.png)

You read the Terms & Conditions, right? You didn’t just click the checkbox? And the Privacy Policy, you understood everything in there?
Me neither. These kinds of documents are supposed to inform us of how our data is handled and the rights we have when using a website or app. Unfortunately, they’re usually either an unintelligible soup of legalese, or so long that they’d take a full afternoon to read. Companies have little incentive to provide summaries – they’re usually just filling a legal requirement.
Terms of Service; Didn’t Read (ToS;DR) has been trying to fix this. For each digital service they provide a collection of statements in yes/no format – for example, “This service tracks you on other websites” – that together offer a decent summary of the service’s policies. They even aggregate these statements into overall grades (Wikipedia gets a “B”), and offer browser extensions so you can see grades as you browse the Web.
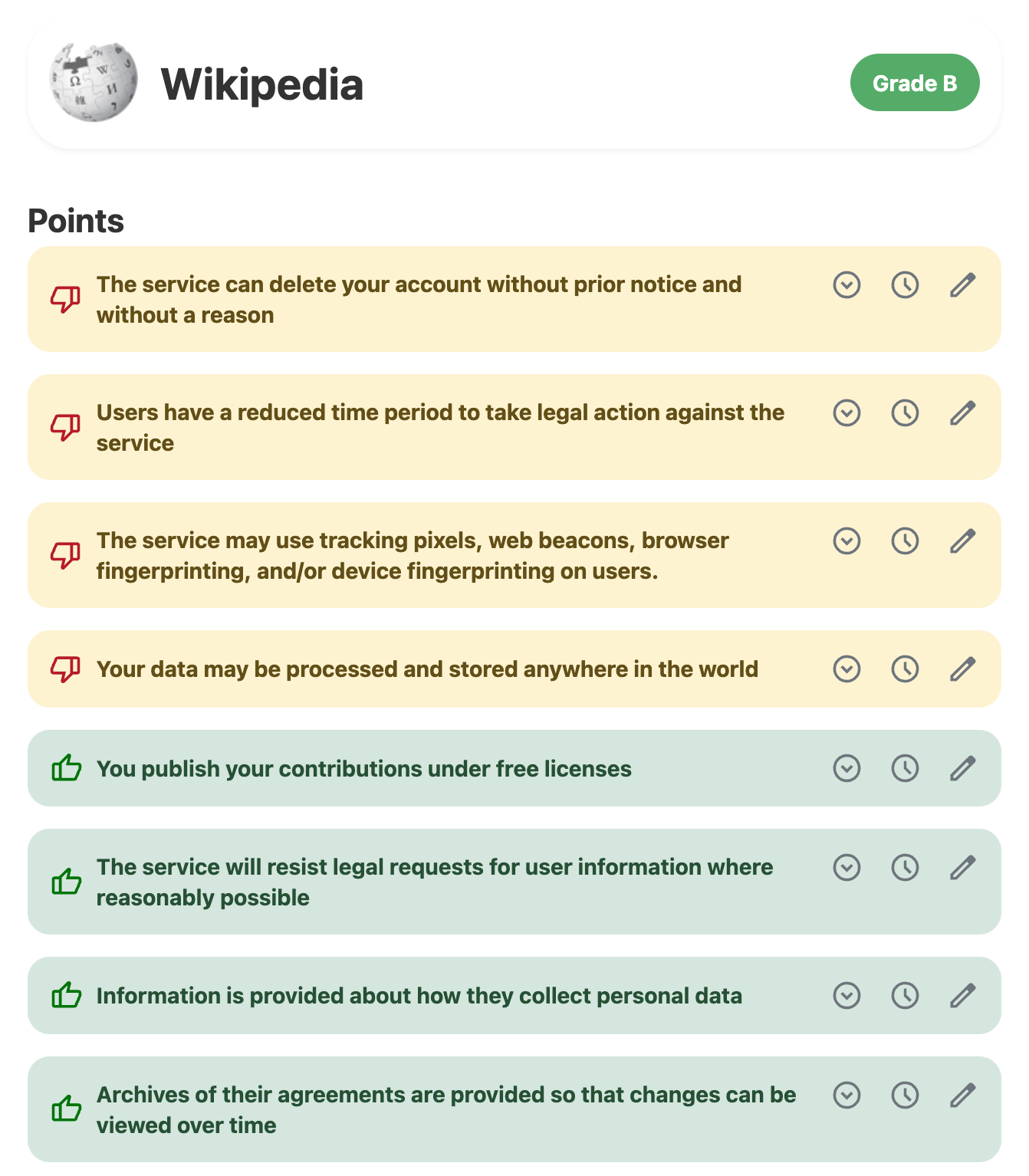
Historically ToS;DR has relied solely on volunteers to do the tedious work of reading and annotating privacy documents. This is a heavy bottleneck on coverage. To date it has around 10,000 websites and apps catalogued, only ~8,600 of which are graded. It’s a great start, but it obviously falls short given how many websites and apps are out there handling your data.
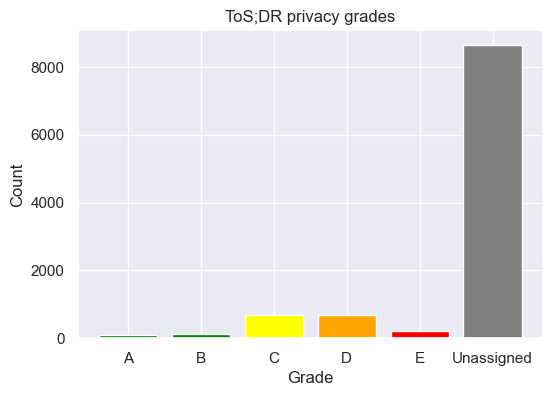
The vast majority of websites on ToS;DR have yet to be graded. Data from December 2024.
Automation
To help, I teamed up with ToS;DR to scale their efforts of annotating and scoring privacy agreements with help from AI, a solution we call Docbot.
Specifically, I’ve used the human annotations collected over the years to train classification models that can estimate the strength of evidence for particular statements in privacy documents. If the models find evidence that scores above a certain threshold, the relevant excerpts are submitted to human curators. Once approved, the statement summaries are used automatically when calculating grades.
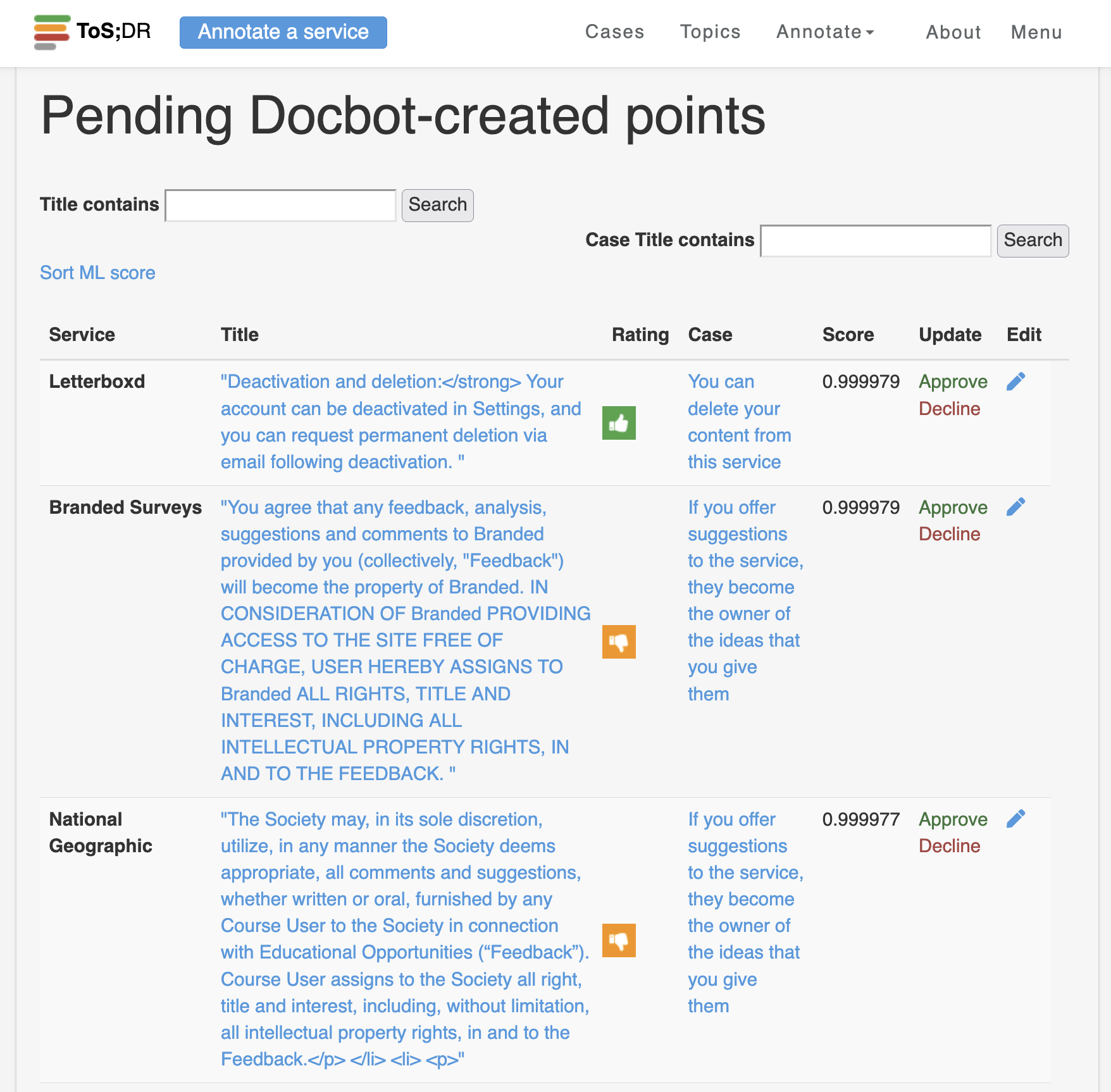
The output of Docbot – a queue of observations about privacy documents for human curators to later approve or reject. ‘Rating’ refers to whether the observation is a positive or negative thing for privacy, while ‘Score’ refers to the strength of evidence.
In the remainder of this post I’ll share my experience developing the solution and ultimately putting it to use within ToS;DR.
As mentioned above, ToS;DR has come up with a taxonomy of privacy-related statements that you might want to know about a digital service. We call these Cases, and here are some examples:
- Your personal data is not sold
- You must provide your legal name, pseudonyms are not allowed
- Tracking cookies refused will not limit your ability to use the service
- Your data is processed and stored in a country that is less friendly to user privacy protection
- The terms for this service are easy to read
- … and over 100 more
For each Case I trained a binary classification model that takes as input one or more sentences, and outputs a 0.0-1.0 score where 1.0 means there is extremely strong evidence that the Case statement is true. Like many other text classification problems, this was a good fit for fine-tuning.
Key to this approach was that not only did ToS;DR have data on which Cases are present in which documents, but specifically which excerpts provide the evidence. These can fit inside the context windows of transformer models during training, and most importantly, our solution can try different excerpts to find any that are high-scoring enough for submission to ToS;DR curators. Ideally, these AI submissions will look indistinguishable from those submitted by humans.
Sentence classification is a common problem in NLP, and this is almost that. There were two differences here that I had to figure out: 1) we wanted to apply the models to full terms of service documents and privacy policies, often with many thousands of words. We only wanted to extract the most convincing excerpt, even if multiple sentences in the document were relevant. And 2) sometimes policies are communicated in short paragraphs instead of single sentences, and we ideally wanted to preserve these spans of text as logical units, instead of only working at the single sentence level. Put another way: the problem actually sits somewhere between sentence classification and document classification.
My solution for inference (using the models) was:
- Split the document into sentences
- Apply the model to each sentence individually
- Take the highest scoring sentence, and see if appending additional neighboring sentences makes the score go up (until some limit, e.g. 5). If so, keep them.
- See if prepending prior neighboring sentences makes the score go up even more. If so, keep them.
- Use the final sentence span and score as the result for the document.
Forming Datasets
Much of the work for supervised classification approaches like this lies in designing effective training and evaluation datasets.
At the very least I needed a dataset of sentence spans to train each binary classifier, with positive and negative examples. These datasets could also be useful for evaluating models, but they didn’t seem fully adequate. Since our models were ultimately being applied to entire policy documents, I formed a companion dataset of full documents to evaluate against. For one, the accuracy metrics would be much more intuitive compared to the sentence span dataset with different class ratios. But also, it would evaluate my models in the same context in which they will be used in the real world, with the “highest score” inference procedure described above.
Sentence Span Dataset
Positive examples here were easy – each Case had a collection of verified quotes submitted by ToS;DR volunteers over the years, sometimes in the hundreds. I decided to only tackle Cases for which we had at least 40 positive examples, leading to 123 Case models in total. The remaining could some day be covered using other text classification methods like SetFit or few-shot prompting LLMs.
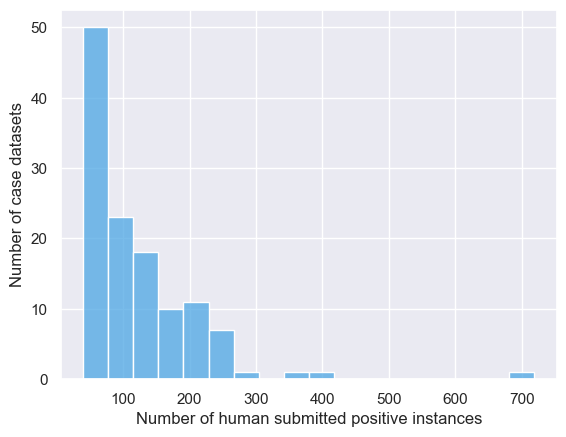
Negative examples
These were trickier. Obviously with such long documents, searching for proof of individual Case statements is like finding a needle in a haystack, and so there is plenty of hay – completely irrelevant sentence spans. One problem to be aware of is extreme class imbalance; sampling uniformly from entire documents would probably not end well.
The other big problem is that we don’t just want models to lazily learn to recognize the topic of a case. For example, we don’t want a model learning the case “Tracking cookies refused will not limit your ability to use the service” to just score highly any time it sees a statement about cookies. The solution here is to expose the model to plenty of “hard negatives”, which contain similar terms and force the model to more carefully discriminate.
For each case I put together a set of negative examples containing:
- Human submissions that were later rejected
- Sentence spans that surround positive examples. This approach is prone to accidental true negatives, but I believe it should help to sharpen the discriminative power of models.
- The ToS;DR taxonomy actually groups cases into topics, so I included approved submissions from other related cases
- Other random sentence spans from documents containing positive examples
- Random sentence spans from comprehensively reviewed documents that do not contain positive examples
Another helpful source of negative examples could come from manually constructing logical negations of positive examples. Assertions that data practices are not carried out are rare, but they exist. Using negations could lead to more robust models that can handle these correctly – instead of just learning phrases, they would have to learn to analyze the statement’s modality. I didn’t include these in our first model versions, but a similar project called MAPS[1] took this approach.
Another future direction is hard negative mining with vector similarity search, which would help surface examples right on the edge of what we’re trying to learn.
Sentence length bias
When constructing training examples, it’s important not to introduce any unintended biases. The models should learn to discriminate between positive and negative examples by way of learning the underlying task at hand, rather than learning irrelevant characteristics of the constructed examples that you introduced.
For example, here the human submitted quotations (positive training instances) could be any number of sentences. If our constructed negative instances were only one sentence, a model could theoretically learn the rule “If I’m shown multiple sentences, it’s positive.”
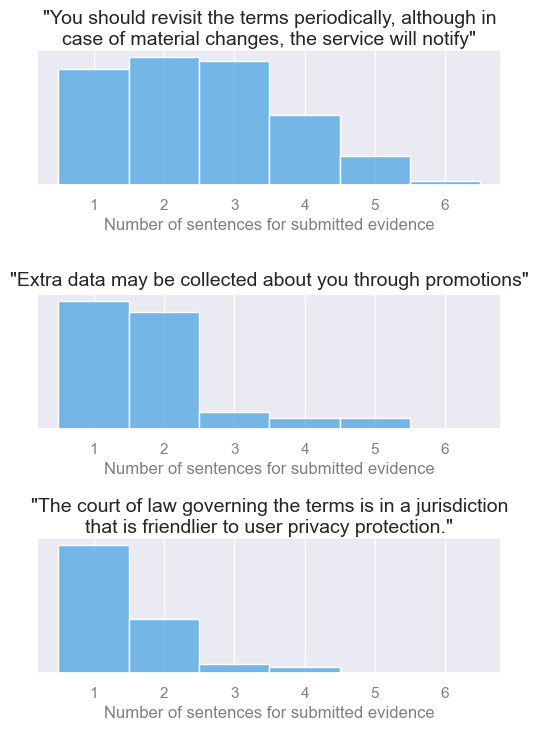
My solution here was to model each case’s typical number of sentences for submitted evidence as a multinomial probability distribution, and sample from it while constructing negative instances.
Another potential source of bias is that submissions don’t necessary have to begin and end at sentence boundaries – people can highlight partial sentences, even short phrases. Rather than try to replicate typical start and end times for each case, I decided to just expand positive instances to begin and end at their surrounding sentence boundaries. This restricts the resulting models to also only yield full sentence predictions, but that’s fine, and it avoids any related bias issue.
Document Dataset
The dataset of full documents (privacy policies, terms and conditions, cookie policies, etc.) was more straight-forward. Positive instances were those which had an approved submission of evidence from ToS;DR volunteers. Negative instances included documents that were comprehensively reviewed by volunteers without the case ever coming up, or rejected submissions if there were any.
This was utilized for evaluation only, using my custom “sentence expansion” inference procedure. It correlated with performance on the sentence span dataset used for training, but I think it’s more trustworthy for model selection because it’s closer to how we use the models downstream.
The only “gotcha” was to prevent data leakage by stratifying train/test splits the same way I did for the sentence span dataset: by website/service. I first split services into two groups 80-20, and then partitioned both datasets accordingly.
I relied on the tried-and-tested fine-tuning of BERT family models using huggingface. bert-base-uncased, roberta-base, and a finetune of legal documents legal-bert-base-uncased all performed about the same. ModernBERT looks great, but wasn’t yet released at the time of training. Rather than fine-tuning the full base models I decided to train more parameter efficient LoRA adapters [2], via the huggingface peft library.
Interestingly the vast majority of time spent during training was actually the evaluation loop, when full documents were analyzed. This could surely be sped up by not re-running obviously unrelated sentences, but that’s an optimization for another day. This means using LoRAs didn’t actually have much of an effect on training speed, but they were still nice for disk space efficiency (each of the 123 models is just a 2.8MB adapter file), and there was virtually no reduction in accuracy compared to a full fine-tune.
As is typical when fine-tuning LLMs, accuracy can differ a decent amount depending on the random seed. This means it was beneficial to attempt training each Case multiple times, taking the highest test set accuracy observed across all attempts.
Training was carried out on vast.ai instances, using Weights & Biases to track experiments and visualize metrics.
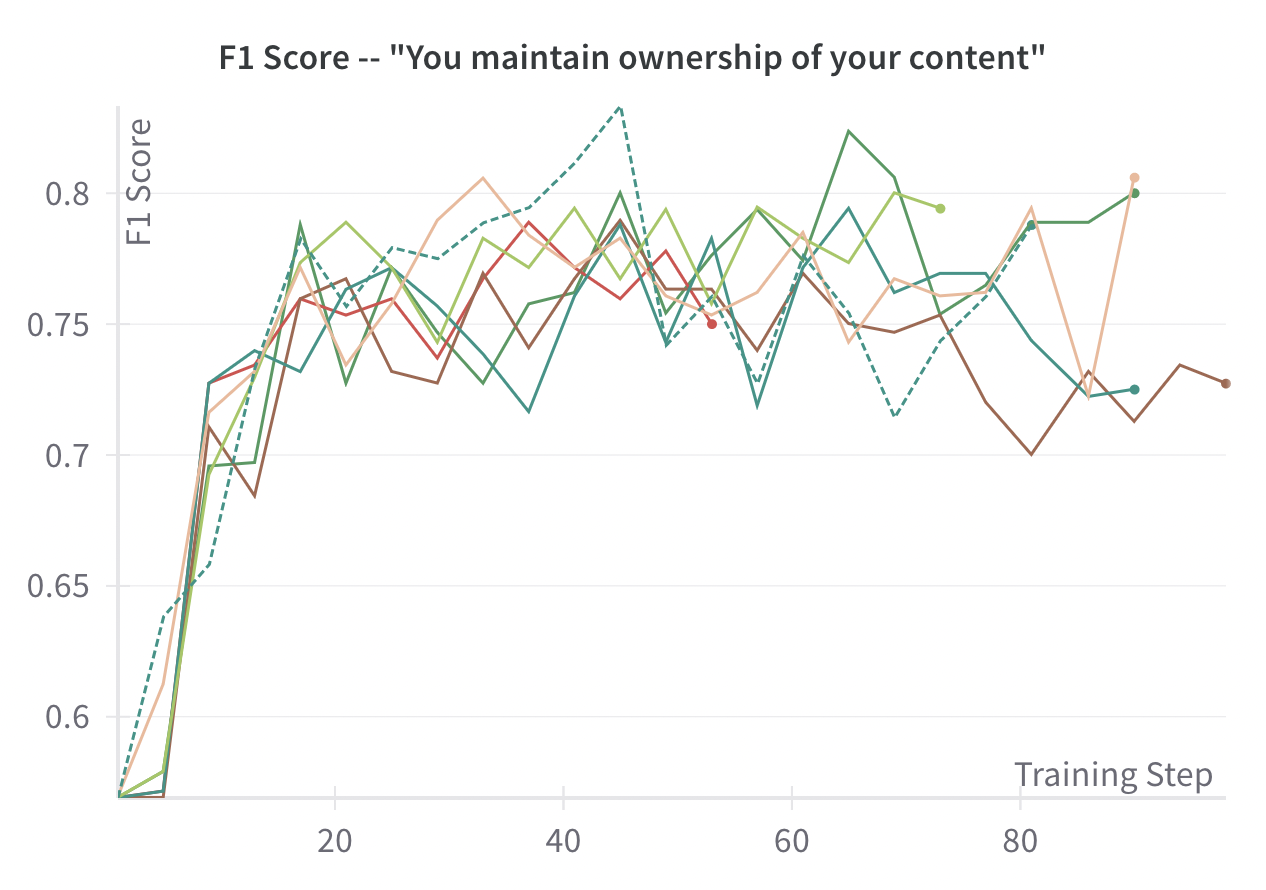
Training curves for multiple restarts of one case model in particular – “You maintain ownership of your content”. The y axis shows F1 score on the test set fold of the full document dataset.
What about just prompting LLMs?
Few-shot prompting is another way to perform text classification. Sometimes it’s the right tool for the job, especially when training data is hard to come by and you want a quick solution. For this problem I opted for fine-tuning because of it’s potential for higher accuracy at low cost, and because it provides interpretable and reliable confidence scores with each prediction.
LLMs could still be useful to help bootstrap Cases with very few training examples, and to audit training datasets for true negatives.
Model and threshold selection
I used early stopping to halt training, and selected the model checkpoint that maximized F1 on the full document dataset across all restarts.
One benefit of using regression models or neural networks for classification is that we can choose prediction thresholds at our preferred place on the precision-recall curve. Since we planned to send AI submissions to human curators before use in privacy grades, a lower threshold was preferable. This would mean more false positives crowding the approval queue (lower precision), but would ensure better coverage finding matches (higher recall).
I found that a single static post-softmax probability threshold would not work across Case models, as they were not very consistent in their relative implied confidence. And with 123 models in total, it was best to automate threshold selection by maximizing an objective criteria. F-score is a great choice because it incorporates both precision and recall and allows us to specify a tradeoff preference using the beta parameter. In my case I used a beta of 1.5 to prefer recall. The charts below show precision-recall curves and the corresponding f-scores as we vary the classification decision thresholds from 0.0 to 1.0.
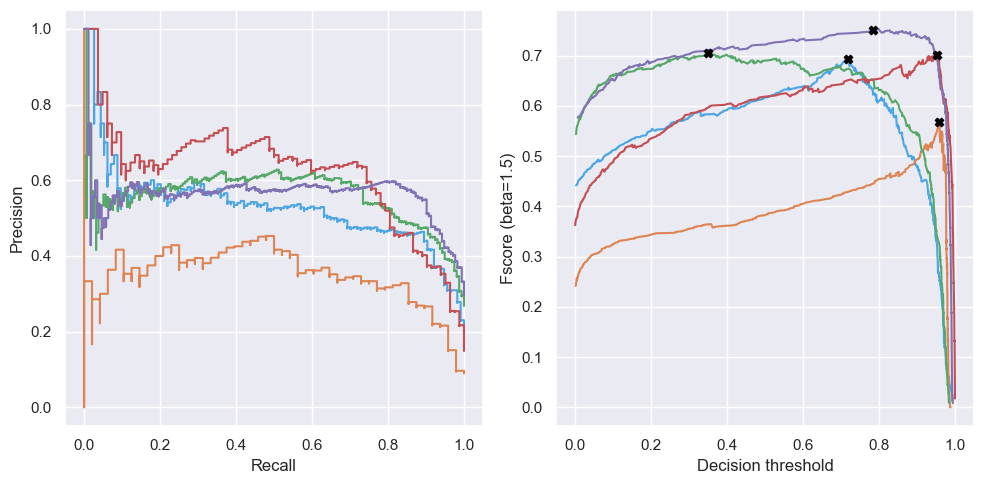
On the left, precision-recall curves of five different case models. On the right, available f-scores for the same models, as a function of the decision threshold that could be used for classification. A black X marks the optimal point.
Results
Model accuracy varied quite a bit by Case.
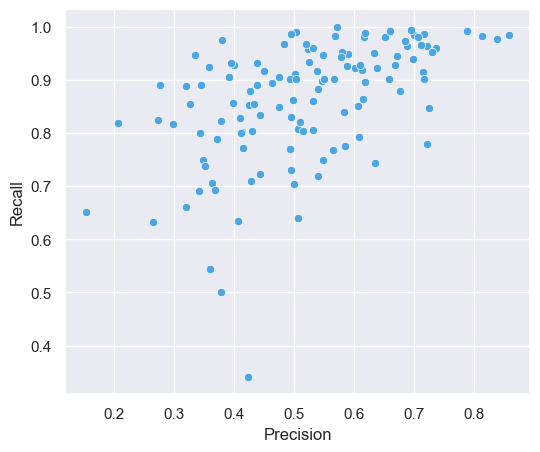
Precision and recall for all 123 Case binary classification models.
Sorting by f-score shows us the best and worst performing models:
| 0.942 | The service is provided ‘as is’ and to be used at your sole risk |
| 0.929 | Do Not Track (DNT) headers are ignored and you are tracked anyway even if you set this header |
| 0.923 | You are tracked via web beacons, tracking pixels, browser fingerprinting, and/or device fingerprinting |
| 0.919 | You waive your right to a class action |
| 0.884 | You have a reduced time period to take legal action against the service |
| … | … |
| 0.455 | Private messages can be read |
| 0.443 | You cannot distribute or disclose your account to third parties |
| 0.430 | The terms for this service are easy to read |
| 0.363 | Logs are kept for an undefined period of time |
| 0.328 | A free help desk is provided |
Prediction accuracy was higher for more strictly defined Cases that often use consistent language across privacy documents. Accuracy was lower for Cases with lots of edge cases, or ones with lower quality training sets.
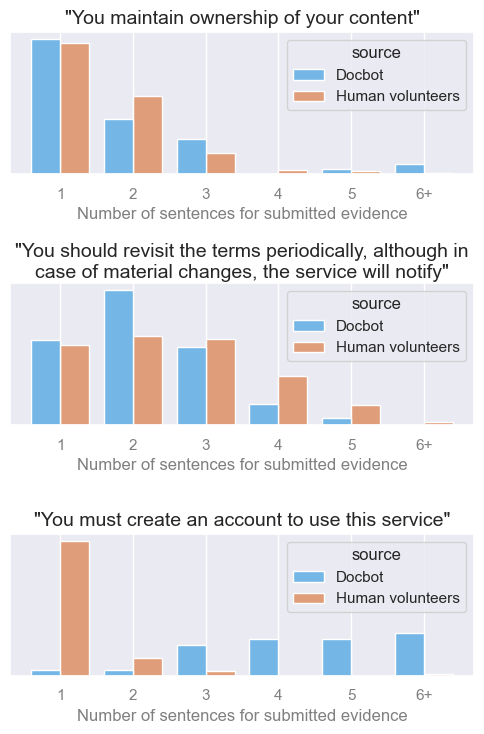
When it comes to the quoted evidence submitted for approval, generally the Docbot submissions looked just like those from humans. They did tend to be a little longer on average, in part because they had to adhere to sentence boundaries, but also because too many sentences were appended during the inference procedure. The chart below shows differences in distributions of the number of sentences for a few random Cases, and you can see some are worse than others. This can be refined in future versions.
There was no need to have our models hosted as an API, since we just need to apply them once for each privacy document as a batch job. New services and documents are added to ToS;DR regularly, and so we can re-run the inference jobs daily or weekly.
To keep track of which documents have been already been analyzed by Docbot, we added a new database table that stores the results of inference: document ID, Case ID, Docbot version, the start and end character positions of the highest-scoring sentence span, and the probability score. This allows for audits and keeps us from running the same model on the same document twice. In the future we’ll likely also use a job queue to facilitate inference parallelization.
I also decided to have the inference job re-consider documents for which the human curators rejected a previous submission. If Docbot (or a human) thinks it found evidence for a Case but was wrong, that doesn’t mean evidence doesn’t exist elsewhere in the document. Previously rejected sentence spans act as “off limits” areas during inference.
After setting up APIs for Docbot to interact with the ToS;DR backend, we made a new frontend for the Docbot submission queue. Once again here’s what that looks like:
A preview of the queue shown to human curators who can approve or reject Docbot submissions.
Submissions are sorted by descending confidence score so that the most likely approvals are at the top. Curators can also filter by Case, if they just want to churn through the results of a single model.
The Impact
ToS;DR only assigns privacy grades to a service when it has enough knowledge about its policies, meaning it has enough approved evidence submissions. Thanks to Docbot, the bottleneck on grade coverage has now shifted from volunteers initially reading through and annotating documents, to volunteer curators that double-check submissions as a final sign-off.
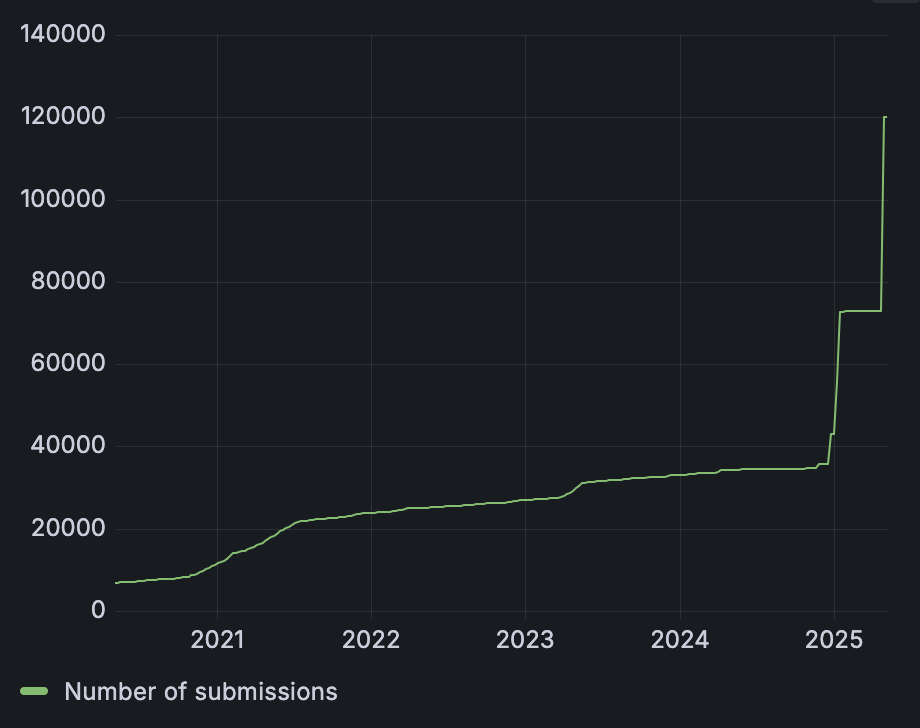
The number of submissions of evidence for Cases from either humans or Docbot over time. The two big jumps to the right are from the first runs of Docbot. By the time remaining Cases are run, we expect there to be over 300,000.
In the coming months we’ll explore ideas for easing that bottleneck, such as:
- A Tinder-style swiping interface for approving or rejecting Docbot submissions more quickly on the go. We do have to be careful to make sure curators still apply enough scrutiny, for example by having redundent approvals and measuring inter-rater reliability.
- Rather than working through giant queues of submissions, encouraging curators to go service-by-service to increase grade coverage more quickly, starting with the most popular ungraded services.
Beyond optimizing the approval process workflow, we are also exploring options for how to incorporate Docbot more directly:
- Publishing fully automated grades for services, when we don’t yet have enough human-approved submissions
- For very high confidence predictions (say, a score >.99) we could auto-approve
They key challenges with both of these approaches are to 1) choose the right score thresholds to balance false-positives with coverage, 2) have an understanding of model biases, and their effect on end grades, and 3) adequately communicating everything to our users and API consumers. People have grown to trust ToS;DR, and ultimately any incorporation of AI has to be done carefully to maintain that trust.
This was a really fun side project. I got to work with a unique dataset, help solve a real world pain point, and contribute to free and open source software. Part way through this experience, I was invited to join the core dev team at ToS;DR.
Future directions
I previously mentioned how we’d like to apply Docbot more directly by assigning tentative grades using fully automated analyses. And, we’d like to build better interfaces for double checking Docbot submissions. Beyond that, there is still so much to do!
- More efficient inference, by doing a first pass that excludes paragraphs with no remote relevance to the Case topic.
- Use Docbot to audit for mistakenly approved points already in ToS;DR
- Automated retraining of models, CI/CD
- Expand coverage to non-English languages
- Expand coverage to Cases with very few training examples
- Release datasets for NLP and legal researchers, open source the LoRA adapters
- Put out a tool to help service owners craft their privacy docs to be more privacy friendly, by getting feedback in real time
- Beyond binary statements, extract targeted information from privacy docs, like a list of what data are collected, and how long the service keeps it
Other things that would help with digital privacy
- Crawling the web to automatically add services and privacy docs
- Regulation for companies to provide easier to understand summaries, as GDPR does, and protocols for machine-readable policies, as IEEE proposes
- Tracking data leaks and privacy scandals
If you found this project interesting you can help us by contributing analyses on edit.tosdr.org, getting in touch to contribute to development, or even donating.
References
- [1] S. Zimmeck. MAPS: Scaling Privacy Compliance Analysis to a Million Apps, 2019.
- [2] E. Hu. LoRA: Low-Rank Adaptation of Large Language Models, 2021.



