.png)

This post explores these questions through detailed fio(1) benchmarking, looking at random reads, random writes, and latency — all running on a recent build of OpenBSD 7.7-current.
OpenBSD 7.7 (GENERIC.MP) #624: Wed Apr 9 09:38:45 MDT 2025 [email protected]:/usr/src/sys/arch/amd64/compile/GENERIC.MPTest Setup #
- Storage: 1TB Crucial P3 Plus SSD M.2 2280 PCIe 4.0 x4 3D-NAND QLC (CT1000P3PSSD8)
- Tool: fio, installed via OpenBSD packages
- Test File Size: 64 GB (to bypass RAM cache)
- Block Size: 4 KiB
- I/O Depth: 32
- Job Counts Tested: 1 to 32
- Runtimes: 30s runtime per test, 10s ramp-up
Results at a Glance #
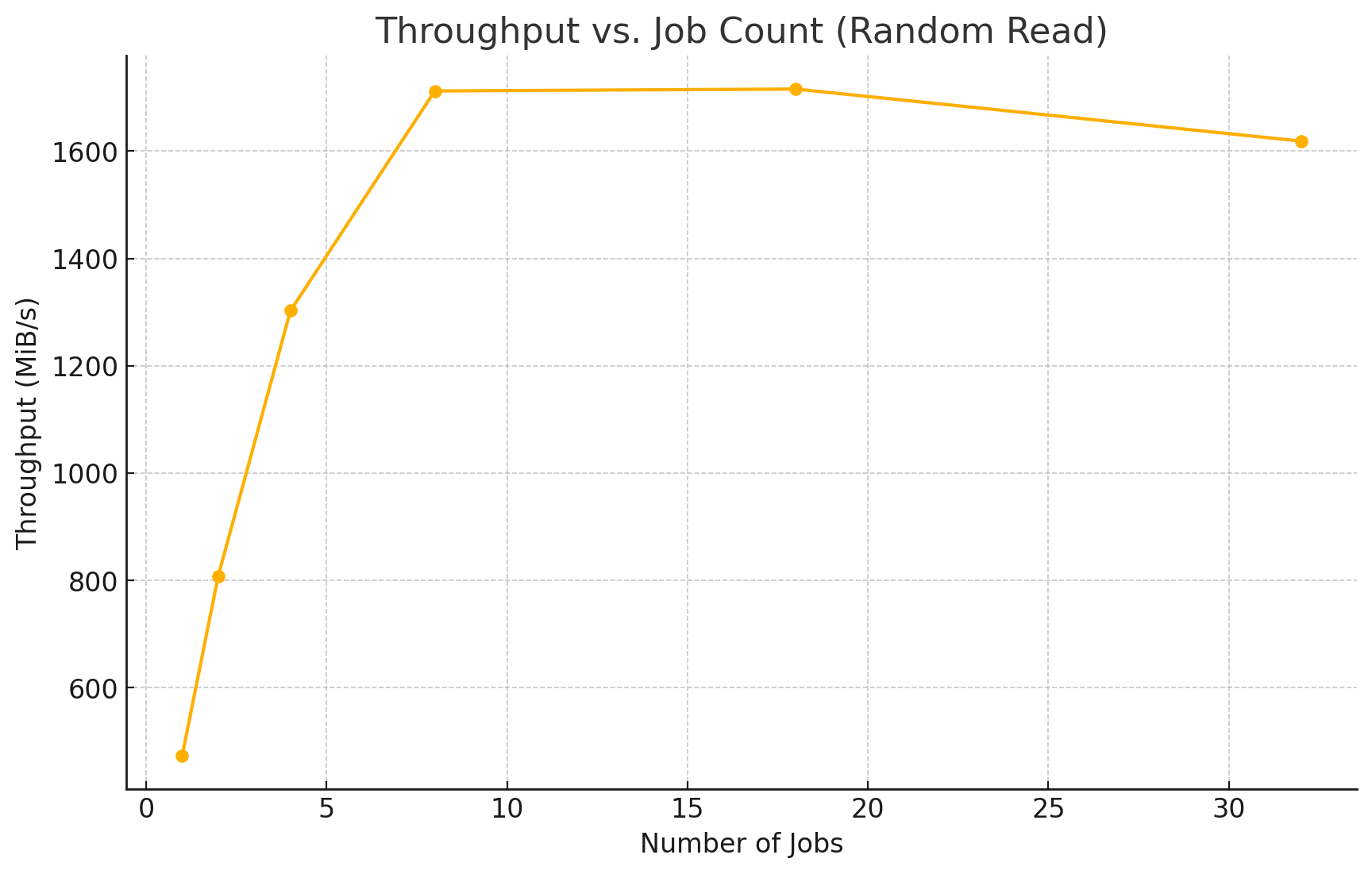
Throughput vs. Job Count (Random Read)
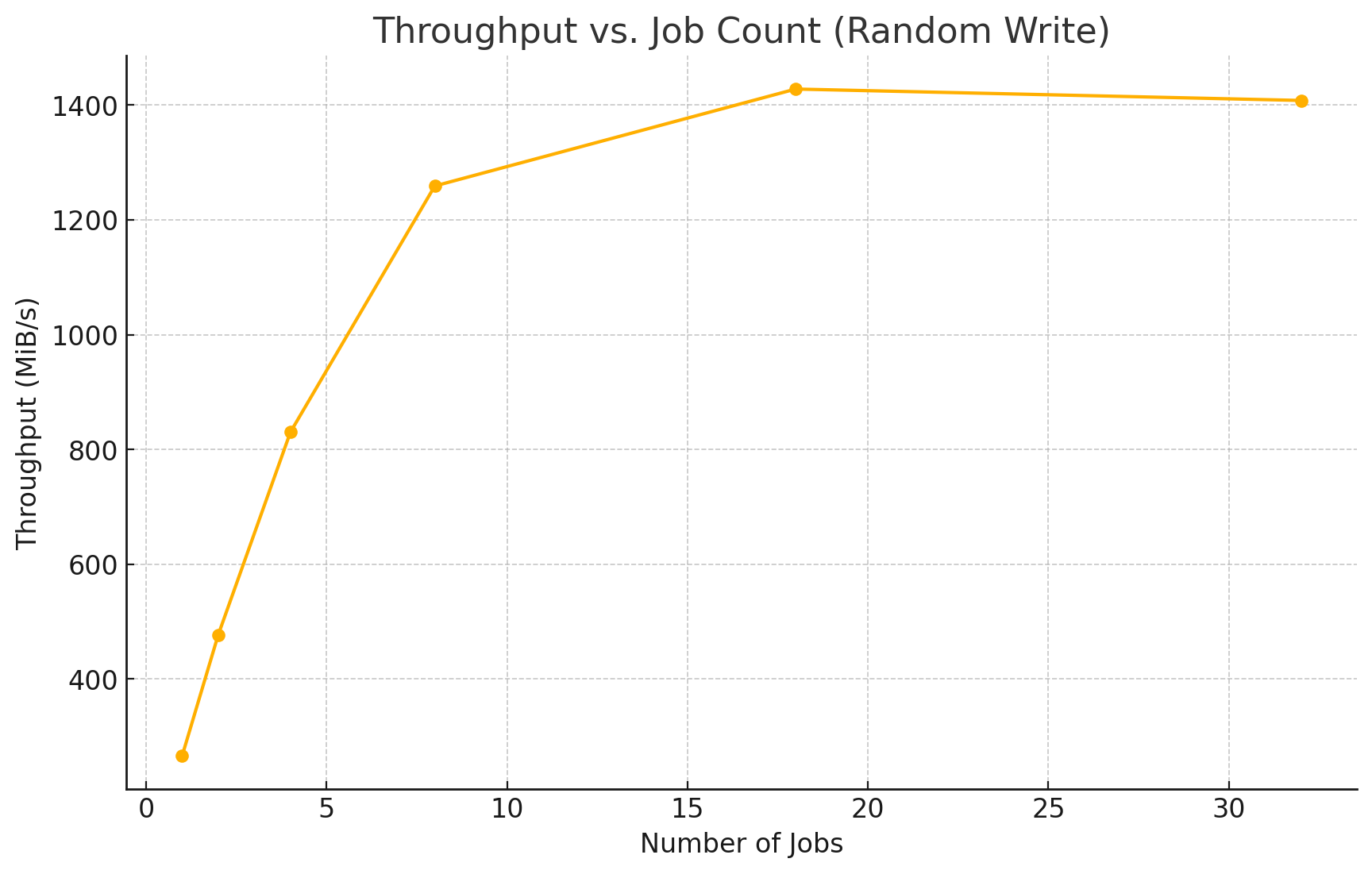
Throughput vs. Job Count (Random Write)
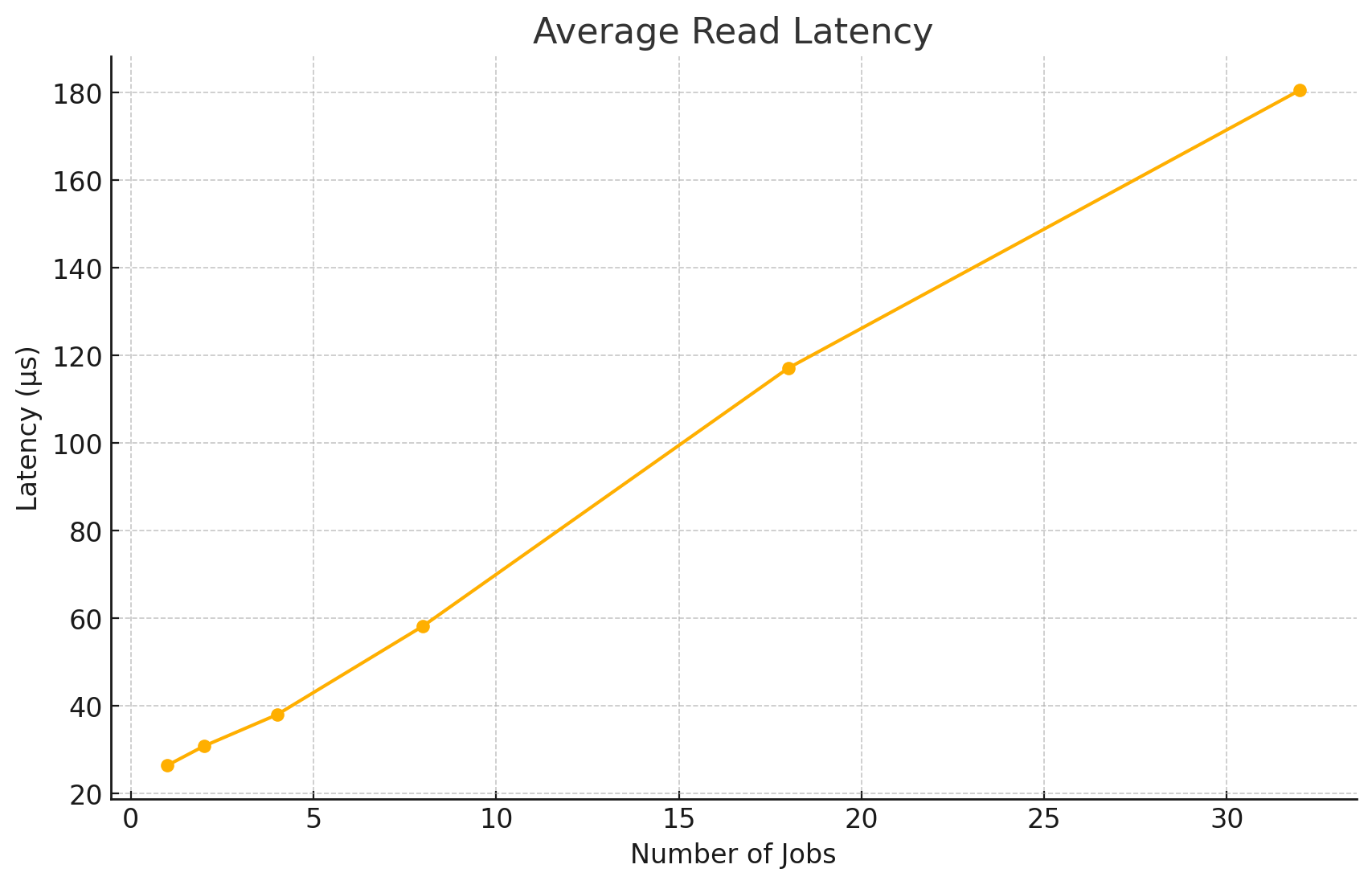
Average Read Latency
Average Write Latency
Summary Tables #
Random Read Performance #
| 1 | 473.0 | 121,318 | 26.41 | Baseline |
| 2 | 808.3 | 207,333 | 30.80 | Strong scaling |
| 4 | 1,302.4 | 334,219 | 37.97 | Excellent parallel read gain |
| 8 | 1,712.0 | 439,728 | 58.22 | Near peak performance |
| 18 | 1,715.6 | 439,661 | 117.12 | Saturation reached |
| 32 | 1,618.6 | 415,603 | 180.56 | Slight regression, high latency |
Random Write Performance #
| 1 | 265.6 | 68,223 | 58.64 | Baseline |
| 2 | 476.6 | 122,246 | 63.27 | Good scaling |
| 4 | 829.9 | 212,610 | 70.84 | Steady performance increase |
| 8 | 1,259.1 | 323,439 | 95.72 | Approaching write peak |
| 18 | 1,428.1 | 366,830 | 172.17 | Plateau with rising latency |
| 32 | 1,408.2 | 361,404 | 230.42 | Regression due to contention |
Latency Overview (Read vs Write) #
| 1 | 26.41 | 58.64 | Minimal latency, sequential load |
| 2 | 30.80 | 63.27 | Low contention |
| 4 | 37.97 | 70.84 | Balanced performance |
| 8 | 58.22 | 95.72 | Sweet spot for throughput vs latency |
| 18 | 117.12 | 172.17 | Steep latency increase |
| 32 | 180.56 | 230.42 | High CPU & queue contention |
Observations #
- OpenBSD scales I/O quite well up to a point — notably better than expected.
- Job count sweet spot: Between 6 and 8 jobs gave the best balance of IOPS and latency.
- Too many jobs degrade performance due to increased contention and CPU overhead.
- NVMe write performance is sensitive to concurrency on OpenBSD, more so than reads.
fio(1) Linux vs. OpenBSD #
Based on this test script I ran a simple benchmark between Linux version 6.12.21-amd64 ([email protected]) (x86_64-linux-gnu-gcc-14 (Debian 14.2.0-19) and OpenBSD 7.7 (GENERIC.MP) #624: Wed Apr 9 09:38:45 MDT 2025 [email protected] on ThinkPad X1 Carbon Gen 10 (14" Intel).
#!/bin/sh # Common fio parameters BLOCK_SIZE="4k" IODEPTH="1" RUNTIME="30" SIZE="1G" FILENAME="benchfile" # Output directory OUTPUT_DIR="./fio-results" mkdir -p "$OUTPUT_DIR" # numjobs to test NUMJOBS_LIST="1 2 4 8 16 32" # Test types for RW in randread randwrite; do echo "Starting $RW tests..." for J in $NUMJOBS_LIST; do OUTFILE="$OUTPUT_DIR/${RW}-${J}.json" echo "Running $RW with numjobs=$J..." fio --name="test-$RW" \ --filename="$FILENAME" \ --rw="$RW" \ --bs="$BLOCK_SIZE" \ --iodepth="$IODEPTH" \ --numjobs="$J" \ --size="$SIZE" \ --time_based \ --runtime="$RUNTIME" \ --group_reporting \ --output-format=json \ --output="$OUTFILE" done done| 2 | 5.78 | 1478 | 1343 | 13.23 | 3388 | 595 |
| 4 | 9.92 | 2538 | 1563 | 25.75 | 6592 | 605 |
| 8 | 13.32 | 3403 | 2316 | 40.56 | 10382 | 735 |
| 16 | 13.89 | 3549 | 4511 | 53.17 | 13613 | 1169 |
| 32 | 14.02 | 3579 | 8758 | 53.83 | 13780 | 2317 |
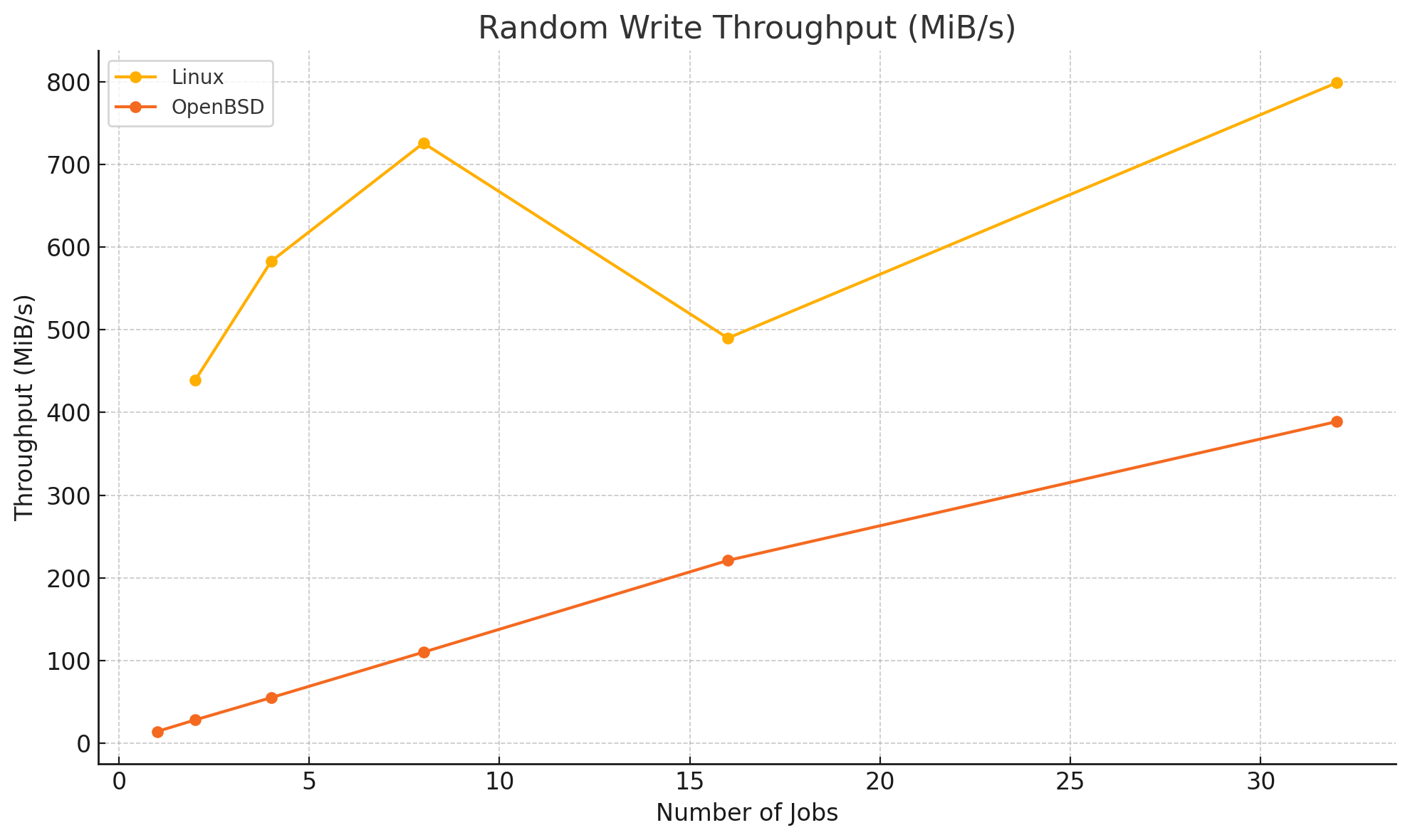
Throughput vs. Job Count (Random Write)
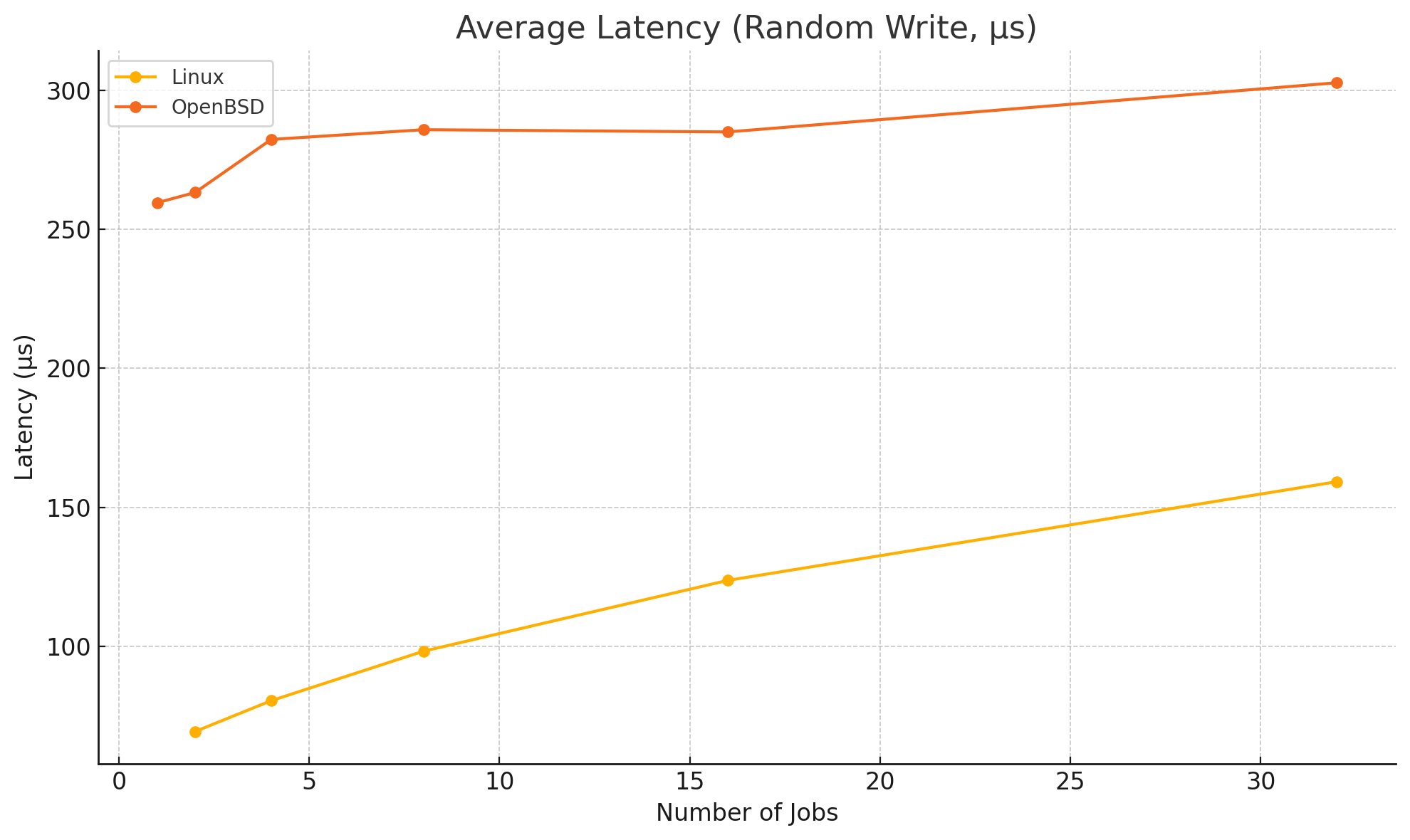
Average Write Latency
Please mind the gap. The test was not even performed with direct=1 (see below for details) under Linux. There is a lot of potential for OpenBSD.
direct=bool If value is true, use non-buffered I/O. This is usually O_DIRECT. Note that OpenBSD and ZFS on Solaris don't support direct I/O. On Windows the synchronous ioengines don't support direct I/O. Default: false.What I also noticed is that the performance on the ThinkPad damatically worse than on the workstation.
Conclusion #
If you’re tuning I/O performance on OpenBSD — whether for databases, file servers, or personal use — don’t fall into the “more jobs = more performance” trap. Our tests clearly show:
- 6 to 8 parallel jobs is optimal for both reads and writes.
- Beyond that, latency suffers and throughput gains are negligible.
I wanted to get a quick but solid overview of how well OpenBSD handles disk I/O across increasing thread counts. The results matched my expectations — scaling up works to a point, but there are trade-offs. What these benchmarks don’t show is that once the number of threads grows too large, my KDE desktop becomes almost unusable. This is something to keep in mind for real-world multitasking scenarios.
An upcoming test I plan to run will involve RW performance on USB sticks, which could offer more insight as we stress more subsystems.



