorrow.